
Introduction
One field that has seen an extraordinary surge in growth and innovation in recent decades is Artificial Intelligence. From humanoid robots like Sophia, capable of mimicking human interactions, to renowned models like ChatGPT, known for its ability to comprehend and generate human-like text, and even Amazon’s voice-controlled virtual assistant, Alexa, integrated into Echo devices and other products – AI is truly transforming our world.
In this article, we will embark on a comprehensive journey into the realm of Computer Vision. We will explore what is computer vision, its modest origins, unravel the mechanics behind this fascinating technology, delve into the tasks of Computer Vision, and examine how leading brands harness its potential to propel their businesses forward. So let’s get started!
Also, check out our comprehensive guide that introduces you to Artificial Intelligence.
Table of Contents
Introduction
What is Computer Vision
History of Computer Vision
How does Computer Vision work
Key Features of Computer Vision
Computer Vision Tasks
How are Companies Leveraging Computer Vision
What is Computer Vision?
As you’re engrossed in reading this blog, whether it’s on your desktop, laptop, convenient tablet, or handy mobile device, you are able to analyze the device or tell its color. You are able to tell objects apart. Now imagine if machines could do that.
Computer Vision, or CV for short, is a subfield of Artificial Intelligence (AI) that facilitates computers and machines to analyze images and videos. Just like humans, these intelligent systems can make sense of visual data and extract valuable information from it.
This capability of Computer Vision finds applications across a wide array of industries. For instance, in healthcare, CV is instrumental in the field of medical imaging, aiding doctors and researchers in diagnosing and understanding complex medical conditions. In the automotive industry, Computer Vision plays a crucial role in enabling autonomous vehicles to “see” their surroundings, ensuring safe navigation on the roads.
In recent years, Computer Vision has made astonishing progress, which can be attributed to two key factors: advancements in deep learning and neural networks and the accessibility of vast amounts of visual data. These breakthroughs have propelled vision systems from a mere 50% accuracy level to an impressive 99% accuracy level in less than a decade. This remarkable improvement showcases the incredible potential of Computer Vision and its ability to push boundaries continually.
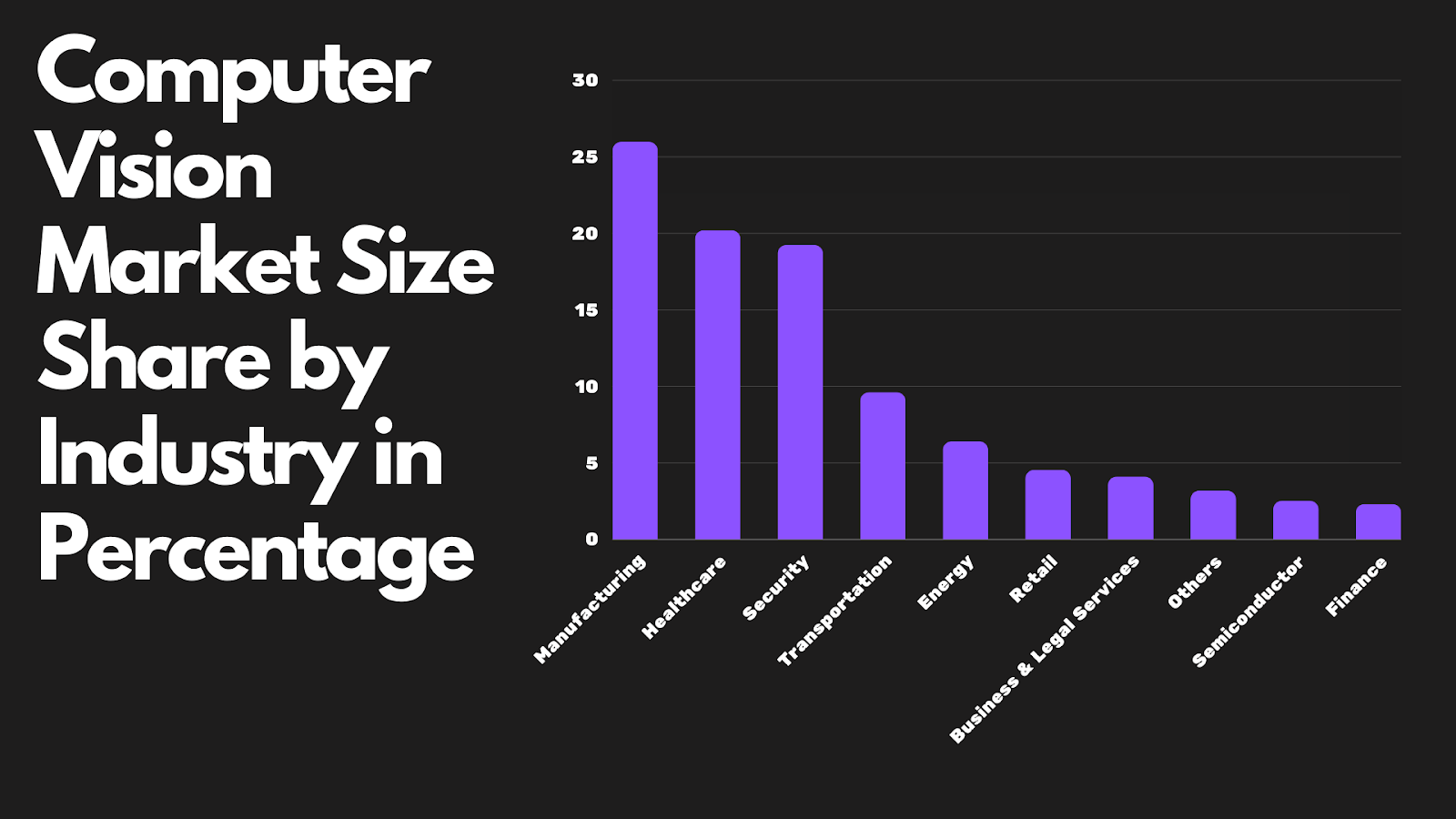
What’s even more exciting is that the growth of the Computer Vision market shows no signs of slowing down. In fact, it’s projected to reach a staggering $22.27 billion by the end of 2023. By 2028, it’s expected to skyrocket to an astonishing $50.97 billion, growing at a remarkable rate of 12.56% from 2023 to 2028. The United States stands at the forefront of this industry, with an estimated market value of $8.3 billion.
History of Computer Vision
Highlights
- 1950s – Recording neural activity
- 1963 – Attempt at deriving 3D representations from 2D images
- 1966 – Multiplayer neural networks
- 1979 – Necognitron – mimicking human visual system
Forms of Computer Vision date back to the 50s. The pioneering work of neurophysiologists David Hubel and Torsten Wiesel in the 1950s and 1960s involved presenting arrays of images to cats and monkeys while recording neural activity. They revealed fundamental principles of early visual processing in the brain. Their findings included the existence of neurons selectively responsive to specific visual features, hierarchical processing of information from simple to complex features, the concept of receptive fields, and orientation sensitivity. These discoveries set the stage for Computer Vision development by inspiring algorithms for edge detection, feature extraction, and hierarchical processing. Hubel and Wiesel’s research profoundly impacted our understanding of visual perception and the field of Computer Vision.
In the very same year, the first image digital scanner was invented. The digital scanner invented in 1959 was the VIDICON tube. It aided in building modern Computer Vision by converting optical images into electrical signals, enabling digitizing visual information. The VIDICON tube allowed for the capture and processing of images by computers, paving the way for Computer Vision applications like object recognition and pattern analysis. This technology marked a foundational step in the development of Computer Vision, which has since become integral to various industries and technologies, from facial recognition to autonomous vehicles and medical image analysis.
In 1963, Lawrence G. Roberts pioneered Computer Vision with the “Blockworld” program, an early attempt to derive 3D representations from 2D images. It employed edge detection and hypothesis testing to reconstruct 3D scenes from simple block structures, setting the foundation for key Computer Vision concepts. Roberts’ work highlighted the importance of edge detection, 3D reconstruction, and hypothesis-driven approaches, all central to modern Computer Vision. Today, Computer Vision systems can recognize and interpret diverse objects and scenes, with applications in autonomous vehicles, facial recognition, and medical imaging, owing much to the foundational principles set by Roberts in 1963.
In 1966, Marvin Minsky co-authored the book “Perceptrons” highlighting the limitations of single-layer neural networks in handling complex, non-linear data impacting Computer Vision. This work prompted a shift towards multilayer neural networks and renewed interest in the field. It influenced the development of more advanced neural network architectures and training techniques, laying the foundation for modern deep learning, which is now dominant in Computer Vision and AI. Minsky’s research illuminated the importance of overcoming limitations in early AI models, shaping the trajectory of Computer Vision research and the broader field of artificial intelligence.
In 1979, Kunihiko Fukushima unveiled the Neocognitron, a neural network design that reshaped the landscape of Computer Vision.

This innovative architecture mimicked the human visual system’s structure and function, featuring layers of artificial neurons like S-cells and C-cells. The Neocognitron excelled at local feature extraction, detecting intricate patterns and edges within images. Crucially, it introduced translation invariance, enabling it to recognize objects regardless of their position or orientation—a pivotal concept still in use today. Fukushima’s Neocognitron paved the way for advanced neural networks, notably Convolutional Neural Networks (CNNs), which dominate modern Computer Vision, powering applications from image recognition to object detection.
How does Computer Vision work?
Computer Vision facilitates computers to perceive and comprehend the visual world much like humans do. It involves various stages, beginning with capturing images or video frames through cameras or sensors. These raw visual inputs are then subjected to preprocessing techniques designed to enhance the overall quality and reliability of the data. Let us take a quick look at the different stages.
Feature Extraction
At the heart of Computer Vision lies a crucial step known as Feature Extraction. During this phase, the system scrutinizes the incoming visual data to identify and isolate significant visual elements, such as edges, shapes, textures, and patterns. These features are critical because they serve as the building blocks for the subsequent stages of analysis. To facilitate computer processing, these identified features are translated into numerical representations, effectively converting the visual information into a format that machines can comprehend and manipulate more efficiently.
Object Detection
Moving forward in the process, object detection and recognition play pivotal roles. Once the features are extracted and converted into numerical data, the system’s algorithms work to identify and locate specific objects or entities within the images. This enables computers to not only detect the presence of objects but also understand what those objects are, a capability that finds applications in fields ranging from autonomous vehicles identifying pedestrians to security systems recognizing intruders.
Image Classification
Image classification takes this level of comprehension to even greater heights.
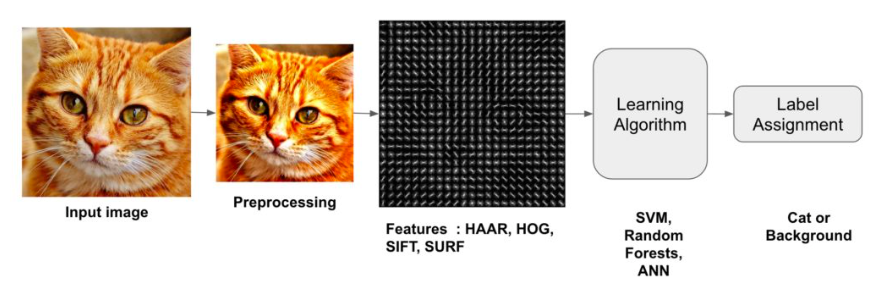
Rather than merely recognizing individual objects, image classification involves categorizing entire images into predefined classes or categories. This is where Convolutional Neural Networks (CNNs) come into play. CNNs are a specialized class of deep learning models designed explicitly for image-related tasks. They excel at learning complex hierarchies of features, which allows them to discern intricate patterns and make highly accurate image classifications.
Object Tracking
Object tracking is a fundamental technique in video analysis that plays a pivotal role. It involves the ability to monitor and trace the movement of objects as they traverse through consecutive frames of a video. This might seem like a straightforward task, but it’s an essential component in a wide range of applications, from surveillance and sports analytics to robotics and beyond.
Semantic Segmentation
If we delve even deeper into the realm of Computer Vision, we encounter a more intricate and powerful concept known as Semantic Segmentation.
This technique takes object analysis to a whole new level by meticulously labeling each and every pixel within an image with its respective category. Imagine looking at a photo and not only identifying objects but also understanding the boundaries and categories of each pixel within those objects. This level of granularity opens up a world of advanced possibilities, particularly in the field of autonomous navigation.

Semantic Segmentation
Autonomous navigation, such as that seen in self-driving cars and drones, relies heavily on semantic segmentation. It allows these vehicles to detect and recognize objects and have a detailed understanding of their surroundings. This understanding is vital for making real-time decisions and navigating safely through complex environments.
But the capabilities of Computer Vision don’t stop there. It has the ability to extract three-dimensional information from two-dimensional images, enabling the creation of 3D models and reconstructions. This feature has applications in fields like architecture, archaeology, and virtual reality, where the conversion of 2D images into 3D representations can provide invaluable insights.
Moreover, Computer Vision can perform post-processing tasks with remarkable precision. It can count objects in an image or estimate their sizes with incredible accuracy. Think about the potential this holds in inventory management, quality control in manufacturing, or even in monitoring wildlife populations in conservation efforts.
What makes Computer Vision even more fascinating is its adaptability. Through the power of machine learning, these systems can learn and evolve over time. They can become increasingly accurate and reliable as they process more data and gain more experience. This adaptability is what allows computer vision to continually push the boundaries of what’s possible in various industries and applications.
Looking to get started with Computer Vision? Check out our Free OpenCV Bootcamp.
Key Features of Computer Vision
In this section, we’ll delve into the key features defining Computer Vision’s fascinating realm.
Visual Perception
At its core, Computer Vision seeks to replicate the human ability to perceive and process visual information. It achieves this by capturing and comprehending images or video data from cameras and sensors. These systems act as the digital eyes that enable machines to “see” and make sense of their environment.
Image Understanding
One of the pivotal functions of Computer Vision is image understanding. Here, sophisticated algorithms and models come into play, working to dissect the content of images or video frames. This process involves recognizing a wide array of elements, from objects and scenes to people, and understanding their attributes and relationships within the visual context.
Pattern Recognition
Pattern recognition is at the heart of many Computer Vision tasks. Machines learn to discern recurring patterns or features in visual data. This encompasses the identification of shapes, textures, colors, and various intricate details that form the building blocks of our visual world.
Machine Learning and Deep Learning
At the core of Computer Vision lies machine learning and deep learning techniques. These cutting-edge technologies, including convolutional neural networks (CNNs), facilitate Computer Vision systems to learn and extract relevant features from visual data automatically. They are the driving force behind the remarkable advancements in this field.
The practical applications of Computer Vision span across a multitude of industries, making it a transformative force in today’s world. From healthcare’s critical medical image analysis to the automotive sector’s quest for autonomous driving, Computer Vision plays a pivotal role. It assists in retail through product recognition and recommendations, enhances agriculture by monitoring crops and predicting yields, strengthens security with surveillance and facial recognition, and adds a layer of immersive experiences in entertainment via augmented and virtual reality.
Multidisciplinary Character
Computer Vision is an exceptionally interdisciplinary field. It draws knowledge and inspiration from various disciplines, including computer science, machine learning, mathematics, neuroscience, psychology, and physics. This amalgamation of insights from various domains enables the creation of systems capable of understanding and interpreting visual data with remarkable precision.
Computer Vision Tasks
Now let us explore some important Computer Vision tasks.
Image Classification
At the core of Computer Vision lies image classification, a fundamental task that involves categorizing an input image into predefined classes or categories. Picture a system that can distinguish between a cat, a dog, or neither, simply by analyzing an image. This foundational capability is the bedrock for various other Computer Vision applications, paving the way for advanced visual recognition.
Object Detection
Moving beyond classification, object detection adds another layer of complexity. It identifies objects within an image and precisely pinpoints their location by drawing bounding boxes around them. Think of autonomous vehicles identifying pedestrians and other vehicles, security systems detecting intruders, or retail applications tracking products on store shelves. Object detection empowers machines to navigate and interact with the world more effectively.
Image Segmentation
Image segmentation is all about dissecting an image into distinct regions or segments based on shared characteristics like color, texture, or shape. This technique aids in understanding object boundaries and separating different objects or regions within an image. In the medical field, it helps segment organs or tumors, while in robotics, it assists in navigation and manipulation tasks.
Facial Recognition
Facial recognition is the art of identifying and verifying individuals based on their facial features. This technology has far-reaching applications, from enhancing security through authentication and access control to adding fun filters in entertainment and aiding law enforcement in identifying suspects from surveillance footage.
Pose Estimation
Pose estimation determines the spatial position and orientation of objects or body parts within images or videos. For example, it’s used in fitness tracking, gesture recognition, and gaming, allowing machines to understand the physical world and human movement in detail.

Sample skeleton output of Pose Estimation





Scene Understanding
Scene understanding goes beyond object recognition by extracting higher-level information from visual data. It encompasses recognizing the layout of a scene, understanding relationships between objects, and inferring the context of the environment. This capability is crucial in robotics, augmented reality, and smart cities for tasks like navigation, context-aware information overlay, and traffic management.
OCR
OCR, or Optical Character Recognition, is the remarkable ability to recognize and extract text from images or scanned documents. It plays a pivotal role in digitizing printed or handwritten text, making it searchable and editable. Applications range from document management to text translation and accessibility tools for visually impaired individuals.
Image Generation
While not strictly about recognition, Computer Vision also facilitates image generation and manipulation. Generative models like GANs (Generative Adversarial Networks) can create realistic images, opening doors to artistic expression, content generation, and data augmentation for training machine learning models.
These are just some of the many Computer Vision tasks, and numerous variations and combinations exist to solve complex real-world problems. Driven by advancements in deep learning and neural networks, Computer Vision enables machines to interpret and interact with the visual world in sophisticated ways.
How are companies leveraging Computer Vision
In today’s rapidly evolving technological landscape, businesses are increasingly turning to Computer Vision to gain a competitive edge. However, deploying Computer Vision solutions often presents a significant challenge, requiring extensive effort from computer vision engineers, developers, and data scientists. Let us look at how some of the top companies are achieving this by leveraging Computer Vision.
Intel
Intel Corporation, often referred to simply as Intel, is a prominent American multinational technology firm renowned for its expertise in crafting semiconductor chips, microprocessors, and various hardware components for computers and electronic devices. Established in 1968, Intel has been a pivotal player in shaping the contemporary computer industry, celebrated for its pioneering advancements in CPU (Central Processing Unit) technology. Intel’s processors enjoy widespread adoption in personal computers, servers, and various other computing devices.
Intel offers a comprehensive suite of tools and resources designed to assist businesses in harnessing the power of Computer Vision. Let us explore a few of them.
End-to-End AI Pipeline Software
One of the key hurdles in deploying Computer Vision solutions is the complexity involved in model development and deployment. Intel recognizes this challenge and has developed end-to-end AI pipeline software to streamline the entire process. This software is equipped with optimizations tailored for popular frameworks like TensorFlow, PyTorch, and scikit-learn, ensuring that vision engineers can work efficiently and optimize performance. One of the most comprehensive tools for this is Roboflow, which is used by over 1 million engineers to create datasets, train models, and deploy to production.
Intel Distribution
For businesses seeking to simplify deployment further, Intel provides the Intel Distribution of OpenVINO toolkit. This powerful tool allows teams to write AI solution code once and deploy it virtually anywhere. What makes OpenVINO particularly valuable is its open-source nature, which enables you to avoid vendor lock-in. This flexibility allows you to build applications that seamlessly scale across various hardware platforms, from edge devices to the cloud.
Intel Geti
Intel recognizes that AI model development is not limited to coders alone. To bridge the gap between domain experts and data scientists, Intel has introduced Intel Geti, an open-source, enterprise-class Computer Vision platform. This innovative platform empowers non-coders to collaborate effectively with data scientists, speeding up the process of building and training AI models.

Hardware Portfolio for Diverse Needs
Intel understands that different Computer Vision applications have varying hardware requirements. To address this, they offer a broad hardware portfolio that provides the processing power needed for deploying Computer Vision in diverse environments. Whether you require AI models to run on drones or other edge devices, Intel’s hardware options have you covered.
Open Source Tools for Scalability
Intel’s commitment to open source extends to its software tools. Developers and data scientists can leverage open-source solutions like the Intel Distribution of OpenVINO toolkit to develop and optimize applications that can seamlessly scale across a wide range of heterogeneous devices. With just a few code adjustments, you can adapt a Computer Vision AI model trained on deep learning accelerators to run efficiently on a drone or any other platform.
Intel offers a comprehensive suite of hardware and software tools that empower businesses to harness the full potential of Computer Vision, from simplifying model development and deployment to providing a diverse hardware portfolio and open-source solutions. With Intel’s AI Computer Vision platform, businesses can confidently navigate every aspect of the AI pipeline, ultimately driving performance and accelerating return on investment.
Nvidia
Artificial Intelligence (AI) is ushering in a new era of business transformation, but its rapid integration presents significant challenges. For enterprises, maintaining a secure and stable software platform for AI is a complex task.
To address these concerns, NVIDIA has introduced NVIDIA AI Enterprise. This cloud-native software platform streamlines the development and deployment of AI applications, including generative AI, Computer Vision, and speech AI. This platform offers critical benefits for businesses relying on AI, such as improved productivity, reduced AI infrastructure costs, and a smooth transition from pilot to production.
NVIDIA Maxine
NVIDIA AI Enterprise also constitutes NVIDIA Maxine, exclusively for production workflows.
In an era where virtual meetings have become the norm, video conferencing quality has taken center stage. NVIDIA Maxine, a cutting-edge suite of GPU-accelerated AI technologies, has stepped up to the plate to transform communication through Computer Vision.
Maxine is a comprehensive software library, including AI solution workflows, frameworks, pre-trained models, and infrastructure optimization. Maxine is designed to enhance audio and video quality in real-time, adding augmented reality effects. It achieves impressive results with standard microphone and camera equipment and is deployable on-premises, in the cloud, or at the edge.

Let us explore how Maxine leverages Computer Vision to revolutionize the video conferencing experience.
One of Maxine’s standout features is its ability to remove or replace backgrounds during video calls effortlessly. Thanks to Computer Vision, you can now join meetings from virtually anywhere without the need for a green screen. Whether you want to project a professional image or add a touch of whimsy with virtual backgrounds, Maxine makes it possible. Let us look at some of the features of Maxine.
- Facial Enhancement: Maxine uses Computer Vision for real-time facial alignment and beautification, ensuring a polished appearance on video calls.
- Crystal-Clear Audio: Maxine excels in audio enhancement, efficiently removing background noise for pristine, noise-free audio.
- Gaze Correction: Maxine adjusts gaze direction using Computer Vision, simulating eye contact and enhancing natural interaction.
- Super-Resolution: Maxine employs AI to upscale and enhance low-resolution videos for sharper, detailed quality.
- Gesture and Emotion Recognition: Maxine recognizes gestures and emotions through Computer Vision, fostering interactive experiences.
- Speech Enhancement: Maxine reduces echo and eliminates background noise, ensuring crystal-clear speech in virtual meetings.
- Language Translation: Maxine offers real-time language translation for seamless communication in international meetings.
By providing a comprehensive ecosystem for AI development and deployment, NVIDIA empowers businesses to unlock the full potential of AI.
Qualcomm
Qualcomm’s Vision Intelligence Platform is reshaping the landscape of Computer Vision in both consumer and enterprise IoT domains. This powerful platform seamlessly combines image processing with advanced Artificial Intelligence (AI) capabilities, elevating the performance of smart camera products across a spectrum of IoT devices. From enterprise and security cameras to industrial and home monitoring cameras, Qualcomm’s platform is a driving force behind the integration of on-device vision AI in applications spanning security, retail, manufacturing, logistics, and more.
One example is the iOnRoad application, which earned recognition with a CES Award for Design and Engineering. This accolade from the Consumer Electronics Association (CEA) underscores the platform’s innovative use of Computer Vision technology. CV harnesses video input and high-speed computation to identify shapes within a given field of view. In the case of iOnRoad, CV is ingeniously combined with a mobile phone camera to detect nearby objects precisely.
Here are a few technical highlights of Qualcomm’s Vision Intelligence Platform that further illustrate its capabilities.
Here are a few technical highlights of Qualcomm’s Vision Intelligence Platform that further illustrate its capabilities.
- FastCV for Snapdragon: This platform leverages FastCV. This robust tool enhances image processing and machine learning capabilities, thereby making Snapdragon processors even more adept at handling complex Computer Vision tasks.
- Qualcomm’s commitment to excellence is evident in the 10-15% overall performance increase, ensuring seamless and efficient operation of smart camera products.
- Image conversion speed is crucial in Computer Vision applications. Qualcomm’s platform excels in this aspect by offering a 30% increase in the conversion speed of YUV420 images to RGB format.

Beyond the technical marvels, Qualcomm’s Vision Intelligence Platform brings substantial business advantages to the table:
- Qualcomm’s Vision Intelligence Platform offers easy integration for Computer Vision, making it accessible and uncomplicated.
- It extends Computer Vision capabilities to sub-1GHz processors, expanding possibilities for middle-tier devices.
- The platform revolutionizes IoT devices with advanced image processing and AI, simplifying integration and transforming industries.
Meta
Meta, formerly Facebook, is leveraging Computer Vision across its platforms and products to create more immersive experiences and enhance user safety. Here’s a concise breakdown of how Meta leverages Computer Vision.
- Content Moderation: Meta uses Computer Vision to identify and remove prohibited content from its platforms automatically.
- Image Recognition: Computer Vision tags individuals in photos and videos for easier photo tagging.
- Augmented Reality (AR): CV overlays digital objects onto the real world for immersive AR experiences.
- Ad Targeting: It analyzes visual content for relevant ad targeting.
- Accessibility: CV generates alt text for images to aid visually impaired users.
- Marketplace and Shopping: It categorizes and suggests listings in Meta Marketplace.
- Virtual Reality (VR): CV enables hand tracking in VR environments.
- Safety Features: It detects self-harming content and provides support resources.
- Language Translation: Computer Vision translates text within images to break language barriers.
- Enhanced Video Understanding: CV improves video recommendations by analyzing video content.
Earlier this year, Meta took a significant stride in the realm of Computer Vision by introducing FACET (FAirness in Computer Vision EvaluaTion), setting a benchmark in AI. This innovative tool is designed to evaluate the fairness of AI models when it comes to classifying and detecting objects and individuals in photos and videos.

FACET is built upon a vast dataset comprising 32,000 images featuring 50,000 individuals, annotated by vision engineers. These images span various demographic attributes, occupations, and activities. The goal is to delve deep into the potential biases that might exist within AI models.
One of Meta’s key objectives is to encourage the broader research community to leverage FACET to scrutinize the fairness of vision and multimodal AI tasks. By doing so, developers can gain valuable insights into any biases present in their AI models and work towards mitigating them.
Meta’s introduction of the FACET benchmark represents a huge stride toward fostering transparent fairness evaluation.
Sony
Sony Semiconductor is at the forefront of revolutionizing Computer Vision. Their approach involves leveraging the power of raw data and pixels right at the source, in order to send only the most relevant information to AI systems upstream. This innovative technique, reminiscent of the Internet of Things (IoT) model, alleviates the burden on internet bandwidth and reduces the strain on GPUs, traditionally responsible for image processing.
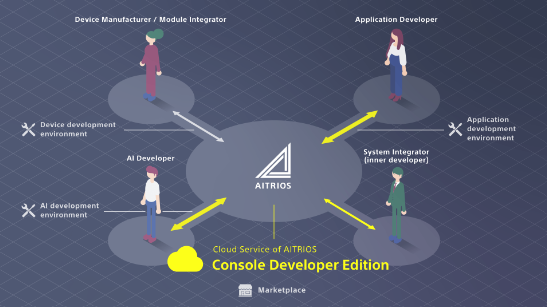
Sony’s vision for the future is clear – they aim to go beyond merely analyzing full images and instead delve into the granularity of individual pixels within cameras themselves. This is made possible with Aitrios, Sony’s full-stack AI solution for enterprises, comprising an AI camera, a machine-learning model, and a suite of development tools.
Mark Hanson, Vice President of Technology and Business Innovation at Sony Semiconductor, emphasizes the importance of accurate data over aesthetically pleasing data for AI applications. He points out that interpreting individual pixels plays a pivotal role in this endeavor. Let us explore some of the stages in Sony Stack.
Highlights
- Sony stack – using logic chips to optimize pixel structures
- Detecting objects once sensors capture the image
- Processing image data
- Data flows into larger trained models within cloud services
- The heart of this breakthrough is the Sony stack, which is equipped with AI cameras known as IMX500 and IMX501, which process data differently to cater to AI needs. Sony employs logic chips that optimize pixel structures, enhancing their sensitivity by allowing more light to be exposed. These logic chips also handle AI computations, eliminating the need for data to traverse through bus structures to GPUs or CPUs.
- As soon as the sensor captures an image, it undergoes processing within milliseconds. The output can manifest as detecting objects like people, animals, or human poses, conveyed as text strings or metadata.
- Aitrios incorporates core technology that facilitates AI models, including cutting-edge TinyML for deep learning on microcontrollers at the edge. Sony takes it a step further by enabling direct integration of image-collecting sensors with cloud models. This integration, akin to how 5G cells and various sensors feed data into cloud services, is part of a collaboration with Microsoft. These sensors are poised to become endpoints for processing imaging data right at the edge.
- The processed data can seamlessly flow into larger trained models within cloud services like Azure, offering access to custom or synthetic datasets for AI training models. An intuitive Aitrios console serves as the interface for managing camera technology. It handles tasks such as searching for cameras, downloading firmware, managing updates, and deploying AI models from the marketplace to the cameras.
The applications of Sony’s Aitrios technology are diverse and promising. In retail settings, it can be employed to determine product availability on shelves, optimize customer traffic flow, and identify areas vulnerable to theft, thereby enhancing security.
Sony’s Aitrios represents a remarkable leap forward in Vision technology. This innovative approach conserves bandwidth and empowers AI systems with more accurate and granular information by analyzing data and pixels at the edge, with applications spanning various industries.
Conclusion
In this read, we’ve looked at what Computer Vision is, its mechanics, some common CV tasks, and how companies like Sony and Qualcomm are implementing it. This read shed light on the significance of Computer Vision in AI. Continued advancements in Computer Vision will undoubtedly play an integral role in a wide range of industries, offering numerous opportunities for innovation and growth. Stay tuned! More insightful readings are coming your way.



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning