
Nowadays, many ground-breaking solutions based on neural network are developed daily and more people are adopting this technique for solving problems such as voice recognitions in their life. Because of the recent advancement in computing and the growing trend of using neural networks in a production environment, there is a significant focus of having such solution running in a large production setting, ideally also in real-time at the “edge”.
Imagine that you have a well-trained neural network written in PyTorch. What can you do to speed up the inference step on a CPU, a VPU, a integrated graphics, an FPGA, or in a combination of such? Fortunately, without significant re-architecting and rewriting any of the source code, one now can easily speed up the performance of the inference step using the Inference Engine provided by Intel’s OpenVINO Toolkits. In many cases, you get a considerable performance increase without hugely scarifying the inference accuracy. Additionally, the model conversion procedure is simple and fast. Spoiler alert: in our example, we have accelerated the inference step by approximately 2.2 times!
Refer to https://software.intel.com/articles/optimization-notice for more information regarding performance and optimization choices in Intel software products.
So what is this OpenVINO Toolkit?
Open Visual Inference & Neural Network Optimization (OpenVINO) toolkit is a set of libraries, optimization tools, and information resources facilitating the development of Computer Vision and Deep Learning software. You can rely on it when you want to maximize performance
or optimize your application for Intel platforms. So what’s inside the OpenVINO Toolkit?
- Model Optimizer – a command-line tool to adjust the network for optimal execution using static model analysis. The outcome of Model Optimizer is Intermediate Representation (IR) that is ready to be launched with the Inference Engine.
- Inference Engine – an API to read IR, set input and output, and do inference on a chosen device.
- OpenCV, OpenCL, OpenVX, and Intel Media SDK.
You can find more info here: https://docs.openvinotoolkit.org/.
Overview
To demonstrate how it all works, we will select an interesting and relevant model and take the following steps:
- Prepare the environment.
- Train a model using PyTorch (or use a pre-trained model)
- Convert the PyTorch model to ONNX format.
- Using Model Optimizer, convert the model from ONNX to Intermediate Representation (IR) format.
- Do the inference using Inference Engine and compare performance and results.
All source code from this article is available on GitHub.
1. Prepare the environment
- Install Python 3.6 or 3.7 and run:
python3 -m pip install -r requirements.txt
requirements.txt contents:
torch numpy onnx networkx
- Install OpenVINO tookit version 2020.1 or later using the official instruction.
The code was tested against the specified versions. But it’s okay to try to launch it on other versions if you have some of those components already installed.
2. Run the inference in PyTorch
We chose FaceMesh model to conduct our experiments. We will take advantage of a ready and trained implementation.
The model expects a cropped face as an input, so we’ll also need a face detector. The good news is that Intel has already converted the face detector to IR and put it in the Open Model Zoo. The Open Model Zoo contains a lot of models, including text detection and recognition, pose estimation, segmentation, person identification, etc. And all of them are already optimized for the Inference Engine and can be use right out-of-the-box.
To make a fair comparison, we will re-create the pre-processing step of our pipeline using the face detection model in PyTorch that we will convert to OpenVINO ourselves.
For this task, we will use the BlazeFace model implemented here. As the first step, let’s create and run an inference script:
import cv2
from facemesh import FaceMesh
from blazeface import BlazeFace
# load FaceMesh model
mesh_net = FaceMesh()
mesh_net.load_weights("facemesh.pth")
# load BlazeFace model
blaze_net = BlazeFace()
blaze_net.load_weights("blazeface.pth")
blaze_net.load_anchors("anchors.npy")
# postprocessing for face detector
def get_crop_face(detections, image):
w, h = image.shape[0], image.shape[1]
ymin = int(detections[0, 0] * w)
xmin = int(detections[0, 1] * h)
ymax = int(detections[0, 2] * w)
xmax = int(detections[0, 3] * h)
margin_x = int(0.25 * (xmax - xmin))
margin_y = int(0.25 * (ymax - ymin))
ymin -= margin_y
ymax += margin_y
xmin -= margin_x
xmax += margin_x
face_img = image[ymin:ymax, xmin:xmax]
face_img = cv2.cvtColor(face_img, cv2.COLOR_BGR2RGB)
image = cv2.rectangle(image, (xmin, ymin), (xmax, ymax), (0, 0, 255), 2)
return xmin, ymin, face_img
# postprocessing for mesh
def get_mesh_face(detections, face_img, image, xmin, ymin):
xscale, yscale = 192 / face_img.shape[1], 192 / face_img.shape[0]
for i in range(detections.shape[0]):
x, y = int(detections[i, 0] / xscale), int(detections[i, 1] / yscale)
image = cv2.circle(image, (xmin + x, ymin + y), 1, (255, 0, 0), 1)
videoCapture = cv2.VideoCapture(0)
while True:
ret, image = videoCapture.read()
if not ret:
break
# preprocess image
face_img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
face_img = cv2.resize(face_img, (128, 128))
# get face detection boxes
detections = blaze_net.predict_on_image(face_img).numpy()
xmin, ymin, face_img = get_crop_face(detections, image)
# get face mesh
mesh_img = cv2.resize(face_img, (192, 192))
detections = mesh_net.predict_on_image(mesh_img).numpy()
get_mesh_face(detections, face_img, image, xmin, ymin)
# show processed image
cv2.imshow("capture", image)
if cv2.waitKey(3) & 0xFF == 27:
break
The result looks good! What do you think?
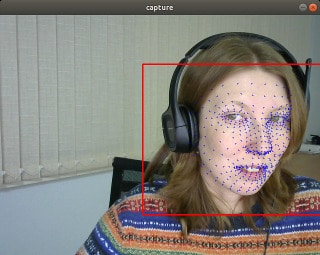
The FaceMesh results with PyTorch. Notice a mesh is drawn on the recognized face from the scene with the features aligned.
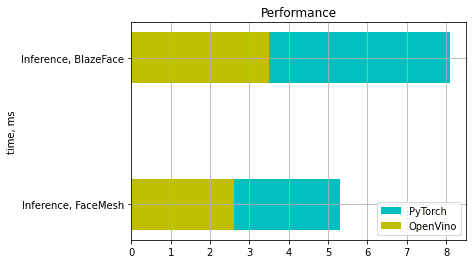
Now let’s measure the performance. We got 5.3 ms for FaceMesh and 8.1 ms for BlazeFace.
We measure and compare only the inference time.
Measurements were made in the following environment: Ubuntu 18.04.3, Intel® Core™ i7-8700 CPU @ 3.20GHz.
3. Convert the PyTorch model to ONNX format
ONNX (Open Neural Network Exchange) it is an open format built to represent models from different frameworks.
To convert the PyTorch model, you need the torch.onnx.export function which requires the following arguments: the pre-trained model itself, a tensor with the same size as input data, the name of ONNX file, and input and output names.
net = BlazeFace()
net.load_weights("blazeface.pth")
torch.onnx.export(net, torch.randn(1, 3, 128, 128, device='cpu'), "blazeface.onnx",
input_names=("image", ), output_names=("preds", "confs"), opset_version=9
)
net = FaceMesh()
net.load_weights("facemesh.pth")
torch.onnx.export(net, torch.randn(1, 3, 192, 192, device='cpu'), "facemesh.onnx",
input_names=("image", ), output_names=("preds", "confs"), opset_version=9
)
To check that if the model is converted successfully, we call the onnx.checker.check_model function as the following:
onnx_model = onnx.load(ONNX_FILE_PATH) onnx.checker.check_model(onnx_model)
You can find the list of supported operations here and it is constantly expanding.
4. Convert the model from ONNX to Intermediate Representation
It’s time to launch the Model Optimizer. In our case we will convert the model from ONNX, but this is not the only supported format.
If you have models in Caffe, TensorFlow, MXNet or Kald, you can use them too.
Before you can start working with the OpenVino toolkit, you should always activate OpenVINO environment by command:
source <path_to_openvino>/bin/setupvars.sh
If everything went well, you will see:
[setupvars.sh] OpenVINO environment initialized
Run the conversion:



python3 <path_to_openvino>/deployment_tools/model_optimizer/mo.py --input_model [facemesh or blazeface].onnx
As a result, you will get two files which describes the optimized version of your model:
– *.xml – contains info about network topology
– *.bin – contains weights
Unfortunately, not all ONNX layers are supported. A list of supported layers can be found here.
5. Run the inference using Inference Engine
To run inference using OpenVino we have to initialize and load the network in IR, prepare input data and call infer function.
Then we can get an interpretation of the results. So the minimum script will look like this:
from openvino.inference_engine import IECore
from openvino.inference_engine import IENetwork
ie = IECore()
net = IENetwork(model=model_path_xml, weights=model_path_bin)
exec_net = ie.load_network(network=net, device_name="CPU")
input_blob = next(iter(net.inputs))
result = exec_net.infer({input_blob: preprocessed_image})
In our specific example, we should look at how preprocessing is done for FaceMesh and BlazeFace using PyTorch and repeat it using OpenCV function cv2.dnn.blobFromImage. We need to reproduce postprocessing as well. For FaceMesh it’s pretty easy (see the code below), but for BlazeFace we have to re-implement such operations as IOU, NMS, etc. For this purpose, we can take the blazeface.py script and replace the operations with PyTorch tensors with the corresponding operations with Numpy arrays.
The final script will look like this:
import cv2
import numpy as np
from openvino.inference_engine import IECore
from openvino.inference_engine import IENetwork
from blazeface import BlazeFace
def load_to_IE(model):
# Loading the Inference Engine API
ie = IECore()
# Loading IR files
net = IENetwork(model=model + ".xml", weights=model + ".bin")
# Loading the network to the inference engine
exec_net = ie.load_network(network=net, device_name="CPU")
return exec_net
def do_inference(exec_net, image):
input_blob = next(iter(exec_net.inputs))
return exec_net.infer({input_blob: image})
# load BlazeFace model
blaze_net = load_to_IE("model/blazeface")
# load FaceMesh model
mesh_net = load_to_IE("model/facemesh")
# we need dynamically generated key for fetching output tensor
blaze_outputs = list(blaze_net.outputs.keys())
mesh_outputs = list(mesh_net.outputs.keys())
# to reuse postprocessing from BlazeFace
blazenet = BlazeFace()
blazenet.load_anchors("anchors.npy")
videoCapture = cv2.VideoCapture(0)
while True:
ret, image = videoCapture.read()
if not ret:
break
# get face detection boxes------------------------------------------------------------------
# preprocessing
face_img = cv2.dnn.blobFromImage(image, 1./127.5, (128, 128), (1, 1, 1), True)
# inference
output = do_inference(blaze_net, image=face_img)
# postprocessing
boxes = output[blaze_outputs[0]]
confidences = output[blaze_outputs[1]]
detections = blazenet._tensors_to_detections(boxes, confidences, blazenet.anchors)
detections = np.squeeze(detections, axis=0)
# take boxes
xmin, ymin, face_img = get_crop_face(detections, image)
# get face mesh ----------------------------------------------------------------------------
# preprocessing
mesh_img = cv2.dnn.blobFromImage(face_img, 1./127.5, (192, 192), (1, 1, 1), True)
#inference
output = do_inference(mesh_net, image=mesh_img)
# postprocessing
detections = output[mesh_outputs[1]].reshape(-1, 3)
# take mesh
get_mesh_face(detections, face_img, image, xmin, ymin)
# show processed image
cv2.imshow("capture", image)
if cv2.waitKey(3) & 0xFF == 27:
break

For users looking to take full advantage of Intel® Distribution of OpenVINO™ toolkit’s performance and features, it is recommended to follow the native workflow of using the Intermediate Representation from the Model Optimizer as input to the Inference Engine.
For users looking to rapidly get up and running with a trained model already in ONNX format (e.g., PyTorch), they are now able to input that ONNX model directly to the Inference Engine to run models on Intel architecture.
Let’s check the results and make sure that they match the previously obtained results in PyTorch.
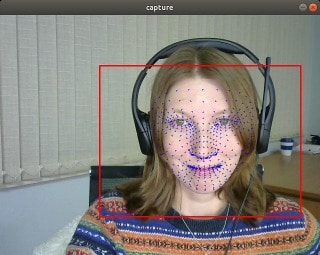
Compare the performance
Let’s measure the performance. We got 2.6ms for FaceMesh and 3.5ms for BlazeFace.
In total, we received an approximately 2.2x speedup with our setup.
Refer to https://software.intel.com/articles/optimization-notice for more information regarding performance and optimization choices in Intel software products.
Summary and Final Thoughts
Today, we studied how to convert a model into IR, and which models can be converted. We achieved a fruitful(~2.2) acceleration without a noticeable loss in the quality of the prediction. Most importantly, we achieved these results with the same Intel hardware without significant rewriting or redesigning of our solutions. Basically, we literally got the ‘speed-up’ for free!
Refer to https://software.intel.com/articles/optimization-notice for more information regarding performance and optimization choices in Intel software products.
Testing date: September 21, 2020
Complete system configuration details: Ubuntu 18.04.3, Intel® Core™ i7-8700 CPU @ 3.20GHz × 12
Setup details: OpenVINO toolkit version 2020.1
Who did testing: Julia Bareeva, OpenCV.AI
Get the Intel® Distribution of OpenVINO™ toolkit
Contribute – If you have any ideas in ways we can improve the product, we welcome contributions to the open-sourced OpenVINO™ toolkit.
Want to learn more? Join the conversation to discuss all things Deep Learning and OpenVINO™ toolkit in Intel’s community forum.
Intel is committed to respecting human rights and avoiding complicity in human rights abuses. See Intel’s Global Human Rights Principles. Intel’s products and software are intended only to be used in applications that do not cause or contribute to a violation of an internationally recognized human right.
Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries.
OpenCV Content Partnership
This article was written by a member of the OpenCV team for Intel as part of OpenCV Content Partnership Program. This program allows companies to sponsor articles that are relevant to OpenCV users. The articles are shared with our newsletter subscribers and our social media subscribers.



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning