

“Can machines think?” With this challenging question, Alan Turing, often dubbed the father of modern artificial intelligence, set on a profound journey to unravel the mysteries of machine cognition. Born when computing was in its infancy, Turing was a visionary who foresaw a world where machines would one-day rival human intelligence. His groundbreaking work laid the foundation for the digital revolution, and his conceptual framework gave rise to an entire field of study dedicated to understanding the potential and limits of artificial minds. This article takes us through the rich and varied history of AI.
Navigating the AI Journey: A Roadmap
The narrative of the history of AI is thoughtfully structured to offer you a complete understanding of AI pre and post the Deep learning era. We will commence by tracing the origins of AI and later explore the complex webs of neural networks, touching upon their earliest versions. We will then discuss the phase where classical machine learning techniques reigned supreme, offering insights into their dominance and contributions.
When Did AI Begin? Origins of Artificial Intelligence
The concept of inanimate objects coming to life has been part of ancient tales, from Greek myths of automatons to Jewish folklore’s golems. Yet, the scientific quest to make machines “think” began much more recently. But first, let’s briefly look at the most important periods in the history of AI.
Alan Turing and Modern Computing
During the 1940s, Turing, introduced the idea of a “universal machine” capable of mimicking any computation. His “Turing Test“, introduced in 1950, became the gold standard for judging machine intelligence.

The Dartmouth Workshop
In 1956, the term “Artificial Intelligence” emerged from a meeting of brilliant minds, including John McCarthy and Marvin Minsky. This event solidified the belief that machine intelligence could, in principle, be defined and achieved.
Logic-Based Systems
Newell and Simon’s early programs, like the Logic Theorist, believed intelligence could be created using symbols and rules.
Neural Networks
Rosenblatt’s perceptron in the 1950s was a precursor to machine learning. However, its limitations, highlighted by Minsky and Papert, briefly hindered enthusiasm in this area.
Rule-Based Expert Systems
In the 1970s and 80s, AI gravitated towards expert systems, with DENDRAL and MYCIN leading the way in replicating human decision-making.
Despite AI’s highs and lows in funding and attention, the drive to address Turing’s pivotal question persisted, priming the world for 21st-century innovations.
As the 20th century progressed, various AI techniques and paradigms emerged, from genetic algorithms to fuzzy systems. However, each carried its own set of limitations. The pursuit of true machine intelligence continued, and while AI experienced periods of reduced funding and interest, often termed “AI winters,” the seeds had been sown. The quest to answer Turing’s originative question pressed on, setting the stage for the transformative advancements of the 21st century.
The Enigma of the Neural Network
When we think of the human brain, we are often amazed at its ability to process information, make connections, and generate insights. This complex network of neurons, synapses, and electrical impulses serves as a beacon of nature’s prowess. And naturally, when scientists sought to replicate intelligence, they turned to this intricate system for inspiration. Enter the realm of neural networks in artificial intelligence.
A neural network is a computational model inspired by how biological neural systems process information. At its heart, a neural network aims to recognize patterns, much like our brains do. From recognizing the face of a loved one in a photograph to understanding spoken words in a noisy café, our brains perform these tasks seamlessly. Neural networks aspire to bring a similar flair to machines.
What Was The First Artificial Neural Network Like?
The story of the artificial neural network begins with an idea called the “perceptron.” The perceptron, in essence, was a simplified model of a biological neuron. It took in multiple binary inputs, processed them, and then produced a single binary output. The beauty of the perceptron lies in its ability to “learn” and adjust its parameters to get closer to the correct output.
Imagine a decision-making device trying to classify whether a fruit is an apple or an orange based on attributes like color and size. If it misclassifies, it tweaks its internal parameters, slightly shifting its judgment criteria, and tries again. Over time, with enough examples, it gets better and more accurate at this task.
However, the perceptron had its limitations. While it was a breakthrough in its time, it could only handle linearly separable data. This means if you were to plot data points, the perceptron could only distinguish between categories if a straight line could separate them. More complex, intertwined data was beyond its reach. This limitation, highlighted by Marvin Minsky and Seymour Papert in the late 1960s, led to a temporary wane in enthusiasm around neural networks.
Dive deep into the realm of Artificial Intelligence with our curated selection of FREE courses.
Whether you’re passionate about Computer Vision, Python, or deep learning, our beginner bootcamps are your launchpad. Start your AI journey now!
Why are Neural Networks Pivotal to AI?
The importance of neural networks to AI is similar to the importance of the foundation of a building. Without a solid foundation, it would crumble. Similarly, without neural networks, many of the advanced AI capabilities we see today would remain a dream.
Neural networks, especially when they evolved into deeper architectures known as deep learning, provided a framework for machines to understand, generate, and classify complex patterns in vast amounts of data. Every interaction, every search, every image, and video carries layers of patterns and details that traditional algorithms struggled with.
As AI continues to evolve, the neural network becomes better at replicating the marvel of the human brain. It paves the way for a future where machines can truly ‘think’ and ‘learn’ what was earlier considered the exclusive domain of humans.
From Neural Networks to Classical Machine Learning: The Evolutionary Shift
While neural networks provided a foundation, the challenges of the 1960s and 1970s—such as the perceptron’s limitations—steered the field towards alternative avenues. This shift led researchers to explore a range of algorithms and strategies collectively called classical machine learning.
Why the Shift?
1. Computational Constraints: As mentioned earlier, the sheer computational requirements of deep neural networks were beyond the capabilities of most available hardware until the early 2010s. In contrast, classical techniques were often more computationally efficient and could run on standard hardware, making them more accessible for practical applications.
2. Transparency & Interpretability: Industries like finance and healthcare prioritized models where decisions could be explained and justified. Classical algorithms, especially decision trees or linear regression, offered this interpretability. The decisions of a neural network, with its thousands or even millions of parameters, were more opaque.
3. Limited Data Availability: Deep learning models are often described as ‘data hungry’. The digital explosion that is now providing vast datasets wasn’t as pronounced before the 2010s. Classical techniques often performed well with smaller datasets, making them suitable for the data environments of the time.
4. Mature Toolkits & Libraries: By the 2000s, software libraries catering to classical machine learning, like `scikit-learn` for Python, were mature and well-documented, allowing researchers and practitioners to implement these techniques with relative ease.
5. Diverse Problems, Diverse Solutions: Not all problems require the power of neural networks. For many tasks, classical techniques provided satisfactory or even state-of-the-art results. This versatility made them the go-to tools in many domains.
6. Perceptron’s Limitations: The perceptron’s inability to handle non-linearly separable data—highlighted prominently by Minsky and Papert—caused a dampening of enthusiasm around neural networks.
Advancements of Classical Machine Learning
Decision Trees: These are tree-like models used for decision-making. At every tree node, a decision is made that branches out further, making them interpretable and transparent. Algorithms like ID3 or C4.5 became popular methods for creating decision trees.
Support Vector Machines (SVM): Introduced in the 1990s, SVMs became a powerful tool for classification tasks. They worked by finding a hyperplane (or a line in 2D space) that best divided data into classes. SVMs had the ability to handle non-linear data by transforming it into a higher-dimensional space.
Bayesian Networks: These probabilistic graphical models represent a set of variables and their conditional dependencies via a directed acyclic graph. They provided a structured, visual method to handle uncertainty in data.
K-means Clustering: An unsupervised learning algorithm, K-means was designed to classify unlabeled data into distinct clusters based on similarity.
Ensemble Methods: Techniques like Bagging and Boosting combine multiple models to improve performance. For instance, the Random Forest algorithm uses an ensemble of decision trees to make more accurate predictions.
Why Classical Machine Learning Mattered
Versatility: These techniques were flexible and could be applied to a wide range of tasks—from classification to regression to clustering.
Efficiency: Given the computational constraints of the era, many classical algorithms were more efficient and scalable than deep neural networks.
Foundation for Modern AI: The understanding and principles developed during this period laid the groundwork for many modern advancements. Concepts like bias-variance tradeoff, overfitting, and regularization, integral to today’s AI, were refined during this era.
Classical Techniques: Dominance until 2012
The period leading up to 2012 was dominated by classical machine learning techniques. This era saw the AI community leverage these techniques to address various problems, from finance to healthcare and from robotics to natural language processing.
Landmark Applications Pre-2012
Search Engines: Early search algorithms utilized techniques like TF-IDF (Term Frequency-Inverse Document Frequency) and PageRank to rank web pages, combining these with other machine learning models for personalization.
Financial Forecasting: Algorithms like linear regression, time series analysis, and SVMs were employed in predicting stock prices, assessing credit risks, and algorithmic trading.
Medical Diagnostics: Decision trees and Bayesian models were used to aid diagnostics by analyzing symptoms and medical test results.
Robotics: Techniques like SLAM (Simultaneous Localization and Mapping) used classical algorithms to help robots navigate and map their environments.
Natural Language Processing: Before the dominance of neural-based models, NLP tasks like sentiment analysis, machine translation, and text summarization employed techniques like Hidden Markov Models and Naive Bayes classifiers.
The Reawakening: Neural Networks Rise Again
In science history, there are many ideas that came too early. These ideas were thought of but then set aside until technology improved. In the AI story, this happened with neural networks. They were forgotten for a while, but after a period of dormancy, strengthened by a surge in computational power, neural networks emerged once more, driving AI into a new golden age.
The Catalyst: Enhanced Computing Power
Moore’s Law in Action: Gordon Moore, co-founder of Intel, once predicted that the number of transistors on a microchip would double approximately every two years, leading to a surge in computing power. For decades, this observation held true, leading to exponentially faster and more powerful processors.
Graphics Processing Units (GPUs): Originally designed for rendering video game graphics, GPUs became a game-changer for AI. Their architecture, optimized for performing many tasks in parallel, was well-suited for the matrix operations fundamental to neural networks.
Distributed Computing & Cloud Platforms: With the rise of cloud computing platforms like AWS, Google Cloud, and Azure, researchers could now access vast computational resources on-demand, allowing them to run complex, large-scale neural network models.
Advancements of Neural Networks:
Deep Learning Emerges: With enhanced computing power, neural networks could now be ‘deeper’, with more layers, enabling them to process data in increasingly sophisticated ways. This led to the emergence of ‘deep learning’. Pioneers like Geoffrey Hinton, Yann LeCun, and Yoshua Bengio began exploring multi-layered neural networks, achieving breakthroughs in tasks that stumped classical machine-learning models.
Datasets & Big Data: The digital era brought a deluge of data. Every click, search, and social media post contributed to this vast ocean. Neural networks, especially deep learning models, thrive on large datasets, drawing patterns and insights that would be imperceptible to humans.
Benchmarks & Competitions: Platforms like Kaggle and the ImageNet Large Scale Visual Recognition Challenge provided researchers with platforms to test and refine their neural network models. These competitions drove innovation, with neural networks frequently outperforming other methods.
End-to-End Learning: Unlike classical methods that often require manually crafted features, deep learning models could learn directly from raw data, be it images, text, or sound. This capability reduced the need for domain-specific expertise and made neural network applications more versatile.
What This Means:
Neural networks coming back changed AI a lot. Before, there were jobs computers just couldn’t do, like knowing what’s in a picture, translating quickly, or talking like a person. Now they can do these things.
This change was big. Today’s neural networks, with strong computers behind them, are way better than the old ones. This change made AI do more things, affecting businesses, academia, and our everyday life.
In short, the early ideas about neural networks needed today’s computers to really work and show their full power.
Transitioning to the Deep Learning Era
For many years, older computer methods were used. But around the late 2000s, things started to change. We had more data and much better computer power, especially with GPUs.
2012 is important as it pronounced the dominance of deep learning, with AlexNet’s groundbreaking performance in the ImageNet challenge serving as a catalyst. Post this path-breaking event, our narrative will shift to the rapid advancements in Convolutional Neural Networks (CNNs) from 2012 to 2017, emphasizing their contributions to image classification and object detection. As we move closer to the present day, we’ll study the transformative era post-2017, where transformer-based language models began their ascent, culminating in the sophisticated fusion of language and imagery in the latest AI models.
The Post-Deep Learning Era: The Impact of AlexNet
The post-deep learning era was inaugurated with a model named AlexNet. While Convolutional Neural Networks (CNNs) were not a novel concept by 2012, their full potential had yet to be realized on a large stage. AlexNet’s victory in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012 was more than just a win; it was a transformative moment that stressed the power and potential of deep learning, especially CNNs, in reshaping the landscape of artificial intelligence.





The AlexNet Phenomenon:
Depth and Complexity: AlexNet was a deep architecture with eight layers—five convolutional layers followed by three fully connected layers. It showcased that deeper neural networks could capture intricate patterns in data that earlier models couldn’t.
ReLU Activation Function: AlexNet popularized the use of the Rectified Linear Unit (ReLU) activation function. It demonstrated that ReLU could help deep networks converge faster than traditional activation functions, like tanh or sigmoid, and mitigate the vanishing gradient problem.
Dropout: To combat overfitting, a common challenge for large networks, AlexNet introduced the dropout technique. By randomly dropping units during training, it prevented units from co-adapting too much, making the model more robust.
Parallelization on GPUs: The model was trained on two NVIDIA GTX 580 GPUs, showcasing the potential of GPU parallelism in training large neural networks. This capability played a pivotal role in its training efficiency and performance.
The Significance of the ImageNet Challenge:
The ILSVRC, commonly known as the ImageNet competition, was an annual contest where models were tasked with classifying images into 1,000 categories. ImageNet was a colossal dataset with over a million labeled images. Winning this challenge was not just about academic prestige; it was a testament to a model’s capability to handle real-world, large-scale data.
When AlexNet outperformed the second-place contestant by reducing the classification error rate by nearly 10%. This triumph emphasized that deep learning, and in particular CNNs, were not just theoretically powerful but practically transformative.
Ripple Effects
Surge in Deep Learning Research: After 2012, there was a noticeable surge in research papers, workshops, and conferences focusing on deep learning. Many were inspired by AlexNet’s architecture, leading to the development of subsequent models like VGG, GoogLeNet, and ResNet.
Industry Adoption: Companies rapidly recognized the potential of deep learning for tasks beyond image classification, from voice recognition in virtual assistants to recommendation systems in online platforms.
Democratization of AI: With the proof-of-concept provided by AlexNet, there was an acceleration in the development of deep learning frameworks and libraries, like TensorFlow and PyTorch, making deep learning accessible to a broader community.
While the post-deep learning era was shaped by infinite innovations, breakthroughs, and personalities, AlexNet’s victory in 2012 stands as a defining moment. It underscored a shift from traditional AI methods to the promise held by deep neural networks, making it a cornerstone in the structure of modern AI.
From AlexNet to Beyond: The Evolution of CNNs (2012-2017)
In 2012, AlexNet did something really big, and that was just the start of an exciting time in AI.
From 2012 to 2017, the domain of image classification and object detection underwent rapid advancements, with Convolutional Neural Networks (CNNs) at the forefront. These years were marked by innovations, enhancements, and the rise of models that pushed the boundaries of what CNNs could achieve.
A Chronology of Key CNN Architectures:
1. VGG (2014): Developed by the Visual Geometry Group at Oxford, VGG showcased the benefits of depth in networks. With configurations ranging from 11 to 19 layers, VGG was both simpler in its uniform architecture and more profound than its predecessors. Despite its computational intensity, its structure became a reference point for deep learning research.
2. GoogLeNet/Inception (2014): Introduced by researchers at Google, GoogLeNet brought the Inception module to the fore, which allowed for more efficient computation by smartly utilizing convolutional operations of varying sizes. Notably, GoogLeNet achieved its performance with significantly fewer parameters than other models of its time, highlighting the importance of network architecture over sheer depth.
3. ResNet (2015): Developed by Microsoft Research, the Residual Network or ResNet tackled the problem of training extremely deep networks. By introducing “skip connections” or “shortcuts,” it allowed gradients to flow through those connections, addressing the vanishing gradient problem. ResNet’s deepest variants had a staggering 152 layers, yet they were easier to optimize and achieved lower training error.
4. Faster R-CNN (2015): While the aforementioned models primarily addressed image classification, Faster R-CNN revolutionized object detection. By introducing a Region Proposal Network (RPN) that shared convolutional features with the detection network, it achieved state-of-the-art object detection scores with efficient training and evaluation timeframes.
5. YOLO (You Only Look Once, 2016): A paradigm shift in object detection, YOLO treated the task as a regression problem, predicting bounding boxes and class probabilities in one forward pass. This approach was not only novel but incredibly fast, making real-time object detection feasible.
6. MobileNets (2017): Recognizing the need for deploying models on mobile and embedded systems, Google introduced MobileNets. Using depthwise separable convolutions, it reduced computational cost without a significant compromise in accuracy, paving the way for lightweight, efficient CNNs suitable for edge devices.
The Broader Impact
Benchmarks & Competitions: The ImageNet challenge continued to play a pivotal role, serving as a benchmark for these architectures. Each year, the competition witnessed lower error rates, testifying to the rapid advancements.
Transfer Learning: Models, especially the likes of VGG and ResNet, became popular for transfer learning, where pre-trained models were fine-tuned for new tasks. This drastically reduced the need for large datasets and computational resources in many applications.
Hardware Innovations: The demand for high computational power led to advancements in hardware. NVIDIA, in particular, introduced GPUs tailored for deep learning, enabling faster training times.
Industry Integration: The success of CNNs in research labs translated to real-world applications. From facial recognition in security systems to defect detection in manufacturing and augmented reality in mobile apps, the influence of CNNs has become omnipresent.
In sum, the period from 2012 to 2017 was nothing short of revolutionary for image-based AI tasks. This led to models becoming deeper, more efficient, and adaptable. CNNs matured from being a promising concept to an indispensable tool, not just for image classification or object detection but for the broader canvas of AI applications.
The Advent of Transformer-Based Models: The Language Revolution of 2017 Onwards
2017 heralded the arrival of “Transformers,” a novel architecture that would eventually reshape the landscape of natural language processing (NLP) and even areas beyond it.
The Transformer’s Generation
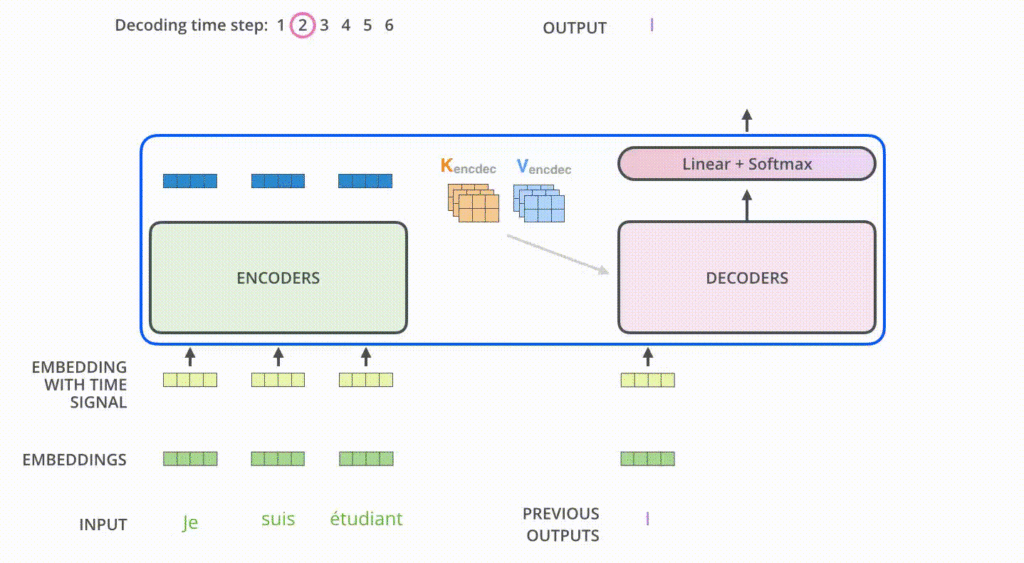
The foundational paper, aptly titled “Attention Is All You Need,” was presented by Vaswani et al. from Google. This work introduced the Transformer architecture, which pivoted away from the recurrent layers used in previous state-of-the-art models like LSTMs and GRUs. Instead, it employed a novel mechanism called “attention” that allowed the model to focus on different parts of the input data, akin to how humans pay attention to specific details while processing information.
Self-Attention Mechanism: This allowed the model to weigh the importance of different words or tokens in a sequence, allowing it to capture long-range dependencies in text, something traditional RNNs struggled with.
Parallel Processing: Unlike sequential RNNs, Transformers process tokens concurrently, optimizing training speed.
Scalability: With sufficient resources, Transformers can be scaled to discern even more complex data patterns.
Two groundbreaking models, building on Transformers:
GPT: OpenAI’s GPT showcased the power of unsupervised learning, exhibiting human-like text generation and excelling in various NLP tasks.
BERT: Google’s BERT utilized bidirectional context, predicting missing words in sentences. It set new standards across multiple NLP benchmarks.
Meta AI’s Llama 2 takes a significant stride towards setting a new benchmark in the chatbot landscape. Its predecessor, Llama, stirred waves by generating text and code in response to prompts, much like its chatbot counterparts.
Beyond NLP:
Interestingly, the Transformer’s influence wasn’t limited to language. Researchers began to adapt it for other domains, including:
1. Vision Transformers (ViTs) split images into fixed-size patches, linearly embed them, and then processed in a manner similar to sequences in NLP. This approach challenged the supremacy of CNNs on certain vision benchmarks.
2. Protein Structure Prediction: The architecture found applications in predicting protein structures, a testament to its versatility.
Industry and Academia Convergence:
1. Pre-trained Models for All: Both GPT and BERT, along with their subsequent iterations, were released as pre-trained models. This democratized advanced NLP capabilities, allowing developers worldwide to fine-tune these behemoths for specific applications, from chatbots to content generation and semantic search.
2. Innovative Platforms: The success of Transformer-based models led to platforms like Hugging Face, which offered a plethora of pre-trained models and made deploying Transformer models almost plug-and-play.
In the years following 2017, the Transformer’s impact was undeniable, with its architecture marking a definitive leap, a coming together of innovation and application that set new horizons for artificial intelligence.
The Fusion Era: Transformers Marrying Language and Vision Since 2021
In AI research, mastering one area often leads to combined innovations. By 2021, Transformers, initially focused on language, began to process visuals alongside text. This fusion opened doors to improved chatbots and AI models discerning the link between images and their descriptions.
Key Innovations and Models:
1. CLIP (Contrastive Language–Image Pre-training): OpenAI’s CLIP represented a paradigm shift. Instead of training separately on visual and textual data, CLIP was trained on a vast set of images paired with natural language descriptions. This enabled it to understand images in the context of the text and vice versa. For instance, given a textual description, CLIP could identify relevant images, and given an image, it could generate or select a fitting textual description.
2. DALL·E: Another groundbreaking model from OpenAI, DALL·E, showcased the power of Transformers in generating images from textual prompts. It could take a phrase as whimsical as “a two-headed flamingo-shaped teapot” and produce a visually coherent, often playful, representation. The model exemplified how deeply language and vision could be interwoven in AI’s generative capabilities.
3. ViLBERT and LXMERT: These models encapsulated the essence of multi-modal learning. By jointly training on image and text data, they achieved state-of-the-art results on tasks that required understanding relationships between visuals and language, such as image captioning and visual question answering.
Implications and Applications:
1. Search Engines: Multi-modal Transformers heralded a new age for search engines. Users could search with images and expect textual results or input textual queries to retrieve relevant images, all with heightened accuracy.
2. Accessibility: These advancements played a significant role in enhancing tools for the visually impaired, offering richer descriptions for images and a better understanding of visual context from textual prompts.
3. Education & Content Creation: In educational settings, AI models could generate illustrative images based on textual content, aiding in visual learning.
4. Entertainment and Gaming: The gaming industry saw potential in these models for creating game environments based on narrative descriptions. Script descriptions could be visualized with more accuracy during the pre-production phases.
The Road Ahead
Merging language and image in Transformers has reshaped AI’s potential, prompting questions about adding audio and touch. How will AI grasp context and emotion with more inputs? This blend of text and visuals in Transformers elevated machine comprehension, transitioning from single to multi-modal understanding. This exciting shift has everyone anticipating AI’s next advancement.
Conclusion – History of AI
The story of artificial intelligence is more than just algorithms and tech; it’s a reflection of humanity’s drive to harness our cognitive powers. From Alan Turing’s early thoughts to today’s advanced Transformers, AI mirrors our evolving grasp on both natural and machine intelligence.
History isn’t merely a log of events; it’s the foundation for the future. The rich history of AI underscores a truth: technologies emerge from human dreams, societal needs, teamwork, and, sometimes, chance discoveries. Beyond code and data, AI is a fabric of human curiosity, persistence, and vision.
Looking at AI’s journey and towards its potential, it’s evident that this isn’t just about machines learning but humans discovering themselves. As we mold AI, it reshapes our world in return.
The future of AI will draw from its past, and it’s our responsibility to guide it, infused with the wisdom of its history, towards our highest aspirations.



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning