
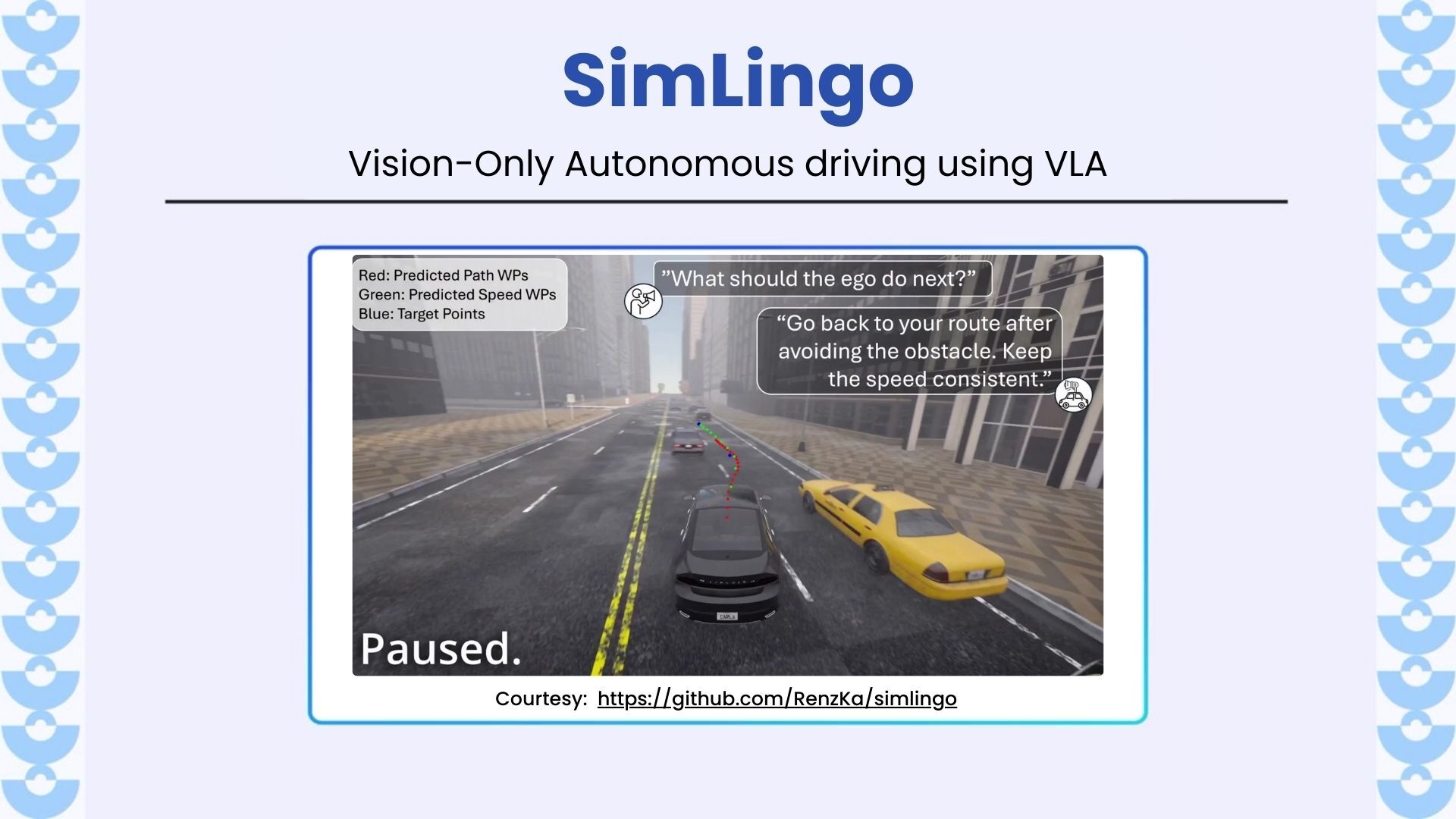
SimLingo unifies autonomous driving, vision-language understanding, and action reasoning-all from camera input only. It introduces Action Dreaming to test how well models follow instructions, and outperforms all prior methods on CARLA Leaderboard 2.0 and Bench2Drive.





Key Highlights
- Unified Model – Combines driving, VQA, and instruction-following using a single Vision-Language Model (InternVL2-1B + Qwen2-0.5B).
- State-of-the-Art Driving – Ranks #1 on CARLA Leaderboard 2.0 and Bench2Drive using camera-only input.
- Action Dreaming Mode – Introduces a novel benchmark to evaluate if language commands lead to aligned actions, without executing unsafe scenarios.
- Commentary = Chain-of-Thought – Driving actions are conditioned on model-generated explanations, improving robustness.
- Vision-Language Understanding – Excels in driving-specific VQA and commentary with 78.9% GPT-score, outperforming InternVL2.
- High Instruction Alignment – Achieves 81% Success Rate on synthetic instruction-to-action test cases, including lane change, speed, and obstacle-centric commands.
- Sim-Only, Real Results – No LiDAR, no radar. Just camera + language. Real-world deployment potential thanks to smaller models and fast inference.
- Open-Source Foundation – Uses PDM-lite, an open rule-based driving expert for scalable data generation.
Why it matters:
- Bridges the gap between language comprehension and real-world control in autonomous vehicles.
- Enables natural-language interfaces-“Turn left”, “Slow down”, “Avoid the cones”-with grounded, aligned actions.
- Improves safety & explainability by forcing the model to reason before it acts.
- Pushes the boundary of what’s possible with camera-only systems, lowering hardware costs and increasing deployability.
- Paves the way for real-time, language-aware autonomous driving, not just in simulation, but soon on real roads.
Know more
- YouTube Video: https://www.youtube.com/watch?v=Mpbnz2AKaNA&t=15s
- Github Repo: https://github.com/RenzKa/simlingo?tab=readme-ov-file
- Related articles on LearnOpenCV:
- GR00T N1.5: https://learnopencv.com/gr00t-n1_5-explained/
- Understanding VLA: https://learnopencv.com/vision-language-action-models-lerobot-policy/
- MASt3r and MASt3r-SfM explained: https://learnopencv.com/mast3r-sfm-grounding-image-matching-3d/


5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning