Motivation
Modern GPU accelerators has become powerful and featured enough to be capable to perform general purpose computations (GPGPU). It is a very fast growing area that generates a lot of interest from scientists, researchers and engineers that develop computationally intensive applications. Despite of difficulties reimplementing algorithms on GPU, many people are doing it to check on how fast they could be. To support such efforts, a lot of advanced languages and tool have been available such as CUDA, OpenCL, C++ AMP, debuggers, profilers and so on.
Significant part of Computer Vision is image processing, the area that graphics accelerators were originally designed for. Other parts also suppose massive parallel computations and often naturally map to GPU architectures. So it’s challenging but very rewarding to implement all these advantages and accelerate OpenCV on graphics processors.
History
OpenCV includes GPU module that contains all GPU accelerated stuff. Supported by NVIDIA the work on the module, started in 2010 prior to the first release in Spring of 2011. It includes accelerated code for siginifcant part of the library, still keeps growing and is being adapted for the new computing technologies and GPU architectures.
Goals
- Provide developers with a convenient computer vision framework on the GPU, maintain conceptual consistency with the current CPU functionality.
- Achieve the best performance with GPUs (efficient kernels tuned for modern architectures, optimized dataflow like async. execution, copy overlaps, zero-copy)
- Completeness (implement as much as possible, even if speed-up is not fantastic; such allows to run an algorithm entirely on GPU and save on coping overheads)
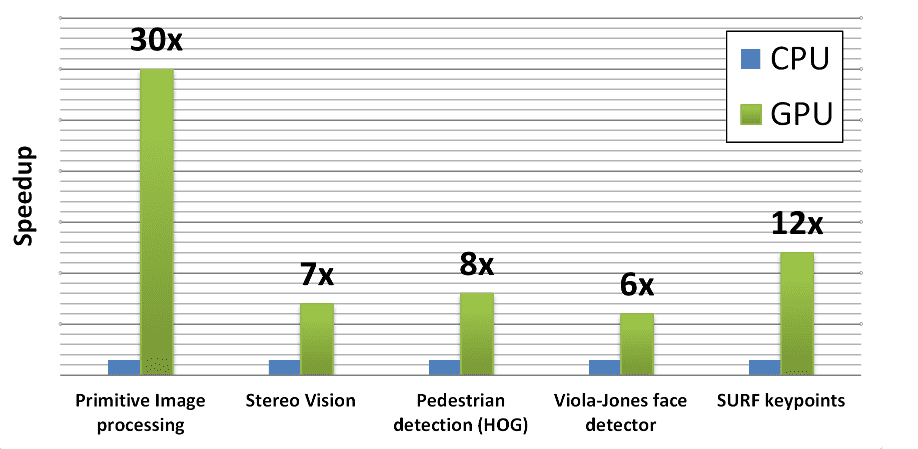
Performance
Tesla C2050 versus Core i5-760 2.8Ghz, SSE, TBB
Design considerations
OpenCV GPU module is written using CUDA, therefore it benefits from the CUDA ecosystem. There is a large community, conferences, publications, many tools and libraries developed such as NVIDIA NPP, CUFFT, Thrust.
The GPU module is designed as host API extension. This design provides the user an explicit control on how data is moved between CPU and GPU memory. Although the user has to write some additional code to start using the GPU, this approach is both flexible and allows more efficient computations.
GPU modules includes class cv::gpu::GpuMat which is a primary container for data kept in GPU memory. It’s interface is very similar with cv::Mat, its CPU counterpart. All GPU functions receive GpuMat as input and output arguments. This allows to invoke several GPU algorithms without downloading data. GPU module API interface is also kept similar with CPU interface where possible. So developers who are familiar with Opencv on CPU could start using GPU straightaway.
Short sample
In the sample below an image is loaded from png0file, next it is uploaded to GPU, thresholded, downloaded and displayed.
#include <iostream>
#include "opencv2/opencv.hpp"
#include "opencv2/gpu/gpu.hpp"
int main (int argc, char* argv[])
{
try
{
cv::Mat src_host = cv::imread("file.png", CV_LOAD_IMAGE_GRAYSCALE);
cv::gpu::GpuMat dst, src;
src.upload(src_host);
cv::gpu::threshold(src, dst, 128.0, 255.0, CV_THRESH_BINARY);
cv::Mat result_host;
dst.download(result_host);
cv::imshow("Result", result_host);
cv::waitKey();
}
catch(const cv::Exception& ex)
{
std::cout << "Error: " << ex.what() << std::endl;
}
return 0;
}