
Now you can enjoy this Article in the form of an audio!
Imagine an expert sommelier. They don’t just identify a wine; they experience it through multiple senses. They see its deep ruby color, inhale its bouquet of black cherry and oak, and taste its complex notes on their palate. They then translate this rich, sensory experience into evocative language, describing it as a “bold Cabernet Sauvignon with a velvety texture and a lingering finish, reminiscent of a summer evening.”

For years, AI models were like wine tasters who could either only see the color or only read a description, but never both. Computer vision models could identify the wine’s color, but couldn’t describe its taste. Large Language Models (LLMs) could write beautiful poetry about wine, but had no idea what a Merlot actually looked like.
Vision Language Models (VLMs) are the new AI sommeliers. For the first time, they bring together sight and language into a single, sophisticated understanding. They can “see” an image, “understand” its nuances, and “articulate” that understanding in fluent, human-like text. This fusion of perception and expression is not just an upgrade, it’s the beginning of a new chapter in artificial intelligence.
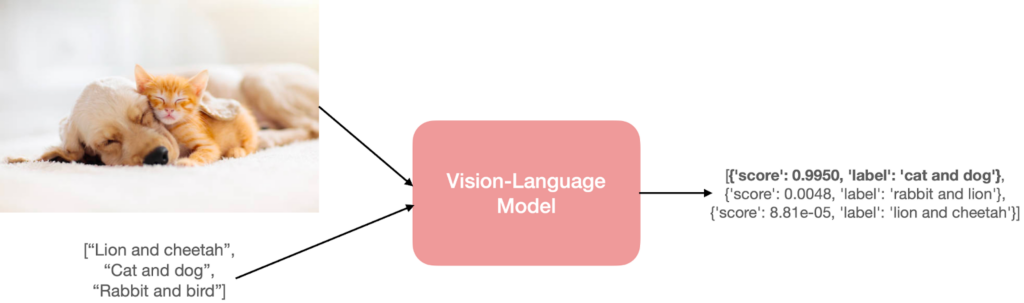
What Are Vision Language Models? Bridging Sight and Speech in AI
Vision Language Models (VLMs) are AI systems that seamlessly combine image understanding with natural language processing. Unlike earlier models that handled vision and text separately, VLMs connect what they see with the words that describe it, allowing machines to “see” and “read” at the same time.
These models play a crucial role in making AI more intuitive and human-like. They go beyond simple object detection to grasp context and meaning, enabling tasks like describing photos, answering questions about videos, or following visual instructions with ease.
How are VLMs different from traditional language models?
Traditional large language models (LLMs), like ChatGPT, are masters of language but purely textual. They generate vivid descriptions of a “sunset over a beach” without ever having seen one; they rely solely on patterns learned from text. Their knowledge is abstract, grounded in language alone.
VLMs, however, are anchored in visual reality. Trained on millions of image-text pairs, they link words like “sunset” to actual visual patterns, pixels, colors, and shapes. making their understanding richer, more concrete, and deeply grounded in the world as we perceive it.
| Feature | Normal Large Language Model (LLM) | Vision Language Model (VLM) |
| Primary Input | Text only | Images and Text |
| Knowledge Base | Derived from text corpora | Grounded in both text and visual data |
| Core Ability | Text-based reasoning and generation | Multimodal reasoning across vision and text |
| Example Task | “Write a poem about the ocean.” | “Describe what is happening in this picture of a beach.” |
VLM Architecture
Vision Language Models (VLMs) combine image and text processing into a unified framework. Their architecture integrates modules that extract and align visual and textual features, enabling seamless multimodal understanding and generation. Below is a simplified breakdown of the key components we’ll implement for our project.





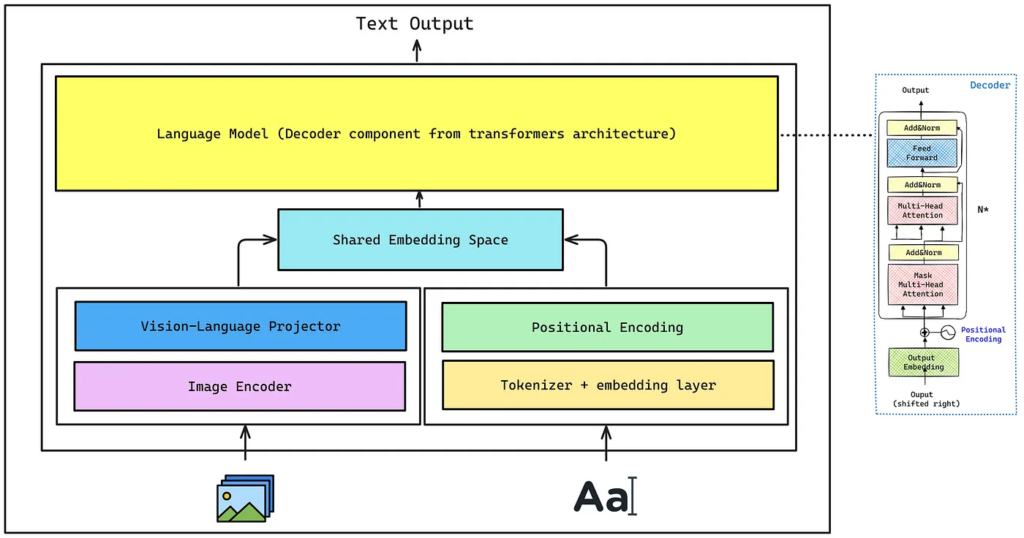
Key Components
- Image Encoder: Extracts meaningful features from images by dividing them into patches and processing them using a Vision Transformer (ViT).
- Vision–Language Projector: Aligns image embeddings with text embeddings by projecting visual features into the same dimensional space, using a small multilayer perceptron (MLP).
- Tokenizer + Embedding Layer: Converts input text into token IDs and maps them to dense vectors that capture semantic meaning.
- Positional Encoding: Adds spatial or sequential information to embeddings, helping the model understand token order and context.
- Shared Embedding Space: Combines projected image tokens with text embeddings into a unified sequence, allowing joint attention over both modalities.
- Decoder-Only Language Model: Generates output text autoregressively, producing tokens one at a time based on the integrated visual-textual context.
Datasets for Vision Language Models
Collecting high-quality training data for VLMs is more complex than for traditional AI models because it requires aligned multimodal data (images paired with text). Tools like Encord Index help simplify data management and curation for these tasks. Here are some key datasets commonly used for multimodal training:
- LAION-5B: A massive dataset with over 5 billion image-text pairs sourced using CLIP. It includes descriptions in multiple languages, supporting multilingual VLM training.
- PMD (Public Model Dataset): Compiled from large-scale datasets like COCO and Conceptual Captions, PMD contains 70 billion image-text pairs, providing rich multimodal data for robust model training.
- VQA (Visual Question Answering): Contains 200,000+ images, each paired with five questions, multiple correct answers, and distractors. It is widely used to fine-tune VLMs for visual reasoning tasks.
- ImageNet: Over 14 million images labeled according to the WordNet hierarchy. Primarily used for tasks like image classification and object recognition, it supports simpler downstream applications.
Evolution of VLMs – Tracing their development from CLIP to advanced models like LLaVA
The journey of VLMs has been rapid and exciting:
- Pioneering Models (e.g., CLIP): OpenAI’s CLIP (Contrastive Language-Image Pre-training), released in 2021, was a major breakthrough. CLIP was trained on a massive dataset of image-text pairs from the internet. It learned to determine how well a given text description matched an image. While it couldn’t generate descriptions itself, it created a powerful shared embedding space that became a foundational block for future models.
- Generative Models (e.g., Flamingo, LLaVA): The next step was to move from matching to generating. Models like Google’s Flamingo and, more recently, LLaVA (Large Language and Vision Assistant) were built upon these ideas. LLaVA, for instance, connects the vision backbone of CLIP with a powerful LLM (like Vicuna). By using a simple fusion mechanism and fine-tuning the model on instruction-following datasets, LLaVA demonstrated the ability to have complex, conversational dialogues about images, marking a significant step towards the VLM assistants we see today.
Applications of VLMs
The real-world applications of Vision Language Models are already transforming technology:
- Image Captioning: Automatically generating accurate and descriptive captions for images, which is invaluable for accessibility (e.g., screen readers for the visually impaired) and content organization.

- Visual Question Answering (VQA): Asking specific questions about an image and getting detailed answers. For example, “How many people are sitting at the table in this cafe?” or “What color is the car on the right?”
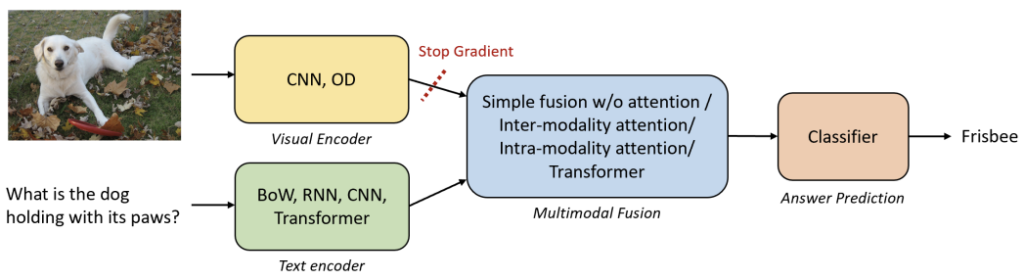
- Image-Text Retrieval: Revolutionizing search engines. Instead of just searching with text, you can use an image and text to find what you’re looking for. For instance, uploading a picture of a chair and asking, “Where can I buy a similar dining chair but in blue?”

Source: https://arxiv.org/pdf/2210.09263
Challenges & Limitations of Vision-Language Models (VLMs)
Despite their advances, VLMs face several challenges:
- Model Complexity: Combining language and vision models increases overall complexity, making them harder to train and deploy.
- Bias: VLMs can inherit biases from training data, causing them to memorize incorrect patterns rather than truly understand differences in images.
- Limited Understanding: VLMs rely on pattern recognition rather than reasoning, which limits their ability to grasp nuanced or ambiguous relationships between text and visuals.
- Hallucinations: They may confidently generate incorrect answers when unsure, known as hallucinations.
- Generalization: VLMs can struggle with generalizing to unseen or out-of-distribution data.
- High Computational Cost: Training and deploying VLMs require substantial computational resources.
- Ethical Concerns: Using data collected without consent raises important ethical issues in training VLMs.
In conclusion, Vision Language Models are far more than just a clever fusion of two technologies. They represent a pivotal step towards creating AI that can perceive, understand, and communicate about our world with a richness and intuition that more closely mirrors our own. Like the expert sommelier, they are teaching machines not just to see, but to comprehend, and in doing so, are uncorking a new vintage of possibilities for the future of artificial intelligence.



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning