
Computer vision is one of artificial intelligence’s most dynamic and rapidly advancing areas, enabling machines to interpret and understand the visual world. From self-driving cars that detect and avoid pedestrians to smartphone apps that instantly translate text, the power of computer vision drives countless everyday technologies. In this blog, we’ll explore five practical and impactful computer vision projects that will sharpen your skills, illustrate core concepts, and open the door to a wide range of real-world applications.
Whether you’re a beginner experimenting with image processing or an experienced developer diving into advanced deep learning methods, these projects offer hands-on experience that can take your computer vision expertise to the next level.
So, Lets begin
Project 1: Object Detection with YOLO or SSD
Overview
Object detection is all about identifying and locating objects within an image. Instead of simply classifying an image (like “cat” or “dog”), you need to draw bounding boxes around each detected object and label it. Two popular models that make this feasible in real time are:
- YOLO (You Only Look Once)
- SSD (Single Shot Detector)
Both are known for their speed and accuracy, which is critical for applications like autonomous driving, surveillance, or real-time analytics.
Tools & Technologies Required
- Programming & Libraries: Python, OpenCV
- Deep Learning: TensorFlow or PyTorch
- Models: Pre-trained YOLO or SSD weights (e.g., YOLOv5, SSD MobileNet)
Steps to Implement
- Environment Setup
- Install Python (3.6+), OpenCV, and your chosen deep learning framework (TensorFlow/PyTorch).
- Verify your GPU drivers and CUDA (if available) for faster training and inference.
- Dataset Acquisition
- Use an existing dataset like COCO or Pascal VOC, or collect your own.
- If gathering custom data, label your images using tools like LabelImg or Roboflow.
- Load a Pre-trained Model
- Download a pre-trained YOLO/SSD model.
- Write a script to load the model and run inference on sample images.
- Inference & Visualization
- For each detected object, the model returns class labels, bounding box coordinates, and confidence scores.
- Draw rectangles and labels on the original image to visualize your detection results.
- Interpretation
- Check confidence thresholds to filter out weak detections.
- Experiment with different input sizes and model configurations to balance speed and accuracy.
Potential Extensions
- Fine-tuning on a Custom Dataset: Improve accuracy for domain-specific objects (e.g., detecting pests in agriculture).
- Deployment via Flask/FastAPI: Serve detections via a web interface, allowing users to upload images or stream live video for detection in real time.
Projects on YOLO
- Project: Pothole detection using YOLOv8
- Link: https://learnopencv.com/train-yolov8-on-custom-dataset/

- Project: Underwater Trash Detection
- Link: https://learnopencv.com/yolov6-custom-dataset-training/

Project 2: Face Recognition System
Overview
Face recognition goes beyond face detection. While detection locates faces within an image, recognition identifies “whose face” it is. This is especially important in:
- Security systems (building access, surveillance)
- User authentication (phone unlock, online ID verification)
Tools & Technologies Required
- Python with OpenCV
- Face Recognition Libraries: Dlib/FaceNet (for feature extraction and embedding)
- Classifier: scikit-learn (for building a face recognition classifier, e.g., SVM or KNN)
Steps to Implement
- Face Detection Setup
- Options include Haar Cascades, MTCNN, or deep learning-based detectors.
- Detect the bounding box of each face in an image or video frame.
- Feature Extraction & Encoding
- Use Dlib or FaceNet to convert the detected face into a numerical vector (embedding) representing that face’s features.
- Classifier Training
- Gather multiple face images for each person you want to recognize.
- Train a simple SVM or KNN on these embeddings to classify identities.
- Testing the Pipeline
- Run real images or live video streams through the pipeline.
- Observe how well the system distinguishes between registered individuals.
Potential Extensions
- Real-time Video Recognition: Integrate face recognition into a live feed for office entry or event check-ins.
- Access Control Integration: Combine with IoT or door lock systems to automate entry.
Project
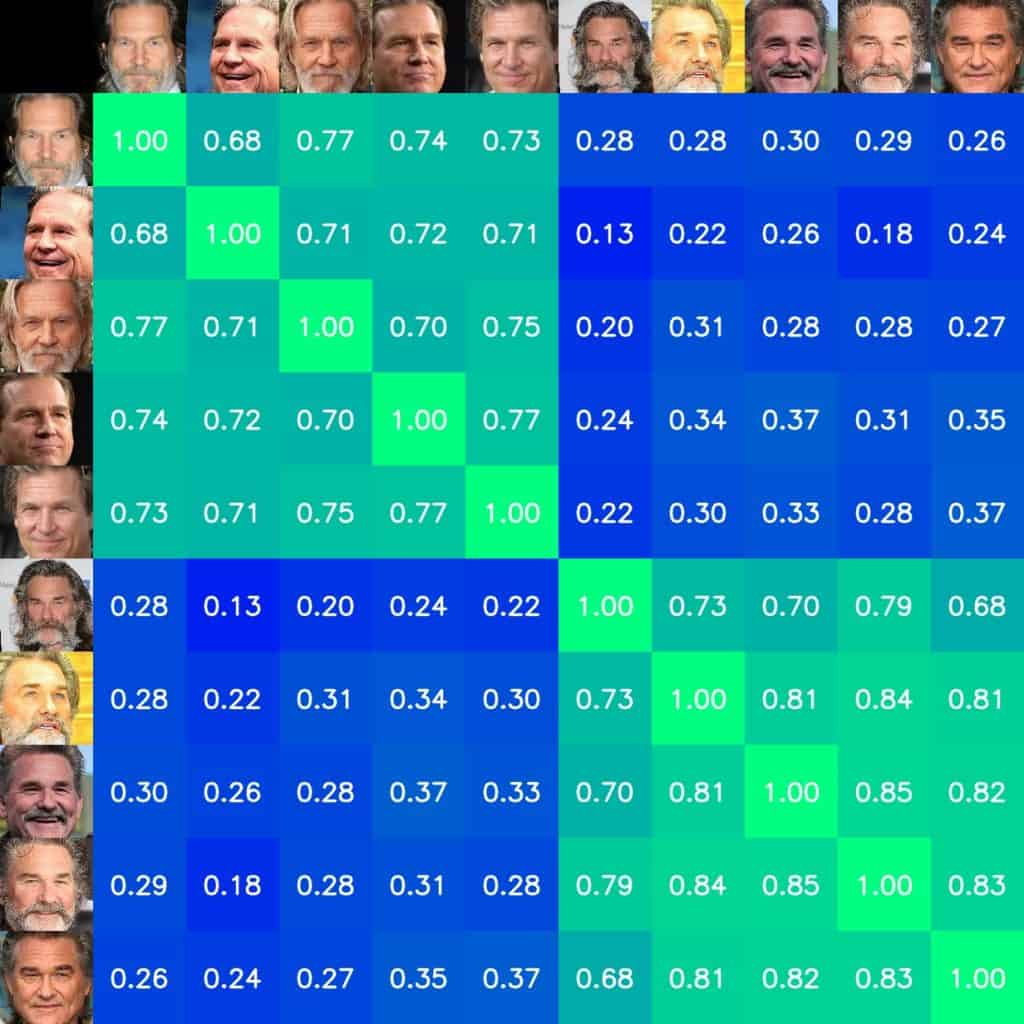
Project: Face Recognition with ArcFace
Link: https://learnopencv.com/face-recognition-with-arcface/
Other Resources
- https://learnopencv.com/face-recognition-models/
- https://learnopencv.com/face-recognition-an-introduction-for-beginners/
Project 3: Image Segmentation (Semantic or Instance Segmentation)
Overview
Image segmentation divides an image into regions or objects, offering a pixel-level understanding of what’s in the scene:
- Semantic Segmentation: Labels every pixel with a class (e.g., “sky,” “car,” “tree”).
- Instance Segmentation: Differentiates between multiple objects of the same class (e.g., two separate cars).
Tools & Technologies Required
- Python, TensorFlow or PyTorch
- Popular segmentation architectures: U-Net, Mask R-CNN, or DeepLabv3
Steps to Implement
- Model Selection
- Pick a pre-trained model known for segmentation tasks (e.g., Mask R-CNN with COCO weights).
- Alternatively, train from scratch if you have a sufficiently labeled dataset.
- Data Preprocessing
- Resize images, normalize pixel values, and ensure masks or annotations are correctly formatted.
- Tools like COCO format or Pascal VOC can standardize your annotations.
- Training or Loading Weights
- If training from scratch, monitor training with IoU (Intersection over Union) or pixel accuracy.
- If using pre-trained weights, adapt them to your dataset via transfer learning.
- Evaluation
- Use metrics like mAP, IoU, or Dice Coefficient to gauge segmentation quality.
Potential Extensions
- Medical Imaging Applications: Segment tumors or organs in MRI/CT scans.
- Autonomous Driving: Segment road lanes, vehicles, pedestrians for advanced driver-assistance systems (ADAS).
- Improving Accuracy: Leverage data augmentation or advanced architectures (Swin Transformer, etc.) for better results.
Projects
- Project: Satellite Water Body Semantic
- Link: https://learnopencv.com/kerascv-deeplabv3-plus-semantic-segmentation/

- Project: Document Segmentation
- Link: https://learnopencv.com/deep-learning-based-document-segmentation-using-semantic-segmentation-deeplabv3-on-custom-dataset/

Other Resources:
- Deep Lab Explained: https://learnopencv.com/deeplabv3-ultimate-guide/
- YOLOv8 Instance Seg: https://learnopencv.com/train-yolov8-instance-segmentation/
- SegFormer Lane Segmentation: https://learnopencv.com/segformer-fine-tuning-for-lane-detection/
- Background Removal: https://learnopencv.com/u2-net-image-segmentation/
Project 4: Pose Estimation
Overview
Pose estimation identifies key body joints (elbows, knees, shoulders, etc.) to form a skeleton. It’s used in:
- Fitness Tracking (counting reps, checking posture)
- Motion Capture (gaming, movie animation)
- Gesture Control (UI interactions, sign language translation)
Tools & Technologies Required
- Python with a deep learning framework (TensorFlow/PyTorch)
- OpenPose, MoveNet, MediaPipe, or YOLO-based keypoint detection
- Datasets: COCO keypoint dataset (or gather your own for specialized movements)
Steps to Implement
- Choose a Pre-trained Model
- For quick results, download weights for OpenPose, MoveNet, or MediaPipe.
- Inference on Images/Video
- Pass each frame (or image) to the pose estimator.
- Extract x,y coordinates for each body joint.
- Visualization
- Draw lines connecting the detected joints to form a skeleton overlay on the image or video feed.
Potential Extensions
- Time-series Analysis: Track pose changes over time to analyze dance routines or sports performance.
- Real-time Feedback: Give users immediate guidance on form (e.g., for at-home workouts or rehabilitation).
Projects
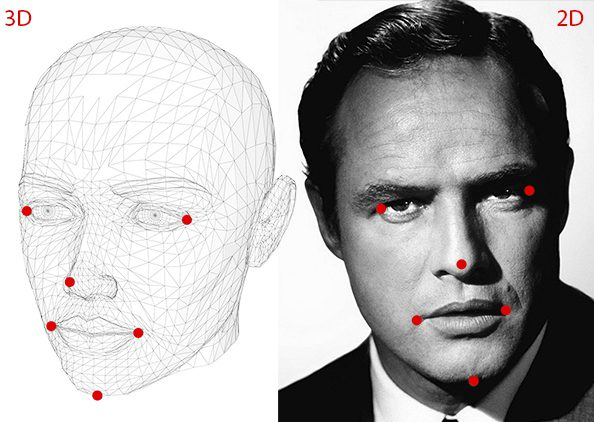
- Project: Head Pose Estimation
- Link: https://learnopencv.com/head-pose-estimation-using-opencv-and-dlib/
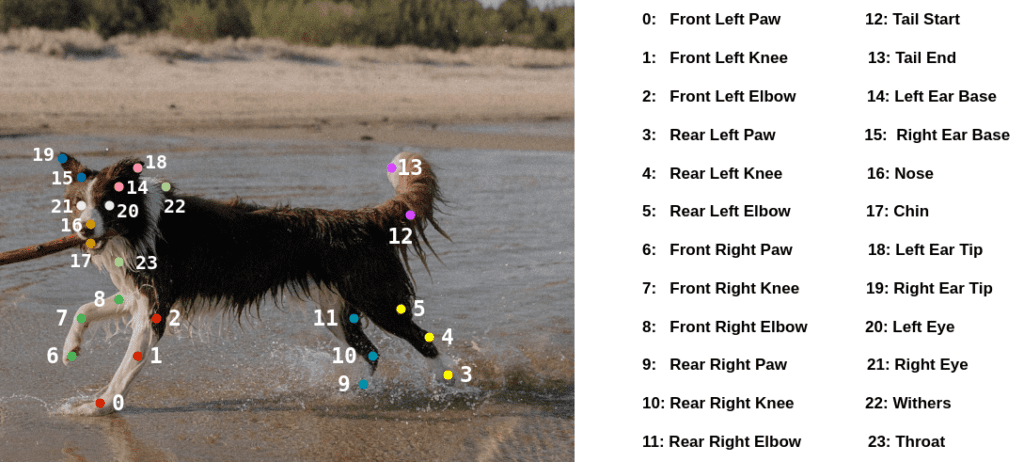
- Project: Animal Pose
- Link: https://learnopencv.com/animal-pose-estimation/
Other Resources:
- YOLOv7 Vs MediaPipe Pose: https://learnopencv.com/yolov7-pose-vs-mediapipe-in-human-pose-estimation/
- KeyPoint RCNN: https://learnopencv.com/human-pose-estimation-using-keypoint-rcnn-in-pytorch/
- AI Fitness Trainer: https://learnopencv.com/ai-fitness-trainer-using-mediapipe/
- Zoom Gesture Control:https://learnopencv.com/gesture-control-in-zoom-call-using-mediapipe/
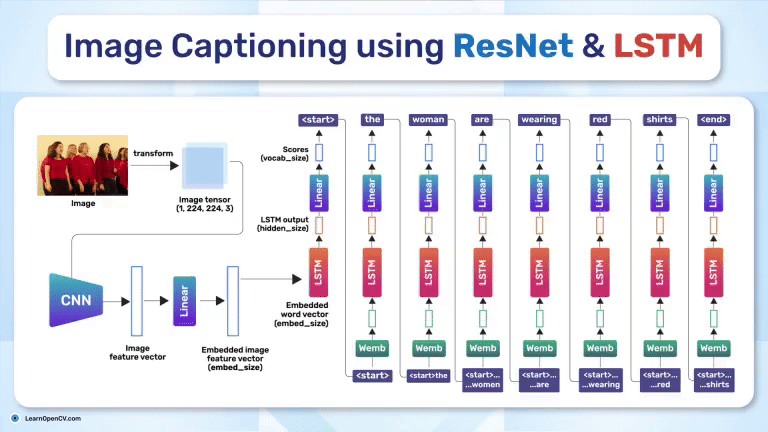
Project 5: Image Captioning
Overview
Image captioning blends computer vision and natural language processing. Models extract visual features from images and then generate meaningful textual descriptions. It’s widely used for:
- Accessibility (helping visually impaired users interpret images).
- Image Search (auto-tagging and captioning photos).
Tools & Technologies
- Python with TensorFlow or PyTorch
- Pre-trained CNN (e.g., ResNet) for feature extraction
- RNN/LSTM or Transformer for language modeling
Steps to Implement
- Model Selection
- Choose an architecture:
- CNN + LSTM (Show and Tell),
- CNN + Transformer (Show, Attend and Tell),
- or purely Transformer-based image captioning.
- Choose an architecture:
- Preprocessing
- Image Feature Extraction: Use a CNN to convert images into feature vectors.
- Text Processing: Tokenize and embed caption words for training (BLEU-based text metrics).
- Training
- Use standard datasets like MS-COCO or Flickr8k/30k.
- Train the decoder (LSTM/Transformer) to generate captions word by word based on image features.
- Evaluation
- Common metrics: BLEU, METEOR, or CIDEr scores.
- Compare generated captions to ground-truth captions in the dataset.
Potential Extensions
- Attention Mechanisms: Improve descriptions by letting the model “focus” on relevant parts of the image.
- Multilingual Captioning: Adapt the model to generate captions in multiple languages for cross-cultural accessibility.
- Domain-Specific Captions: Create captions tailored to specialized fields (e.g., medical imaging).
Projects
- Project: Image Captioning ResNet
- Link: https://learnopencv.com/image-captioning/
Project 6: Optical Character Recognition (OCR)
Overview
OCR extracts text from images or scanned documents, playing a crucial role in:





- Digitizing paper documents (archiving, searching).
- License plate recognition in smart traffic systems.
- Invoice or receipt scanning for automated data entry.
Tools & Technologies
- Python, OpenCV (for image preprocessing)
- Tesseract OCR, EasyOCR, or Deep Learning-based text detectors (EAST, CRAFT)
- TrOCR (Transformer-based text recognition)
Steps to Implement
- Preprocessing
- Enhance text clarity using techniques like thresholding, denoising, and skew correction.
- Text Detection
- Use a bounding box approach (e.g., EAST model) to locate text regions in the image.
- Text Recognition
- Apply Tesseract, EasyOCR, or Transformer-based models to extract textual content.
- Validation
- Check accuracy against ground-truth text or manual inspection.
- Fine-tune detection thresholds if needed (confidence scores, non-max suppression).
Potential Extensions
- Real-time OCR on mobile devices or embedded systems (e.g., Raspberry Pi).
- Multilingual Support: Train or configure OCR for various scripts (Arabic, Chinese, Devanagari, etc.).
Projects
- Project: Handwritten Text Recognition TrOCR
- Link: https://learnopencv.com/handwritten-text-recognition-using-ocr/
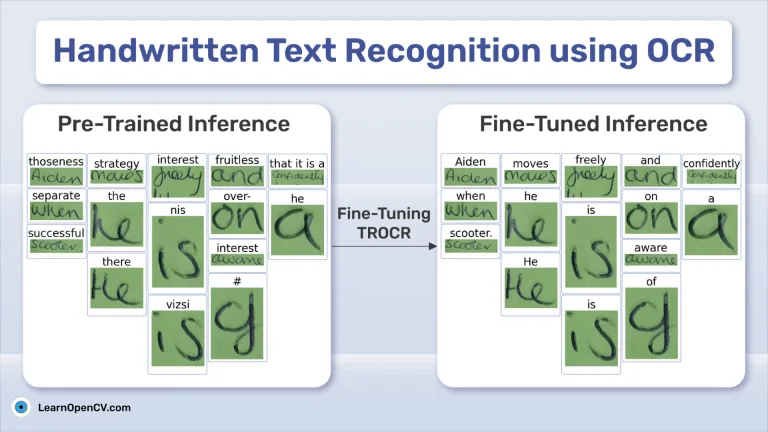
Other Resources:
- Curve Text Recognition TrOCR: https://learnopencv.com/fine-tuning-trocr-training-trocr-to-recognize-curved-text/
- Tesseract: https://learnopencv.com/deep-learning-based-text-recognition-ocr-using-tesseract-and-opencv/
- ANPR: https://learnopencv.com/automatic-license-plate-recognition-using-deep-learning/
Project 7: Image Colorization
Overview
Image colorization breathes life into grayscale or historical photos by predicting color information. It’s used for:
- Restoring old or damaged photographs.
- Creating artistic effects for modern design.
Tools & Technologies
- Python, OpenCV
- Deep Learning Frameworks (TensorFlow, PyTorch)
- U-Net or CNN-based autoencoders for color prediction
Steps to Implement
- Dataset Preparation
- Collect paired grayscale and color images.
- Convert color images to LAB color space (often helpful in colorization tasks).
- Model Training
- Train a network (e.g., U-Net) to map grayscale input to the color channels (e.g., a/b in LAB).
- Evaluation
- Compare color fidelity with PSNR or SSIM, or rely on subjective visual quality.
- Refinement
- Tweak hyperparameters (learning rate, batch size) or network layers for better color realism.
Potential Extensions
- Interactive Colorization: Allow users to guide or modify color regions in real-time.
- Domain-Specific Training: For historical images, learn characteristic colors of certain eras or film types.
Projects
Project: Image Colorization Using CNN With OpenCV
Link: https://learnopencv.com/convolutional-neural-network-based-image-colorization-using-opencv/

Other Resources:
- Color spaces in OpenCV: https://learnopencv.com/color-spaces-in-opencv-cpp-python/
Project 8: Visual Question Answering (VQA)
Overview
VQA enables a system to understand an image and answer questions about it—bridging the gap between computer vision and natural language processing. It’s used in:
- Accessibility Tools for Visually Impaired Users.
- Interactive systems (e.g., AI assistants, educational apps).
Tools & Technologies
- Python, TensorFlow, or PyTorch
- Pre-trained CNN (e.g., ResNet, Vision Transformer) to extract image features
- LSTM/Transformer for text-based question analysis
- Datasets: VQA v2.0, CLEVR (synthetic)
Steps to Implement
- Image Feature Extraction
- Use a CNN/ViT to generate feature vectors.
- Question Processing
- Tokenize questions into embeddings.
- Optionally, use advanced language models or Transformers (BERT, GPT-based).
- Multi-modal Fusion
- Combine (concatenate/attention) the image features and question embeddings.
- Train a classifier or sequence generator to produce answers.
- Evaluation
- Compare generated answers with ground-truth using accuracy or specialized metrics (e.g., exact match, WUPS).
Potential Extensions
- Advanced Attention: Use self-attention mechanisms to focus on image regions related to the specific question.
- Domain-Specific VQA: Medical imaging (e.g., “Does this X-ray show a fracture?”) or retail applications (e.g., “How many items are on the shelf?”).
Project 9: Image Super-Resolution
Overview
Super-resolution magnifies low-resolution images while retaining or enhancing detail. It’s key for:
- Improving CCTV or security camera footage.
- Satellite and medical imaging for higher detail analysis.
Tools & Technologies
- Python, TensorFlow/PyTorch
- Architectures: SRCNN, ESRGAN, SwinIR
Steps to Implement
- Data Preparation
- Pair each high-resolution image with a downsampled (low-res) version.
- Create training, validation, and test splits.
- Model Training
- Train a CNN or GAN-based model to learn the mapping from low-res to high-res images.
- Evaluation
- Use metrics like PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index).
- Inference
- Apply the model to unseen low-res images and measure the improvement in clarity.
Potential Extensions
- Real-time Enhancement: Deploy models for streaming video content (e.g., real-time video calls).
- Denoising + Super-Resolution: Combine both tasks to handle noisy low-res images effectively.
Projects
- Project: Super Resolution
- Link: https://learnopencv.com/super-resolution-in-opencv/
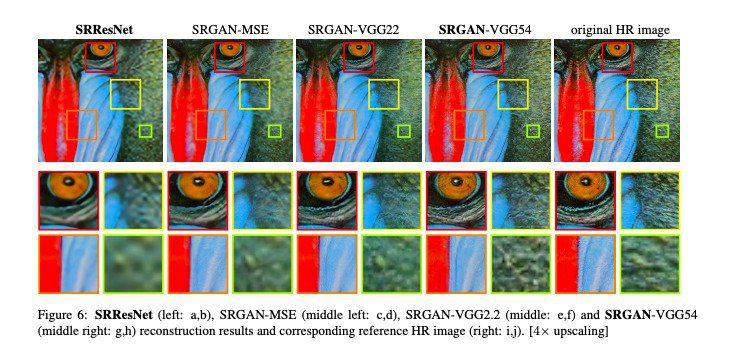
Project 10: Anomaly Detection in Images/Videos
Overview
Anomaly detection identifies unusual or unexpected patterns in images or video streams. Applications include:
- Manufacturing (defect detection on assembly lines).
- Security (monitoring for suspicious activities in surveillance footage).
Tools & Technologies
- Python, OpenCV
- Deep Learning Frameworks (TensorFlow/PyTorch)
- Autoencoders, CNNs, or One-Class SVM
Steps to Implement
- Data Collection
- Gather normal (non-defective) data to model what “normal” looks like.
- (Optional) Include known anomalies for validation.
- Model Training
- Autoencoder: Learn to reconstruct normal images. Anomalies have higher reconstruction errors.
- One-Class Classification: Model normal distribution, flag outliers as anomalies.
- Detection
- After training, feed new images to the model.
- Monitor error or distance measures to identify deviations from normal patterns
- Validation
- Confirm anomalies with known outlier samples or manual inspection.
Potential Extensions
- Real-time Anomaly Detection: Deploy the model in a live system for immediate alerts.
- Transfer Learning: Fine-tune a base autoencoder for specific anomaly types (e.g., cracks in buildings).
Projects
Project: Moving Object Detection with OpenCV
Link: https://learnopencv.com/moving-object-detection-with-opencv/

Other Resources
- Intruder Detection OpenCV: https://youtu.be/rsi2TROixFc?feature=shared
Conclusion
From basic object detection and face recognition to image captioning, VQA, and anomaly detection, these ten projects span a wide range of computer vision challenges. Each highlights a different facet of the field—be it interpreting visual data at the pixel level, extracting meaningful text, or pairing visuals with natural language understanding.
By working through these projects, you’ll gain hands-on experience with:
- Core Techniques: bounding box detection, keypoint extraction, segmentation, and super-resolution.
- Cutting-Edge Architectures: Including CNNs, Transformers, and GAN-based models for tasks like image generation and text recognition.
- Real-World Scenarios: Ranging from medical imaging and security surveillance to multimedia search engines and accessibility tools.
As computer vision evolves, these foundational projects serve as stepping stones toward more specialized or advanced applications—like self-driving cars, augmented reality, or complex multimodal interfaces. For more advanced and professional use cases, a tool such as Roboflow can unify the many moving parts of CV & AI development and deployment. Whether you’re looking to enhance your skill set, jumpstart a career in AI, or innovate within your organization, exploring these projects will deepen your understanding of modern computer vision and inspire new ideas for transforming the way machines see and interpret the world.
Dive in, experiment boldly, and unlock the incredible potential that computer vision offers!



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning