

Are you looking for a fast way to run neural network inferences on Intel platforms? Then OpenVINO toolkit is exactly what you need. It provides a large number of optimizations that allow blazingly fast inference on CPUs, VPUs, integrated graphics, and FPGAs.
In the previous post, we’ve learned how to prepare and run DNN models in a OpenVINO environment. Today you’ll learn more about the DNN model optimization techniques.
We will cover the following topics:
- Prerequisites
- Model Optimizer
- Post-training Optimization Tool
- Benchmark Tool
- Summary and Conclusions
1. Prerequisites
Before we start, ensure that you have the latest release of OpenVINO Toolkit installed. To do that, you should use the official installation instructions: they are available for most commonly used platforms (Linux, MacOS, Windows). For this example, we will use Ubuntu 18.04.
Please also make sure that the OpenVINO environment is correctly initialized. You could do that manually using this command:
source <OPENVINO_INSTALL_DIR>/bin/setupvars.sh
Alternatively, you could add this command to bash initialization script
`~/.bashrc` config
So the environment will be initialized every time you open a new terminal window.
Let’s download and prepare the models for our experiments. We will use PyTorch implementations of BlazeFace and FaceMesh (from this and this repos correspondingly) that were converted to ONNX format in the previous post. However, OpenVINO allows us to use a variety of models from other popular frameworks like TensorFlow, Caffe, or MxNet.
mkdir -p ~/openvino_optimization/models cd ~/openvino_optimization/models wget link_to_GoogleDrive_blazeface.onnx wget link_to_GoogleDrive_facemesh.onnx
2. Model Optimizer
Usually, trained DNNs (as well as the models we downloaded before) are not optimized for inference by default. OpenVINO Toolkit provides Model Optimizer – a tool that optimizes the models for inference on target devices using static model analysis. Specifically, it fuses some consecutive operations together for better performance.
2.1 Installation and configuration
Model Optimizer is deployed as a part of the OpenVINO Toolkit. Its installation and configuration are a part of the toolkit installation instructions, and to configure it, we just need to execute:
cd <OPENVINO_INSTALL_DIR>/deployment_tools/model_optimizer/install_prerequisites sudo ./install_prerequisites.sh
Note that this will install prerequisites globally. To keep your system clean, you may want to initialize it in a dedicated environment:
virtualenv --system-site-packages -p python3 ./venv source ./venv/bin/activate ./install_prerequisites.sh
2.2 Converting model to Intermediate Representation
In order to run Model Optimizer we should use `mo.py` script located in <OPENVINO_INSTALL_DIR>/deployment_tools/model_optimizer directory. The simplest way to use it is just to provide the model file as the input:
python3 mo.py --input_model INPUT_MODEL
Model Optimizer is highly configurable. There are variety set of parameters that allow us to adjust the conversion process. Model Optimizer also allows merging the input preprocessing stages right into the resulting model.
- –input_shape: Input shape(s) that should be fed to an input node(s) of the model.
- –scale: All input values coming from original network inputs will be divided by this value.
- — mean_values: Per channel mean values to be used for the input image.
- –scale_values: Per channel scale values to be used for the input image.
- –data_type: Data type for all intermediate tensors and weights (FP16, FP32).
Let’s optimize our prepared ONNX models.
mo.py --input_model ~/openvino_optimization/models/blazeface.onnx --model_name blazeface_fp32 mo.py --input_model ~/openvino_optimization/models/facemesh.onnx --model_name facemesh_fp32
As a result of the optimization, we created a `.xml` file for each model – it contains the model architecture description. We also created `.bin` files with model weights and biases. We can load these files into OpenVINO Inference Engine for optimized inference.
In this example, we have models with full-precision floating-point operations inside – in a FP32 format. However, some devices, like those based on Intel® Movidius™ Myriad™ X VPU, only support FP16. This allows efficient operation for neural network inference on devices like Intel Neural Compute Stick 2 or the OpenCV AI Kit. To deploy models to similar edge devices, convert them to FP16 format.
mo.py --data_type FP16 --input_model ~/openvino_optimization/models/blazeface.onnx --model_name blazeface_fp16 mo.py --data_type FP16 --input_model ~/openvino_optimization/models/facemesh.onnx --model_name facemesh_fp16
FP 16, or ‘half-precision computations’, have a smaller value range. However, in many tasks, the range may be good enough, and the inference quality will stay the same. And the model consumes less memory. For example, in our case, the FP16 model weights file is half of the size of the FP32 one.
Half precision models may also deliver better performance. It is worth noting though that not all the hardware architectures support FP16.
3. Post-training Optimization Tool
Another optimization tool deployed within OpenVINO toolkit is the Post-training Optimization Tool (POT). It is designed for advanced deep learning models optimization techniques that do not require re-training the model.
3.1 Installation and configuration
Let’s install the POT.
cd <OPENVINO_INSTALL_DIR>/deployment_tools/tools/post_training_optimization_toolkit python3 setup.py install
This will deploy the tool to python environment and it will be available by the pot alias. To verify that installation is successful you can just run pot -h
3.2 Low-precision quantization and inference in OpenVino
The major compression and acceleration technique provided by POT is uniform model quantization. It allows the use of low-precision fixed-point numbers (for example, INT8) to approximate the original full-precision floating point (FP32) network weights.
Quantization is performed in two stages:
1. Model quantization. Special FakeQuantize operations are added before some of the network layers to create quantized tensors. The output of this stage is a quantized model. The precision of the quantized model stays the same, and the quantized tensors are stored in the original precision range (FP32).
2. Low-precision inference. This stage is performed by the CPU plugin that is used by OpenVINO Inference Engine. This plugin updates FakeQuantize layers to use quantized output tensors in a low precision range. It also adds dequantization layers to compensate for the update. Dequantization layers are pushed through as many layers as possible to have more layers in low precision. After that, most layers use quantized input tensors in low precision range and can be inferred in low precision.
Currently, the following layers are supported by OpenVINO Inference Engine in INT8 low-precision computation mode:
- Convolution
- FullyConnected
- ReLU
- ReLU6
- Reshape
- Permute
- Pooling
- Squeeze
- Eltwise
- Concat
- Resample
- MVN
The more such layers that are stored in the network consecutively (and may be fused for INT8 inference), the more performance gain may be expected.
There are two main and recommended to use quantization algorithms implemented in POT:
- DefaultQuantization – the default method to get fast and in most cases accurate results for 8-bit quantization.
- AccuracyAwareQuantization allows staying within a predefined accuracy drop after the quantization to increase performance. Accuracy Checker Tool, part of the OpenVINO toolkit, is used to validate model accuracy during the quantization process using an annotated dataset.
Next we will focus on the DefaultQuantization algorithm which we can use to perform INT8 model quantization even with an unannotated dataset.





3.3 Models quantization
First, we need to prepare a dataset that will be used as input data during the quantization process. Download an aligned LFW dataset from the official site and put all the images to a single folder:
mkdir -p ~/openvino_optimization/data cd ~/openvino_optimization wget https://vis-www.cs.umass.edu/lfw/lfw-deepfunneled.tgz tar -xzf lfw-deepfunneled.tgz cp ./lfw-deepfunneled/*/*.jpg ./data/. cd ~/openvino_optimization/models
Second, prepare a config file for POT with quantization parameters. Let’s use the default template, update it with our models’ info and save as quantization_spec.json:
{
/* Model parameters */
"model": {
"model_name": "blazeface_fp32_int8", // Model name
"model": "blazeface_fp32.xml", // Path to model (.xml format)
"weights": "blazeface_fp32.bin" // Path to weights (.bin format)
},
/* Parameters of the engine used for model inference */
"engine": {
/* Simplified mode */
"type": "simplified",
"data_source": "../data"
},
/* Optimization hyperparameters */
"compression": {
"target_device": "CPU",
"algorithms": [
{
"name": "DefaultQuantization",
"params": {
"preset": "performance",
"stat_subset_size": 300,
"shuffle_data": false
}
}
]
}
}
Finally, perform the model quantization. The resulting model will be saved in ./optimized folder:
pot -c quantization_spec.json --output-dir . -d
For the second model (FaceMesh), we just need to change the model name and the paths in the config accordingly and repeat the same command.
We can see that the quantized model size is drastically decreased compared to the full-precision floating-point models: 404kB -> 130kB for BlazeFace and 2.4MB -> 663kB for FaceMesh.
4. Benchmark Tool
OpenVINO toolkit provides yet another tool – Benchmark Application which may be used for quick inference and performance measurements on the target device. The tool is available in two versions: C++ and Python. We will continue to work with the Python environment as for the previous tools.
4.1 Installation and configuration
Before starting to use Benchmark Tool, we need to install the python dependencies:
cd <OPENVINO_INSTALL_DIR>/deployment_tools/tools/benchmark_tool/ pip install -r requirements.txt
4.2 Running model inference
In the simplest case, we can run the tool just specifying the model to be measured and the desired target device:
python benchmark_app.py -m ~/openvino_optimization/models/blazeface_fp32.xml -d CPU
The command output will contain the logs from all the execution steps, and the final step will contain performance measurements logs:
Count: 7292 iterations Duration: 60055.49 ms Latency: 32.82 ms Throughput: 121.42 FPS
4.3 Comparing the model performance
As stated in the Intel’s documentation for low-precision inference, in order to realize the benefits from OpenVINO INT8 quantization, we should use Intel hardware with at least one extension to x86 instruction set: AVX-512, AVX2, or SSE4.2. In this example, for the results below I used the Intel Core i5-3570K CPU with the SSE4.2 instruction set.
Let’s compare the measurement results received for our converted models:
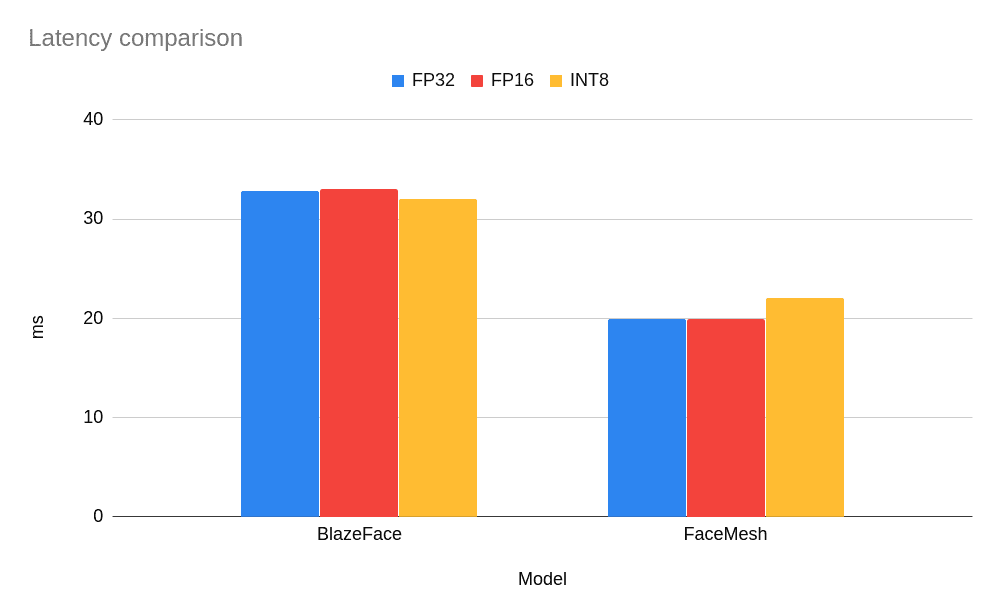
As you can see, for such small models there is no performance gain observed, and for the FaceMesh model low-precision INT8 model led to a slightly increased latency (i.e., it executed the task slower). But what about more classical and bigger networks, especially those validated for low-precision inference and deployed in OpenVINO Open Model Zoo? Let’s take a prepared model from the Model Zoo and compare benchmark results. Here are the results for face-detection-adas-0001 model based on MobileNet backbone:
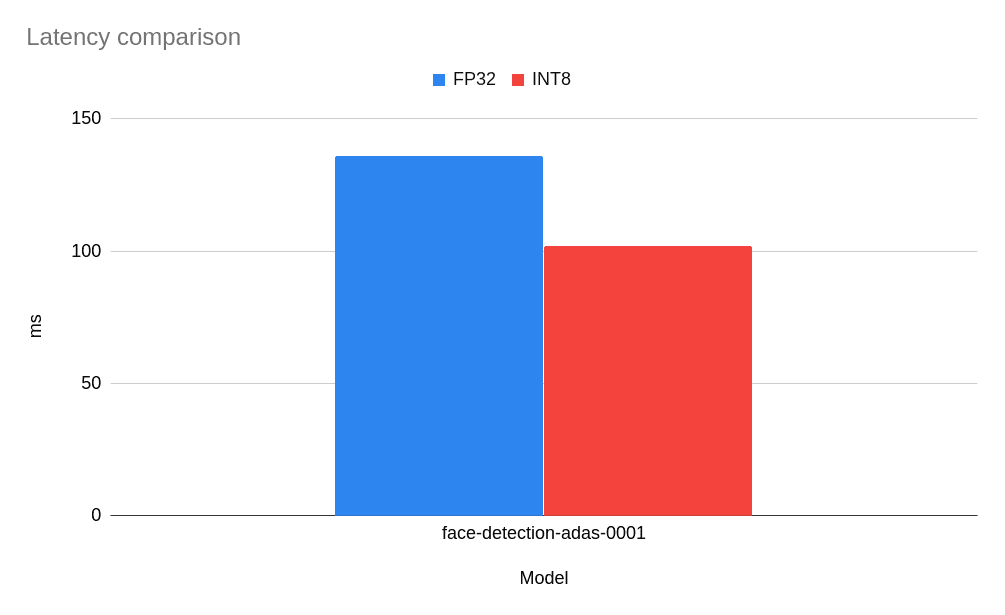
Well, for this model we can observe ~25% performance improvement. It is a good result, and we have a smaller model that provides faster inference.
Refer to https://software.intel.com/articles/optimization-notice for more information regarding performance and optimization choices in Intel software products.
4.4 Comparing the model accuracy
It is important to keep a sufficient accuracy thus the application can still fulfill the functional requirement. Let’s take the OpenVINO inference pipeline from the previous post and see what we can achieve with the optimizations. We need to replace the original models with models converted to FP16 and INT8 format.
Visually, FP32 and FP16 models have the same quality but INT8 models often deliver significantly worse results:
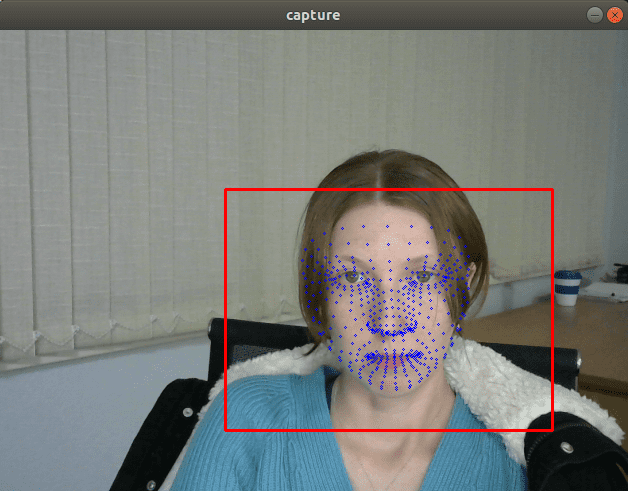
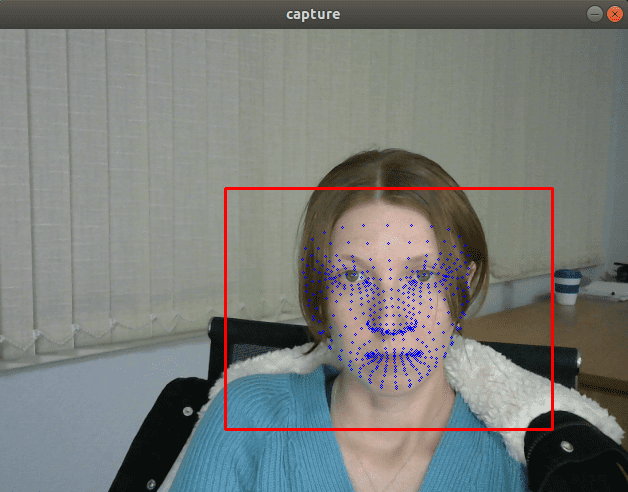
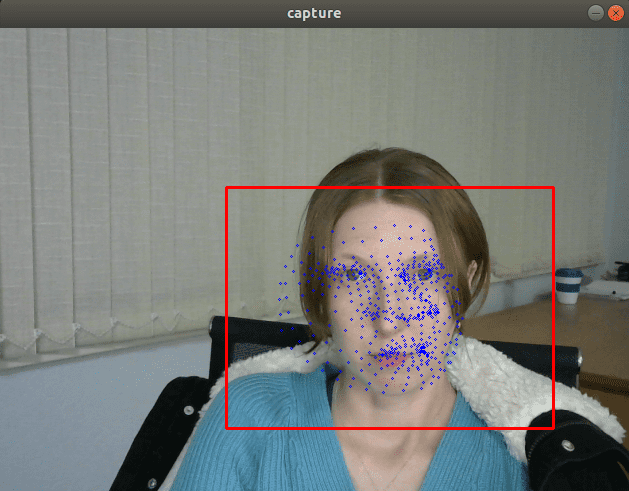
If we insert a debug trace that prints the model output, we’ll see that the values returned by the FP32 and FP16 models are almost the same, but values returned by INT8 models can be differed by more than 10% due the quantization errors.
I would say that the results are somewhat predictable as we have just used a simple version of DefaultQuantization that is not aimed at maximizing accuracy. To increase the accuracy in an INT8 model compression, we need to use the AccuracyAwareQuantization algorithm. It will require us to prepare an annotated dataset, run the quantization, and check the accuracy. I will leave this type of quantization out of the scope of this post.
5. Summary and Conclusions
We explored some of the features in the OpenVINO toolkit that optimized the execution speed of the DNN models inference. The tools allow you to strike the balance between performance and accuracy that would be needed for your applications. Of course, the speed up often turns into cost saving and often is a significant requirement for many real-time interactive applications.
Testing date: September 22, 2020
Complete system configuration details: Oracle VM VirtualBox, Ubuntu 18.04.5, Intel® Core™ i5-3570K CPU @ 3.40GHz × 4
Setup details: OpenVINO toolkit version 2020.4
Who did testing: Alexey Perminov, OpenCV.AI
Get the Intel® Distribution of OpenVINO™ toolkit
Contribute – If you have any ideas in ways we can improve the product, we welcome contributions to the open-sourced OpenVINO™ toolkit.
Want to learn more? Join the conversation to discuss all things Deep Learning and OpenVINO™ toolkit in Intel’s community forum.
Intel is committed to respecting human rights and avoiding complicity in human rights abuses. See Intel’s Global Human Rights Principles. Intel’s products and software are intended only to be used in applications that do not cause or contribute to a violation of an internationally recognized human right.
Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries.
OpenCV Content Partnership
This article was written by a member of the OpenCV team for Intel as part of OpenCV Content Partnership Program. This program allows companies to sponsor articles that are relevant to OpenCV users. The articles are shared with our newsletter subscribers and our social media subscribers.



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning