
Introduction
OpenCV has quietly become a cornerstone in the field of Computer Vision and image processing. This library, originally developed for academic and research purposes, is now integral to various real-world applications. OpenCV allows computers and machines to see and process images in a way that was once only theoretically possible, making it a key player in the tech industry.
This read will explore some of the most significant capabilities and real-world OpenCV applications. It is proving its worth in numerous fields, from the development of medical imaging to more efficient and safer autonomous vehicles.
Whether you’re in the tech industry, an avid tech enthusiast, or just curious about how OpenCV is changing the world around us, this exploration into the OpenCV applications will offer valuable insights into this fascinating area of technology.
If all of this is new to you, check out our fun blog that introduces you to Artificial Intelligence.
Table of Contents
Introduction
What is Computer Vision
Real World OpenCV Applications
What is Computer Vision?
Before we explore OpenCV, let us check out Computer Vision. Computer Vision is an innovative branch of Artificial Intelligence that’s revolutionizing how machines perceive and interact with the visual world. Computer Vision enables computers to replicate human sight, interpreting and understanding imagery from the world around us.
This technology leverages deep learning models to process images from cameras and videos. It allows machines to accurately identify, classify, and respond to objects they see.
Computer Vision has widespread applications ranging from autonomous vehicles (detecting road signs and pedestrians) to healthcare (analyzing medical images) and retail (enabling checkout-free shopping.
What is OpenCV?
Open Source Computer Vision, or OpenCV for short, took form in 1999 by Intel. It is a free cross-platform Computer Vision library for real-time image processing. The purpose? It is used for building Deep Learning and Machine Learning applications, predominantly for classical computer vision applications. With more than 2,500 optimized algorithms, including classic and state-of-the-art Computer Vision and Machine Learning algorithms, it is used in object detection, facial detection, 3D model extraction, and the list goes on. Although it was initially developed in C/C++, it is actively developed for Python, Matlab, Ruby, and other languages.

With over 18 million downloads and 47,000 community users, OpenCV is the go-to tool for anything related to computer vision, widely used by tech giants, researchers, and government bodies. OpenCV was natively written in C++ and offers cross-platform support.
The first OpenCV version was 1.0. OpenCV is released under a BSD license; hence, it’s free for academic and commercial use. It has C++, C, Python, and Java interfaces and supports Windows, Linux, Mac OS, iOS and Android. When OpenCV was designed, the main focus was real-time applications for computational efficiency. All things are written in optimized C/C++ to take advantage of multi-core processing.
Capabilities of OpenCV
In this section, we’ll explore some of the capabilities of OpenCV.
Reading, Writing, and Displaying Images
First and foremost, OpenCV excels in basic image-handling operations. Functions like `cv2.imread()`, `cv2.imwrite()`, and `cv2.imshow()` are the bedrock of OpenCV’s image processing capabilities. `cv2.imread()` lets you load an image from a file into a format suitable for analysis and manipulation. To save an image, `cv2.imwrite()` comes into play, allowing you to store your processed images. Lastly, `cv2.imshow()` is the function you need to display an image in a window, a critical step for visual verification in image processing tasks.
Video Processing
OpenCV’s video processing capabilities allow it to handle and manipulate video streams. Functions like frame capturing, video recording, and motion analysis enable developers to build sophisticated surveillance systems, traffic monitoring tools, and dynamic event analysis applications.
Image Thresholding
Image thresholding is a technique that focuses on objects and separates them from their background. OpenCV offers several methods for this, including binary, adaptive, and Otsu’s thresholding. This process is particularly useful in applications where identifying and focusing on specific areas of an image is crucial.
Rotating Images
Manipulating the orientation of images is a common requirement in image processing. OpenCV simplifies this with functions like `cv2.getRotationMatrix2D()` and `cv2.warpAffine()`, enabling you to rotate images to any desired angle. This flexibility is vital for aligning images correctly or preparing them for further analysis.
Edge Detection
Edge detection is a critical step in understanding the structure of objects within images. The Canny edge detector, implemented in OpenCV as `cv2.Canny()`, is a popular choice for this task. It helps highlight the outlines of objects, paving the way for advanced image segmentation, object detection, and feature recognition.
Check out this read to get started with Edge Detection using OpenCV.

Contour Detection
Contour detection is another powerful feature of OpenCV, used to find the continuous lines or curves that form the boundary of objects. The `cv2.findContours()` function is instrumental in object recognition and localization. Analyzing objects’ shape and size opens up many possibilities in Computer Vision applications.
Image Processing
Image processing is a broad term encompassing various techniques used to enhance and manipulate images. OpenCV offers a wide range of functions for image transformations, color space conversions, and filtering. These processes are fundamental in preparing images for analysis, improving their quality, or extracting useful information.
Image Segmentation
Image segmentation is the process of partitioning an image into multiple segments, making it easier to analyze. OpenCV facilitates this through methods like watershed segmentation and clustering. This feature is crucial in medical imaging, autonomous driving, and any application where understanding the context of separate image regions is key.
Object Detection
Object detection is a cornerstone of Computer Vision, where specific objects within an image are identified and located. OpenCV supports various object detection algorithms, including Haar cascades and deep learning-based models. These tools are essential in fields like surveillance, retail, and robotics.
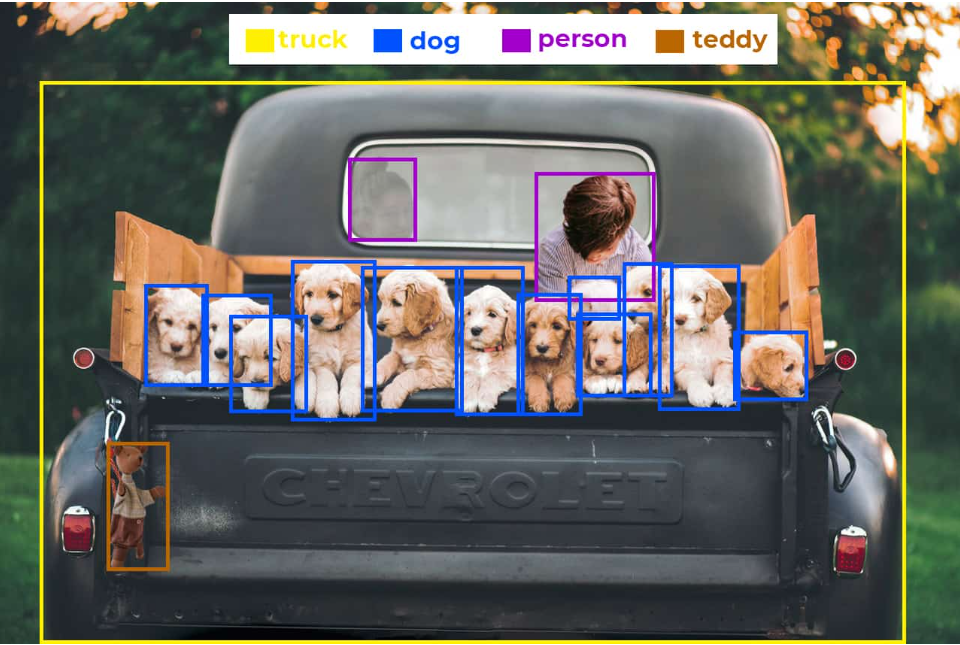
As seen, OpenCV offers an array of functions for effective image processing and analysis.
Real-world OpenCV Applications
Medical Imaging
In the healthcare sector, OpenCV’s advanced image processing capabilities are revolutionizing diagnostic methods and patient care. Beyond basic image analysis, OpenCV implementations are increasingly being used for real-time monitoring of patient vitals through non-invasive techniques, such as analyzing skin color changes for heart rate monitoring.
Some health conditions like cancer, pneumonia, or osteoporosis have higher mortality rates. Add it to delayed diagnosis, which can have a bad effect on a patient’s recovery. Effective and speedy treatment is also an important aspect of treating a disease.
Let us take the instance of 3D visualization.
These advanced imaging modalities and sophisticated computer reconstruction techniques have opened up new medical diagnosis and treatment possibilities.
One of the most notable advancements in the field of medical imaging is the ability to visualize and analyze multi-dimensional medical volume image data in a more comprehensive and detailed manner, which has been instrumental in enhancing the precision and effectiveness of medical diagnoses and treatments.
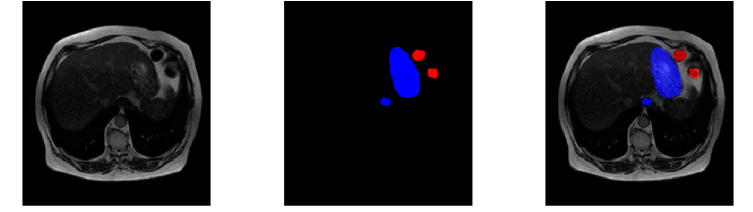
The tools available in 3D image processing are extensive, offering functionalities such as accurate 3D volume calculation, meticulous measurement, and in-depth quantitative analysis. Another key aspect of this technological evolution is the creation of detailed 3D models of patients, automatically generated by identifying and extracting anatomical structures from medical imaging data. This process not only aids in accurate diagnoses but also facilitates the planning and simulation of surgical procedures. The use of these 3D models in pre-surgical planning significantly improves the outcomes by allowing surgeons to rehearse and strategize complex surgical interventions.
Furthermore, integrating augmented reality (AR) in medical imaging marks a groundbreaking development in the field. AR capabilities enable merging pre-operative or intra-operative data with the real-world environment. This fusion of virtual and real-world elements is particularly beneficial in image-guided surgery, where surgeons can navigate surgical procedures with enhanced visibility and precision.
OpenCV, a pivotal tool in radiology, is revolutionizing medical imaging through classical Computer Vision techniques. It enhances image quality, diagnosis accuracy, and workflow efficiency in an increasingly data-driven field. AI’s integration into radiology has been transformative, particularly in MRI procedures where accuracy and efficiency are crucial.
OpenCV’s integration into GE Healthcare’s Edison™ Ecosystem showcases its expanding role in healthcare. This platform facilitates the scalable development and deployment of AI applications in healthcare workflows, underscoring OpenCV’s significance in enhancing operational efficiencies, clinical outcomes, and patient care in medical imaging.



Autonomous Vehicles
In the automotive sector, OpenCV is revolutionizing safety and autonomous technology. Far beyond basic object detection and lane recognition, it’s pivotal in advanced systems like adaptive cruise control. This system, using camera input, dynamically adjusts vehicle speed according to traffic conditions. OpenCV’s role is also critical in autonomous vehicles for real-time environmental perception and decision-making. It handles complex tasks essential for the safe operation of self-driving cars, including pedestrian intent prediction, hazard anticipation, and navigation under various weather and lighting conditions.

OpenCV, with a few Deep Learning techniques, is transforming traffic monitoring and vehicle management. This technology excels in detecting moving vehicles in video streams, estimating their speed in real-time, and accurately identifying their number plates through advanced Computer Vision techniques.
These techniques can be used efficiently to detect and localize vehicles in video frames. These ensure precise, continuous vehicle monitoring.
In situations requiring number plate recognition, OCR (Optical Character Recognition) algorithms are employed for accurate character discernment on plates. This enables specific vehicle identification or alerts for various situations.
The system’s versatility, powered by OpenCV, allows operation across diverse hardware platforms – from desktops and embedded devices to cloud servers. This adaptability makes it suitable for a range of applications, including traffic monitoring, parking management, and law enforcement, significantly enhancing vehicle detection, speed estimation, and number plate recognition efficiency and accuracy.
Tesla is one such automotive company incorporating this.
Tesla Autopilot is a cutting-edge driving assistance system combining sensors and cameras. This system provides a 360-degree view of the vehicle, enabling it to detect nearby objects and vehicles effectively. The core of Autopilot’s functionality lies in its sophisticated software, which is continually updated to enhance its capabilities.
The software utilizes several components:
- Convolutional Neural Networks (CNNs) for real-time image recognition and analysis.
- Object Detection using methods like HOG and advanced deep learning techniques such as YOLO and R-CNN to identify and track objects.
- Optical Flow to estimate object movement, assisting in vehicle control.
- Lane Detection using techniques like Hough transforms for tracking road lanes.
- Semantic segmentation is used for differentiating between various objects and road features.
These algorithms enable the Autopilot system to make informed, real-time driving decisions, including acceleration, braking, and steering.
Key features of Tesla Autopilot include:
- Speed and Direction Control: Keeping the car centered in its lane and maintaining a safe distance from the vehicle in front.
- Automatic Lane Changes: Assessing traffic conditions for safe lane changes with driver control resumption post-maneuver.
- Advanced Safety Technologies: Incorporating automatic emergency braking, forward collision warning, and side collision warning, all powered by machine learning algorithms for hazard detection and driver alerts.
Overall, Tesla Autopilot represents a significant step forward in automotive technology, providing drivers with unparalleled assistance and safety thanks to its comprehensive sensor suite, powerful onboard computer, and advanced algorithm-based software.
Face Recognition with OpenCV
Face recognition is another application in the realm of Computer Vision aimed at recognizing human faces within images or videos. This technique hinges on analyzing visual inputs to ascertain the presence of facial features, a task made challenging due to the immense diversity of human faces. To ensure accuracy, face recognition models undergo extensive training with vast datasets encompassing a wide array of backgrounds, genders, and cultures.

The complexity of this task is further amplified by the need for these algorithms to adapt to various lighting conditions, angles, and orientations. These factors are crucial for the models to make accurate predictions in real-world situations. Developing such a model is a demanding endeavor, involving numerous hours of training and processing millions of data samples to achieve the desired level of precision and reliability.
Let us explore the remarkable achievements of Amadeus in the realm of biometric solutions. The crux of this development centers around the successful implementation of facial recognition technology for flights operated by Adria Airways, Air France, and LOT Polish Airlines at Ljubljana airport.
As the aviation industry grapples with ever-increasing passenger volumes, traditional airport infrastructures are nearing their operational limits. This challenge manifests in longer queues and potential delays, calling for a timely and effective solution. Biometric technology, recognized for its vast potential, promises not only to expedite airport processes for travelers but also to introduce efficiency and convenience in air travel.
The role of this technology is twofold. For airports, it’s about enhancing the service quality for airline partners. This is achieved by alleviating bottlenecks and enabling ground-handling staff to redirect their focus toward more customer-centric tasks. On the other hand, airlines stand to gain from the increased operational efficiency and quicker turnaround times for flights – a crucial factor in maintaining schedules and passenger satisfaction.
A pivotal moment in this journey was the undertakings of a pilot at Ljubljana Airport. Here, Amadeus took a significant stride towards establishing a unified, centralized platform for biometric solutions across the industry. Collaborating with Adria Airways and LOT Polish Airlines, the pilot involved 175 passengers who experienced an exceptionally swift boarding process. This marked a milestone for Amadeus and set a new standard in passenger boarding efficiency, heralding a future where air travel is faster, smoother, and more enjoyable for everyone involved.
Looking for something a little more advanced? Check out an interesting read on the different Face Recognition Models, toolkits, and datasets.
Defect Detection
In the manufacturing industry, Computer Vision, particularly through OpenCV with other Deep Learning techniques, has become a cornerstone for defect detection, significantly enhancing quality control. This involves key techniques: object recognition, detection, and tracking, each vital in defect identification.
Object Tracking
Used in dynamic production lines, this method monitors moving items for defects, ensuring accuracy in high-speed environments like bottling plants and automotive assembly lines and guaranteeing product integrity and safety.

In infrastructure inspection and maintenance, the introduction of advanced AI technologies, like the one developed by Toshiba Corporation, marks a significant leap forward. This AI, designed to identify anomalies such as cracks, rust, leaks, and foreign material adhesion, operates with minimal real-world training, relying instead on a few reference images. This approach simplifies the traditionally labor-intensive and often hazardous inspection processes, especially in challenging environments like mountainous steel towers, under bridges, or amidst solar panels.
The core of Toshiba’s AI lies in its utilization of pre-trained deep learning models. These models compare inspection photographs against reference images, negating the need for extensive real-world training typical in conventional AI applications. A standout feature is the AI’s proprietary correction technology. This advancement enables high-accuracy anomaly detection, even when inspection photos are taken from angles different from the reference images, while also minimizing false positives. This AI has achieved a remarkable 91.7% accuracy in tests, a record in its field.
Grappling with aging infrastructure and a dwindling workforce of inspectors, Japan represents a prime example of where such AI can revolutionize maintenance practices. The early detection of anomalies, often unspecified, is crucial for efficient infrastructure management. If these can be detected automatically through photographs taken by drones or robots, the inspection workload is significantly reduced.
While conventional methods for detecting anomalies like cracks and rust involve extensive image-based training, Toshiba’s AI transcends these limitations, addressing a broader range of anomalies. The technology compares images using deep learning features from pre-trained models, creating a score map of detected anomalies. Its ability to correct anomaly score maps limits false positives, a common issue in previous technologies, thus reducing the need for follow-up site inspections.
With its exceptional accuracy and minimal training requirement, Toshiba’s AI is a groundbreaking tool for safer, more efficient infrastructure maintenance. It demonstrates the potential of AI in revolutionizing traditional practices, particularly in challenging and hazardous environments.
Object Recognition
This technique classifies defects in product images, discerning types like dents, scratches, or rust in metal fabrication, and various flaws in textiles. It answers, “What is the defect?”
Object Detection
Crucial in pinpointing defect locations, it’s instrumental in electronics for identifying misplaced components and essential in the food industry for detecting contaminants.
Document Transcription
In today’s digital world, Optical Character Recognition (OCR) stands out as a pivotal tool in processing image-based data. OCR applications, widely recognized as image-to-text converters, facilitate the swift transformation of images into text, outpacing traditional manual conversion methods. These apps employ sophisticated algorithms to decipher image files, turning them into editable text documents – a boon for digitizing and editing text trapped within images.

OCR’s versatility extends to various languages like Spanish, Korean, and Mandarin, enhancing its global applicability. Its integration with other OCR systems enables the fusion of text extraction with image processing, yielding high-quality, logical documents. This capability proves invaluable in critical fields such as legal document analysis, where accuracy is paramount.
Moreover, when used alongside other scanning technologies, OCR ensures high security for digital documents, safeguarding them against unauthorized alterations. This feature is especially crucial for businesses handling sensitive customer data, offering an added layer of protection. OCR offers a comprehensive solution that enhances data integrity and security in diverse applications.
In the current digital day and age, where document management has become crucial for all businesses, Adobe Acrobat leverages OCR tech:
- Scanning: The journey begins when you scan a document or capture an image with text. This creates a digital canvas for Acrobat’s OCR to work on.
- Spotting the Text: Acrobat’s OCR is like a detective, identifying text-laden areas in your scan. It smartly discerns lines and individual characters, setting the stage for the magic of recognition.
- Deciphering Characters: Now comes the core – character recognition. Adobe Acrobat isn’t just recognizing shapes; it’s understanding them as letters and numbers across various styles and fonts. It’s a complex algorithmic ballet, where every character shape is matched to its corresponding letter or digit.
- Understanding Context: Acrobat’s OCR is more than a mere shape recognizer. It delves into the context, accurately piecing words and sentences together. This step is crucial, especially for documents where text clarity isn’t at its best.
- Transforming into Editable Text: Post-recognition, the text morphs into a digital format that’s ripe for editing. Now, you can easily manipulate, format, and search through the content.
- Language Versatility: The tool’s multilingual support is a boon, making it a versatile choice for global users.
- Navigating Through Accuracy and Limitations: While Acrobat’s OCR is powerful, its efficiency hinges on scan quality and text complexity. Clear, printed text works best, whereas handwritten notes may pose a challenge.
- Fine-tuning with Post-OCR Tools: After OCR does its part, you can step in to make corrections. Acrobat offers tools to tweak and fine-tune the text, ensuring your document is as accurate as possible.

Adobe Acrobat’s OCR feature is game-changing in document digitization, making your information more accessible and manageable.
Where do I begin?
If you’re fascinated by the world of computer vision and image processing, OpenCV University is your gateway to endless possibilities. One of the prerequisites is a basic understanding of any language like Python or C/C++. This powerful library, known for its comprehensive set of tools and functionalities, can seem daunting at first.
But fear not! We have loads of resources to master OpenCV. You can kick off things with our Fee OpenCV Bootcamp, which covers 14 modules and is taken by over 21,000 learners worldwide. One of the prerequisites is a basic understanding of any language like Python or C/C++. You can check out our Free Python Bootcamp, which will get you up and running with Python.
Conclusion
From its humble beginnings to becoming a robust toolkit for image processing, machine learning, and computer vision, OpenCV’s journey is a testament to its adaptability and commitment to innovation. As it evolved from a C-based architecture to embracing modern C++ and deep learning, OpenCV has consistently proved to be a powerful, efficient, and user-friendly tool for developers and researchers around the globe.
OpenCV’s extensive set of tools and functions make it an invaluable resource in the ever-evolving field of Computer Vision. From basic image handling to complex applications like AR and face recognition, OpenCV continues to be a key driver in innovative technology solutions. Stay tuned for our upcoming posts as we delve deeper into the realm of AI, Deep Learning, and Computer Vision. See you guys in the next one!





5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning