


The advancement of computer vision, a field blending machine learning with computer science, has been significantly uplifted by the emergence of deep learning. This article on deep learning for computer vision explores the transformative journey from traditional computer vision methods to the innovative heights of deep learning.
We begin with an overview of foundational techniques like thresholding and edge detection and the critical role of OpenCV in traditional approaches.
Brief History and Evolution of Traditional Computer Vision
Computer vision, a field at the intersection of machine learning and computer science, has its roots in the 1960s when researchers first attempted to enable computers to interpret visual data. The journey began with simple tasks like distinguishing shapes and progressed to more complex functions. Key milestones include the development of the first algorithm for digital image processing in the early 1970s and the subsequent evolution of feature detection methods. These early advancements laid the groundwork for modern computer vision, enabling computers to perform tasks ranging from object detection to complex scene understanding.
Core Techniques in Traditional Computer Vision
Thresholding: This technique is fundamental in image processing and segmentation. It involves converting a grayscale image into a binary image, where pixels are marked as either foreground or background based on a threshold value. For instance, in a basic application, thresholding can be used to distinguish an object from its background in a black-and-white image.
Edge Detection: Critical in feature detection and image analysis, edge detection algorithms like the Canny edge detector identify the boundaries of objects within an image. By detecting discontinuities in brightness, these algorithms help understand the shapes and positions of various objects in the image, laying the foundation for more advanced analysis.
Find here the list of the TOP Computer Vision and Deep Learning Courses from OpenCV University.
The Dominance of OpenCV
OpenCV (Open Source Computer Vision Library) is a key player in computer vision, offering over 2500 optimized algorithms since the late 1990s. Its ease of use and versatility in tasks like facial recognition and traffic monitoring have made it a favorite in academia and industry, especially in real-time applications.
The field of computer vision has evolved significantly with the advent of deep learning, shifting from traditional, rule-based methods to more advanced and adaptable systems. Earlier techniques, such as thresholding and edge detection, had limitations in complex scenarios. Deep learning, particularly Convolutional Neural Networks (CNNs), overcomes these by learning directly from data, allowing for more accurate and versatile image recognition and classification.
This advancement, propelled by increased computational power and large datasets, has led to significant breakthroughs in areas like autonomous vehicles and medical imaging, making deep learning a fundamental aspect of modern computer vision.
Deep Learning Models:
ResNet-50 for Image Classification
ResNet-50 is a variant of the ResNet (Residual Network) model, which has been a breakthrough in the field of deep learning for computer vision, particularly in image classification tasks. The “50” in ResNet-50 refers to the number of layers in the network – it contains 50 layers deep, a significant increase compared to previous models.
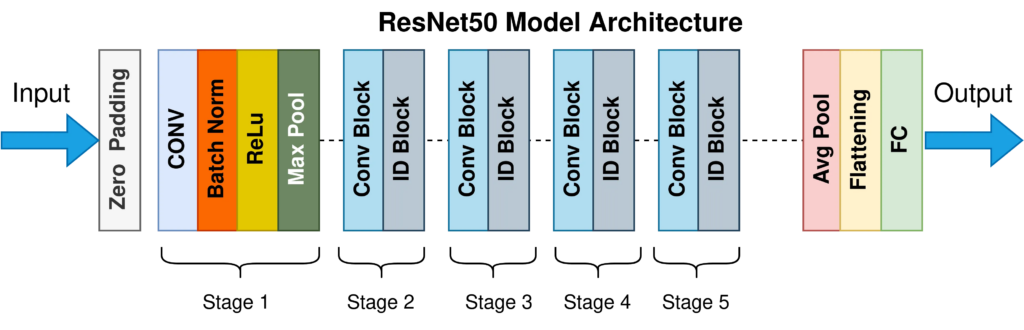
Key Features of ResNet-50:
1. Residual Blocks: The core idea behind ResNet-50 is its use of residual blocks. These blocks allow the model to skip one or more layers through what are known as “skip connections” or “shortcut connections.” This design addresses the vanishing gradient problem, a common issue in deep networks where gradients get smaller and smaller as they backpropagate through layers, making it hard to train very deep networks.
2. Improved Training: Thanks to these residual blocks, ResNet-50 can be trained much deeper without suffering from the vanishing gradient problem. This depth enables the network to learn more complex features at various levels, which is a key factor in its improved performance in image classification tasks.
3. Versatility and Efficiency: Despite its depth, ResNet-50 is relatively efficient in terms of computational resources compared to other deep models. It achieves excellent accuracy on various image classification benchmarks like ImageNet, making it a popular choice in the research community and industry.
4. Applications: ResNet-50 has been widely used in various real-world applications. Its ability to classify images into thousands of categories makes it suitable for tasks like object recognition in autonomous vehicles, content categorization in social media platforms, and aiding diagnostic procedures in healthcare by analyzing medical images.
Impact on Computer Vision:
ResNet-50 has significantly advanced the field of image classification. Its architecture serves as a foundation for many subsequent innovations in deep learning and computer vision. By enabling the training of deeper neural networks, ResNet-50 opened up new possibilities in the accuracy and complexity of tasks that computer vision systems can handle.
YOLO (You Only Look Once) Model
The YOLO (You Only Look Once) model is a revolutionary approach in the field of computer vision, particularly for object detection tasks. YOLO stands out for its speed and efficiency, making real-time object detection a reality.
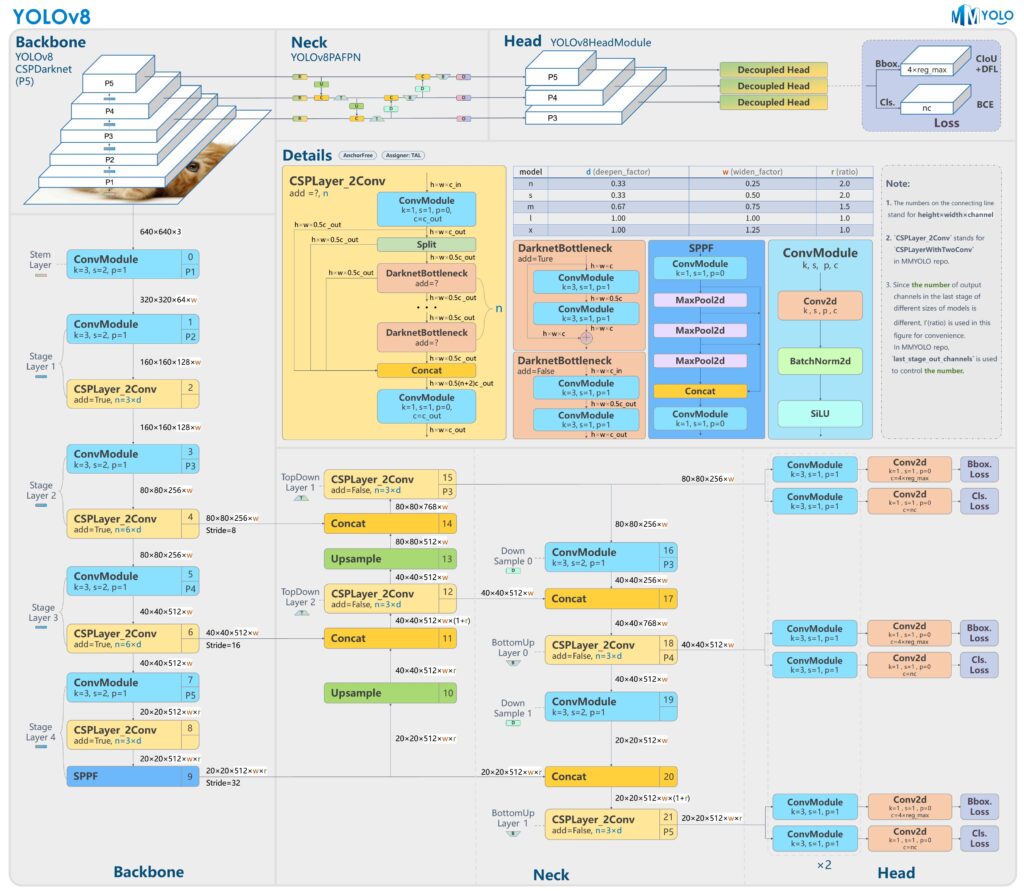
Key Features of YOLO
Single Neural Network for Detection: Unlike traditional object detection methods which typically involve separate steps for generating region proposals and classifying these regions, YOLO uses a single convolutional neural network (CNN) to do both simultaneously. This unified approach allows it to process images in real-time.
Speed and Real-Time Processing: YOLO’s architecture allows it to process images extremely fast, making it suitable for applications that require real-time detection, such as video surveillance and autonomous vehicles.
Global Contextual Understanding: YOLO looks at the entire image during training and testing, allowing it to learn and predict with context. This global perspective helps in reducing false positives in object detection.
Version Evolution: Recent iterations such as YOLOv5, YOLOv6, YOLOv7, and the latest YOLOv8, have introduced significant improvements. These newer models focus on refining the architecture with more layers and advanced features, enhancing their performance in various real-world applications.
Impact on Computer Vision
YOLO’s contribution to the field of deep learning for computer vision has been significant. Its ability to perform object detection in real-time, accurately, and efficiently has opened up numerous possibilities for practical applications that were previously limited by slower detection speeds. Its evolution over time also reflects the rapid advancement and innovation within the field of deep learning in computer vision.
Real-World Applications of YOLO
Traffic Management and Surveillance Systems: A pertinent real-world application of the YOLO model is in the domain of traffic management and surveillance systems. This application showcases the model’s ability to process visual data in real time, a critical requirement for managing and monitoring urban traffic flow.
Implementation in Traffic Surveillance: Vehicle and Pedestrian Detection – YOLO is employed to detect and track vehicles and pedestrians in real-time through traffic cameras. Its ability to process video feeds quickly allows for the immediate identification of different types of vehicles, pedestrians, and even anomalies like jaywalking.
Traffic Flow Analysis: By continuously monitoring traffic, YOLO helps in analyzing traffic patterns and densities. This data can be used to optimize traffic light control, reducing congestion and improving traffic flow.
Accident Detection and Response: The model can detect potential accidents or unusual events on roads. In case of an accident, it can alert the concerned authorities promptly, enabling faster emergency response.
Enforcement of Traffic Rules: YOLO can also assist in enforcing traffic rules by detecting violations like speeding, illegal lane changes, or running red lights. Automated ticketing systems can be integrated with YOLO to streamline enforcement procedures.
Vision Transformers
This model applies the principles of transformers, originally designed for natural language processing, to image classification and detection tasks. It involves splitting an image into fixed-size patches, embedding these patches, adding positional information, and then feeding them into a transformer encoder.
The model uses a combination of Multi-head Attention Networks and Multi-Layer Perceptrons within its architecture to process these image patches and perform classification.
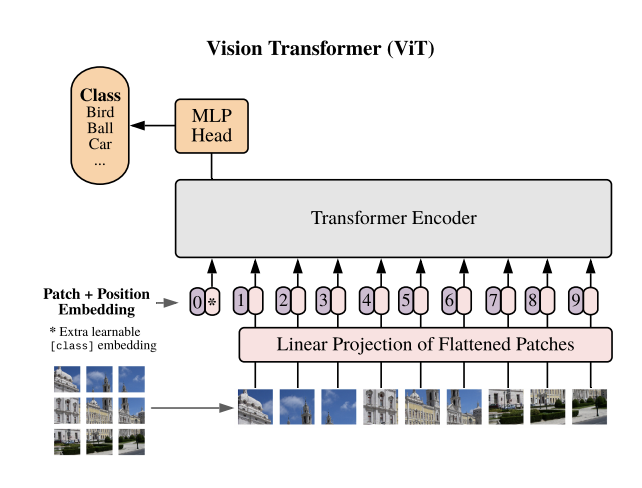
Key Features
Patch-based Image Processing: ViT divides an image into patches and linearly embeds them, treating the image as a sequence of patches.
Positional Embeddings: To maintain the spatial relationship of image parts, positional embeddings are added to the patch embeddings.
Multi-head Attention Mechanism: It utilizes a multi-head attention network to focus on critical regions within the image and understand the relationships between different patches.
Layer Normalization: This feature ensures stable training by normalizing the inputs across the layers.
Multilayer Perceptron (MLP) Head: The final stage of the ViT model, where the outputs of the transformer encoder are processed for classification.
Class Embedding: ViT includes a learnable class embedding, enhancing its capability to classify images accurately.
Impact on Computer Vision
Enhanced Accuracy and Efficiency: ViT models have demonstrated significant improvements in accuracy and computational efficiency over traditional CNNs in image classification.
Adaptability to Different Tasks: Beyond image classification, ViTs are effectively applied in object detection, image segmentation, and other complex vision tasks.
Scalability: The patch-based approach and attention mechanism make ViT scalable for processing large and complex images.
Innovative Approach: By applying the transformer architecture to images, ViT represents a paradigm shift in how machine learning models perceive and process visual information.
The Vision Transformer marks a significant advancement in the field of computer vision, offering a powerful alternative to conventional CNNs and paving the way for more sophisticated image analysis techniques.
Vision Transformers (ViTs) are increasingly being used in a variety of real-world applications across different fields due to their efficiency and accuracy in handling complex image data.
Real World Applications
Image Classification and Object Detection: ViTs are highly effective in image classification, categorizing images into predefined classes by learning intricate patterns and relationships within the image. In object detection, they not only classify objects within an image but also localize their positions precisely. This makes them suitable for applications in autonomous driving and surveillance, where accurate detection and positioning of objects are crucial.
Image Segmentation: In image segmentation, ViTs divide an image into meaningful segments or regions. They excel in discerning fine-grained details within an image and accurately delineating object boundaries. This capability is particularly valuable in medical imaging, where precise segmentation can aid in diagnosing diseases and conditions.
Action Recognition: ViTs are being utilized in action recognition to understand and classify human actions in videos. Their robust image processing capabilities, makes them useful in areas such as video surveillance and human-computer interaction.
Generative Modeling and Multi-Modal Tasks: ViTs have applications in generative modeling and multi-modal tasks, including visual grounding (linking textual descriptions to corresponding image regions), visual-question answering, and visual reasoning. This reflects their versatility in integrating visual and textual information for comprehensive analysis and interpretation.
Transfer Learning: An important feature of ViTs is their capacity for transfer learning. By leveraging pre-trained models on large datasets, ViTs can be fine-tuned for specific tasks with relatively small datasets. This significantly reduces the need for extensive labeled data, making ViTs practical for a wide range of applications.
Industrial Monitoring and Inspection: In a practical application, the DINO pre-trained ViT was integrated into Boston Dynamics’ Spot robot for monitoring and inspection of industrial sites. This application showcased the ability of ViTs to automate tasks like reading measurements from industrial processes and taking data-driven actions, demonstrating their utility in complex, real-world environments.
Stable Diffusion V2: Key Features and Impact on Computer Vision

Key Features of Stable Diffusion V2
Advanced Text-to-Image Models: Stable Diffusion V2 incorporates robust text-to-image models, utilizing a new text encoder (OpenCLIP) that enhances the quality of generated images. These models can produce images with resolutions like 512×512 pixels and 768×768 pixels, offering significant improvements over previous versions.
Super-resolution Upscaler: A notable addition in V2 is the Upscaler Diffusion model that can increase the resolution of images by a factor of 4. This feature allows for converting low-resolution images into much higher-resolution versions, up to 2048×2048 pixels or more when combined with text-to-image models.
Depth-to-Image Diffusion Model: This new model, known as depth2img, extends the image-to-image feature from the earlier version. It can infer the depth of an input image and then generate new images using both text and depth information. This feature opens up possibilities for creative applications in structure-preserving image-to-image and shape-conditional image synthesis.
Enhanced Inpainting Model: Stable Diffusion V2 includes an updated text-guided inpainting model, allowing for intelligent and quick modification of parts of an image. This makes it easier to edit and enhance images with high precision.
Optimized for Accessibility: The model is optimized to run on a single GPU, making it more accessible to a wider range of users. This optimization reflects a commitment to democratizing access to advanced AI technologies.
Impact on Computer Vision
Revolutionizing Image Generation: Stable Diffusion V2’s enhanced capabilities in generating high-quality, high-resolution images from textual descriptions represent a leap forward in computer-generated imagery. This opens new avenues in various fields like digital art, graphic design, and content creation.
Facilitating Creative Applications: With features like depth-to-image and upscaling, Stable Diffusion V2 enables more complex and creative applications. Artists and designers can experiment with depth information and high-resolution outputs, pushing the boundaries of digital creativity.
Improving Image Editing and Manipulation: The advanced inpainting capabilities of Stable Diffusion V2 allow for more sophisticated image editing and manipulation. This can have practical applications in fields like advertising, where quick and intelligent image modifications are often required.
Enhancing Accessibility and Collaboration: By optimizing the model for single GPU use, Stable Diffusion V2 becomes accessible to a broader audience. This democratization could lead to more collaborative and innovative uses of AI in visual tasks, fostering a community-driven approach to AI development.
Setting a New Benchmark in AI: Stable Diffusion V2’s combination of advanced features and accessibility may set new standards in the AI and computer vision community, encouraging further innovations and applications in these fields.
Real-world Applications:
Medical and Health Education: MultiMed, a health technology company, uses Stable Diffusion technology to provide accessible and accurate medical guidance and public health education in multiple languages.
Audio Transcription and Image Generation: AudioSonic project transforms audio narratives into images, enhancing the listening experience with corresponding visuals.
Interior Design: A web application utilizes Stable Diffusion to empower individuals with AI in home design, allowing customers to create and visualize interior designs quickly and efficiently.
Comic Book Production: AI-Comic-Factory combines Falcon AI and SDXL technology with Stable Diffusion to revolutionize comic book production, enhancing both narratives and visuals.
Educational Summarization Tool: Summerize, a web application, offers structured information retrieval and summarization from online articles, along with relevant image prompts, aiding research and presentations.
Interactive Storytelling in Gaming: SonicVision integrates generative music and dynamic art with storytelling, creating an immersive gaming experience.
Cooking and Recipe Generation: DishForge uses Stable Diffusion to visualize ingredients and generate personalized recipes based on user preferences and dietary needs.
Marketing and Advertising: EvoMate, an autonomous marketing agent, creates targeted campaigns and content, leveraging Stable Diffusion for content creation.
Podcast Fact-Checking and Media Enhancement: TrueCast uses AI algorithms for real-time fact-checking and media presentation during live podcasts.
Personal AI Assistants: Projects like Shadow AI and BlaBlaLand use Stable Diffusion for generating relevant images and creating immersive, personalized AI interactions.
3D Meditation and Learning Platforms: Applications like 3D Meditation and PhenoVis utilize Stable Diffusion for creating immersive meditation experiences and educational 3D simulations.
AI in Medical Education: Patient Simulator aids medical professionals in practicing patient interactions, using Stable Diffusion for enhanced communication and training.
Advertising Production Efficiency: ADS AI aims to improve advertising production time by using AI technologies, including Stable Diffusion, for creative product image and content generation.
Creative Content and World Building: Platforms like Text2Room and The Universe use Stable Diffusion for generating 3D content and immersive game worlds.
Enhanced Online Meetings: Baatcheet.AI revolutionizes online meetings with voice cloning and AI-generated backgrounds, improving focus and communication efficiency.
These applications demonstrate the versatility and potential of Stable Diffusion V2 in enhancing various industries by providing innovative solutions to complex problems.
Popular Frameworks – PyTorch and Keras
PyTorch

Developed by Facebook’s AI Research lab, PyTorch is an open-source machine learning library. It’s known for its flexibility, ease of use, and native support for dynamic computation graphs, which makes it particularly suitable for research and prototyping. PyTorch also provides strong support for GPU acceleration, which is essential for training large neural networks efficiently.
Checkout: Getting started with Pytorch.
Keras

Keras, now integrated with TensorFlow (Google’s AI framework), is a high-level neural networks API designed for simplicity and ease of use. Initially developed as an independent project, Keras focuses on enabling fast experimentation and prototyping through its user-friendly interface. It supports all the essential features needed for building deep learning models but abstracts away many of the complex details, making it very accessible for beginners.
Checkout: Getting started with Keras
Both frameworks are extensively used in both academic and industrial settings for a variety of machine learning and AI applications, from simple regression models to complex deep neural networks.
PyTorch is often preferred for research and development due to its flexibility, while Keras is favored for its simplicity and ease of use, especially for beginners.
Conclusion: The Ever-Evolving Landscape of AI Models
As we look towards the future of AI and machine learning, it’s crucial to acknowledge that one model does not fit all. Even a decade from now, we might still see the use of classic models like ResNet alongside contemporary ones like Vision Transformers or Stable Diffusion V2.
The field of AI is characterized by continuous evolution and innovation. It reminds us that the tools and models we use must adapt and diversify to meet the ever-changing demands of technology and society.




