

Introduction
One field that has seen a boom in recent times is Artificial Intelligence. By leveraging Artificial Intelligence tech, machines can accomplish a ton of tasks, ranging from applying snap filters to your pictures to self-driving cars. Two other terms that are used interchangeably and frequently with Artificial Intelligence are Machine Learning and Deep Learning. What are Machine Learning and Deep Learning? Do they mean the same thing? Or are they completely different from each other? Or are they related?
This comprehensive, fun read will restate these questions as we explore Deep Learning vs Machine Learning.
What is Machine Learning?
Before we tackle the age-old question of Machine Learning vs. Deep Learning, let’s briefly understand their definitions.
Machine Learning, or ML, is a subfield of Artificial Intelligence that revolves around developing computer algorithms by leveraging data. They facilitate machines to make decisions or predictions by analyzing and making inferences from data.
Much like how humans gain knowledge by understanding inputs, Machine Learning aims to make decisions from input data. The powerhouse behind machine learning is Algorithms.
Different Machine Learning Algorithms can be used depending on the structure and volume of data.
What is Deep Learning?
Deep Learning is a subfield of Machine Learning that leverages neural networks to replicate the workings of a human brain on machines. Neurons are configured in neural networks based on training from large amounts of data. Much like the algorithms are the powerhouses behind Machine Learning, Deep Learning has Models. These models take information from multiple data sources and analyze that data in real-time.
A Deep Learning model constitutes nodes that form layers in neural networks. Information is passed through each layer, trying to understand the information and identify patterns.
A Deep learning model can create simpler and more efficient categories from difficult-to-understand datasets since it can identify both higher-level and lower-level information.
Before they go head to head, let us look at the most common Machine Learning algorithms in use.
Most common Machine Learning Algorithms
Algorithms serve as a foundation in Machine Learning, which Data Scientists and Big Data Engineers can leverage to classify, predict, and gain insights from data.
In this section, we’ll discuss some of the most commonly used Machine Learning Algorithms.
Linear Regression
It is an algorithm used in data science and machine learning that offers a linear relationship between a dependent variable and an independent variable to predict the outcome of future events.
While the dependent variable changes with fluctuations in the independent variable, the independent variable remains unchanged with changes in other variables. The model predicts the value of the dependent variable which is being analyzed.
Linear Regression simulates a mathematical relationship between variables and makes predictions for numeric variables or continuous variables, for instance, price, sales, or salary.
Why use a Linear Regression Algorithm?
- It can handle large datasets effectively.
- It serves as a good foundational model for complex ML algorithm comparisons.
- It is easy to understand and implement.
With its ease of use and efficiency, LinearRegression is a fundamental machine learning algorithm that one must have in their arsenal.
Logistic Regression
What if a dataset has many features? How do we classify them? This is where Logistic Regression comes into play. Logistic Regression is a form of supervised learning that can predict the probability of certain classes based on some dependent variables. Simply put, it analyzes the relationship between variables. Since it predicts the output of a discrete value, it gives a probabilistic value that always lies between 0 and 1. Unlike linear regression, which is used to solve regression problems, logistic regression solves classification problems.
Why use a Logistic Regression Algorithm?
- it is easier to implement, interpret, and train when compared to other algorithms
- it offers valuable insights by measuring how relevant the variable is
- Effective with linear separable datasets
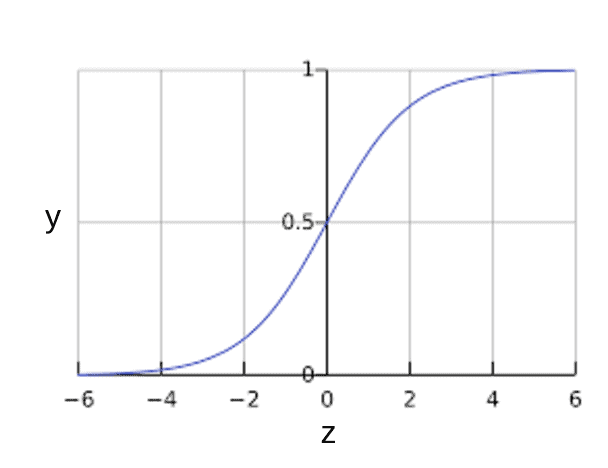
Logistic Regression
Logistic Regression is yet another commonly used Machine Learning Algorithm that leverages probability for outcomes and is a must-know algorithm for Data Scientists and Data Analysts.
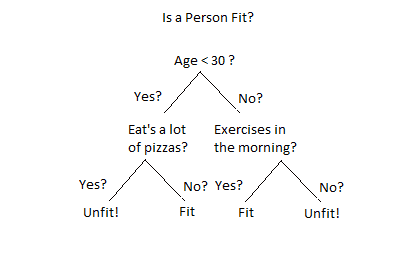
Decision Tree
This is another form of supervised learning in which data splits occur based on different conditions. The value of the root attribute is compared to the attribute of the record in the actual dataset. This is done in the root node and follows down the branch to the next node. The attribute value of every consecutive node is compared with the subnodes until it reaches the final leaf node of the tree.
Unlike the former two, a Decision Tree is used for both classification and regression tasks.
The Decision Tree constitutes
- Decision nodes: this is where the data split happens
- Leaves: this is where the final outcomes happen
Why use a Decision Tree Algorithm?
- It can handle multi-output problems.
- It can handle both categorical and numerical data.
- It offers ease of data pre-processing, making it less cumbersome to do.
- It does not need data scaling.
- It is not affected by missing values in the data.





Decision Tree is another important machine learning algorithm that is commonly used for classification and regression problems.
Support Vector Machine
Support Vector Machines, also called SVMs, are supervised Machine Learning algorithms used for regression and classification problems. First introduced in the 60s, SVMs are mainly used to solve classification problems. They have gained popularity recently since they can handle continuous and categorical variables.
Primarily, they are used to segregate data points of different classes by identifying a hyperplane. They are selected in a manner to maximize the distance between the hyperplane and the closest data points of each class. These close data points are called support vectors.
Support Vector Machines are sophisticated ML algorithms that perform both regression and classification tasks and can process linear and non-linear data through kernels.
Dimensionality Reduction Algorithms
In Machine Learning, there can be too many variables to work with. This could take the form of regression and classification tasks called Features. Dimensionality Reduction involves reducing the number of features in a dataset. This is done by transforming data from high-dimensional feature space to low-dimensional feature space while also not losing meaningful properties present in the data are not lost during the process.
Dimensionality Reduction trains better due to lesser data and requires less computational time.
Why use Dimensionality Reduction Algorithms?
- It aids in data compression by reducing features.
- Lesser dimensions mean lesser computing and the algorithms train faster.
- It removes unnecessary, redundant features and noises.
- With fewer data, the model accuracy improves drastically.
Working with loads of features can be a daunting task. But with methods like Dimensionality reduction ML algorithms, we can harness the power of how to use them and even remove the redundant ones.
K-Nearest Neighbors
The K-nearest neighbors algorithm, also known as KNN, is a supervised machine learning algorithm used to perform classification and regression tasks using non-parametric ML principles. KNNs are based on the concept of similar data points having similar labels or values. k is the number of labeled points for classification, where k refers to the number of labeled points for determining the result.
When training, this ML algorithm stores the whole training dataset as a reference. The distance between all the input data points and training examples is calculated for making predictions.
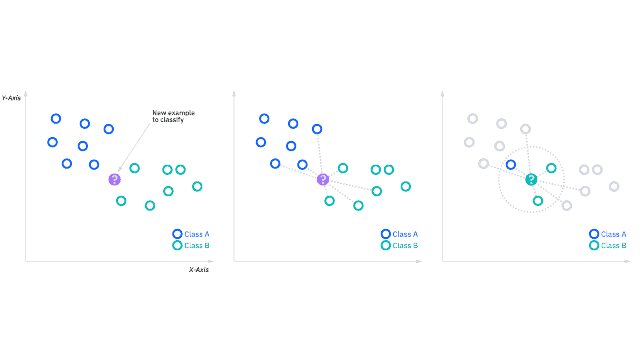
The algorithm identifies the kNN based on the distance between the k neighbor and the input data point. As a result, the most common class label of the kNNs is assigned as the predicted label for the input data point for classification tasks, and the average value of the target values of the kNNs is calculated to determine the input data point’s value.
Why use K-Nearest Neighbors?
- Its implementation does not require complex mathematical formulas or optimization techniques.
- Analyzes data without making any assumptions about their distribution or structure
- Having only one hyperparameter, k makes tuning easy.
- Training is not required since all the work is performed during prediction.
kNN is a lazy learning algorithm that makes predictions on the go and not based on the predictions of a learning model.
How Deep Learning Models Can Surpass ML?
Deep Learning models can outperform Machine Learning algorithms in various tasks due to their ability to model complex patterns and relationships directly from data rather than having to engineer features manually. Let us explore how Deep learning excels in many domains.
Automatic Feature Extraction
A deep learning algorithm learns to identify features automatically instead of using hand-engineered features, as is the case with traditional machine learning models. This capability is particularly useful in domains like image recognition and speech recognition, where it is extremely difficult to design effective features manually.
Hierarchical Feature Learning
A deep learning model builds a hierarchical representation of the data by learning multiple layers of representation. This allows the model to effectively capture both simple and complex patterns.
Handling High-Dimensional Data
Unlike traditional machine learning models, deep learning models thrive on high-dimensional data (like images, videos, and text), where traditional models can struggle. For example, a single pixel value from an image can contain tens of thousands or even millions of values.
Scalability and Performance
Deep learning models improve with increased data, while traditional machine learning algorithms often plateau or even degrade with increased data. This scalability is crucial in large-scale applications, such as those encountered in Big Data contexts.
Flexibility and Adaptability
With only minor adjustments to their architecture, deep learning models can be adapted to a wide range of tasks. In image classification, object detection, and even video analysis, the same convolutional neural network (CNN) architecture is easily used.
End-to-End Learning
The benefits of deep learning include end-to-end learning, which allows a model to be trained directly from raw data to output results, reducing the need for intermediate steps that require domain expertise. This is a significant advantage in complex tasks where the relation between input data and output is unclear.
State-of-the-Art Results
Many fields have benefitted from deep learning, surpassing traditional machine learning models and even human experts, such as playing complex games like Go and diagnosing medical conditions based on imaging.
Although deep learning models are powerful, they also present some drawbacks, such as the need for large quantities of labeled data, their computational complexity, and their lack of transparency (i.e., their lack of data transparency). “black boxes”). Therefore, the choice between deep learning and traditional machine learning depends on the specific requirements and constraints of the task at hand.
Deep Learning vs Machine Learning: The Showdown
We’ve finally reached the crux of this read. We saw earlier how Deep Learning models are better than Machine Learning algorithms in some aspects. In this section, we’ll discuss the differentiating factors, compare their performance, and also examine some real-world applications of them.
| Differentiating Factors | Machine Learning | Deep Learning |
| Definition | ML is a subfield of AI that makes predictions and decisions based on statistical models and algorithms by leveraging historical data. | DL is a subfield of ML that tries to replicate the workings of a human brain by creating artificial neural networks that can make intelligent decisions. |
| Architecture | ML is based on traditional statistical models. | DL uses artificial neural networks with multi-layer nodes. |
| Learning Process | 1. New information is acquired via a user query 2. Analyzes the data 3. Recognizes a pattern 4. Makes Predictions 5. The answer is sent back to the user | 1. Data is acquired 2. Data preprocessing 3. Next is data splitting and balancing 4. Model building and training 5. Performance evaluation 6. Hyperparameter training 7. Model Deployment |
| Computational & Data Requirements | 1. Data is acquired 2. Data preprocessing 3. Next is data splitting and balancing 4. Model building and training 5. Performance evaluation 6. Hyperparameter training 7. Model Deployment | 1. DL can work on unstructured data like images, text, or audio. 2. It requires high computational power due to its complexity. 3. DL requires large amounts of data for training. |
| Feature Engineering | ML requires the engineer to identify the applied features and then hand-coded based on the domain and data type. | DL reduces the task of developing new feature extractors for each problem by learning high-level features from data. |
| Types | ML can be broadly classified into 1. Supervised Learning 2. Unsupervised Learning 3. Reinforcement Learning | DL has these models 1. Convolutional Neural Networks 2. Recurrent Neural Networks 3. Multilayer Perceptron |
| Processing Techniques | ML uses various techniques like data processing or image processing. | DL relies on neural networks that constitute multiple layers. |
| Problem-solving Approach | In ML, the problem is divided into sections and solved individually, which are later combined to get the final result. | With DL, we can solve the problem from end to end. |
| Drawbacks | Some flaws of ML include 1. The algorithm development requires a high level of technical knowledge and skills. 2. Few ML algorithms are hard to interpret, making too hard to understand how the predictions were made. 3. ML algorithms require voluminous data for effective training. 4. If trained on biased data, then the models could also be biased. | Some flaws of DL include 1. DL models require high computational resources like good memory and powerful GPUs. 2. Since the models depend on the data quality, the performance can be affected negatively if the data is incomplete or noisy. 3. Since DL models are trained on large volumes of data, there is always a high chance of data privacy and security concerns. |
| Performance Comparison | 1. ML usually performs well with simple problems. 2. ML algorithms have improved accuracy as they learn from data. 3. They are highly scalable and capable of handling large datasets. 4. ML does not need as much computational power when compared to DL and is easier to set up and analyze. 5. ML requires careful feature selection and tuning of parameters for optimal performance. 6. ML algorithms require human intervention for feature extraction. | 1. DL excels at solving complex problems. 2. DL can achieve high accuracy levels with complex tasks like NLP or robotics. 3. DL can have lesser training times with parallel processing hardware. 4. Although DL requires high compute resources, its performance is better with more data. 5. It requires tuning of many parameters, but once the network architecture is set, it learns on its own from raw data. 6. Unlike ML, DL models do not require human intervention for feature extraction. |
| Career Opportunities | With ML, one can pursue roles such as 1. ML engineer 2. Data Scientist 3. Data Analyst 4. Business Intelligence Analyst Requires expertise in 1. Statistical analysis 2. Knowledge of Supervised & Unsupervised learning algorithms 3. Feature Engineering 4. Data preprocessing | With DL, one can pursue roles such as 1. DL Engineer 2. AI Research Scientist 3. CV Engineer 4. Robotics Engineer 5. Solutions Architect Requires expertise in 1. Neural networks 2. Deep learning frameworks 3. Model optimization techniques 4. Reinforcement Learning |
Conclusion
That’s a wrap of this article. We looked into the definitions of Machine Learning and Deep Learning, ran through common ML algorithms, and finally looked at Deep Learning vs Machine Learning, some of the key differentiating factors.
Keep your eyes peeled; more fun and comprehensive reads are coming your way on Artificial Intelligence, Deep Learning, and Computer Vision.
See you guys in the next one!



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning