


About the author:
Siddharth Advani earned his B.S. degree in electronics engineering from Pune University, India, in 2005, and his M.S. degree in electrical engineering and his Ph.D. degree in computer science and engineering from the Pennsylvania State University, State College, in 2009 and 2016, respectively. His research interests include real-time embedded systems targeted for domain-specific applications. He is currently a senior hardware engineer at Samsung Research America. This work was done while he was a Ph.D. student at the Pennsylvania State University.
Visual search has become a necessity for many multimedia applications running on today’s computing systems. Tasks such as recognizing parts of a scene in an image, detecting items in a retail store, navigating an autonomous drone, etc. have great relevance to today’s rapidly changing environment. Many of the underlying functions in these tasks rely on high-resolution camera sensors that are used for capturing light intensity-based data. The data is then processed by different algorithms to perform tasks such as object detection, object recognition, image segmentation, etc.

Visual attention has gained a lot of traction in computational neuroscience research over the past few years. Various computational models have used low-level features to build information maps, which are then fused together to form what is popularly called as a saliency map. Given an image to observe, this saliency map, in essence, provides a compact representation of what is most important in the image. The map can then be used as a mechanism to zoom in on identifying the regions of interest (RoIs) that are most important in the image. For example, in Figure 1, different saliency models show the extent to which pixels representing the bicyclist pop out in stark contrast to the background.
These models assume that the human eye uses its full resolution across the entire field of view (FOV). However, the resolution drops off from the center of the fovea towards the periphery and the human visual system (HVS) is adept at foveating so as to investigate other areas in the periphery when attention is drawn in that direction. In other words, our eyes foveate to allow points of interest to fall on the fovea, which is the region of highest resolution. It is only after this foveation process that we are capable of gathering complete information from the object of interest that drew our attention to it. The HVS has thus been built in such a way that it becomes necessary to move the eyes in order to facilitate processing information all around one’s environment. It is due to this reason that humans tend to select nearby locations more frequently than distant targets and salience maps need to be computed taking this into account to improve the predictive power of the models. Understanding the efficiency with which our eyes intelligently take in pertinent information to perform different tasks has a significant impact to building the next-generation of autonomous systems. Building a foveation framework to test and improve saliency models for real-time autonomous navigation is the focus of this work.
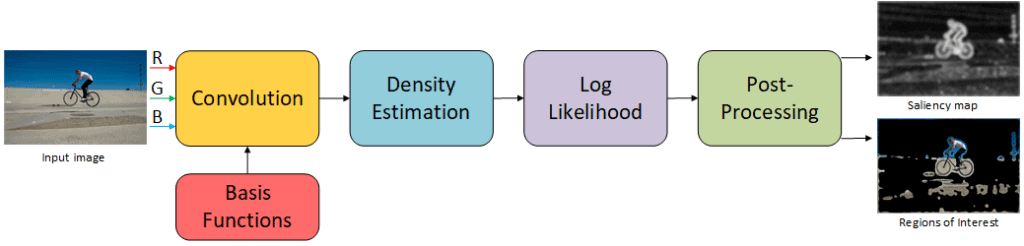
We choose an information theoretic computational saliency model, Attention based on Information Maximization (AIM) as a building block for our foveation framework. AIM has been benchmarked against many other saliency models and it has proven to come significantly close to human fixations. The model looks to compute visual content as a measure of surprise or rareness using Shannon’s self-information theory. The algorithm is divided into three major sections as shown in Figure 2. The first section involves creating a sparse representation of the image by projecting it on a set of learnt basis functions. The next section involves a density estimation using a histogram back projection technique. Finally a log-likelihood is computed to give the final information map. For more details on the algorithm and the theory behind it, one is pointed to [1].
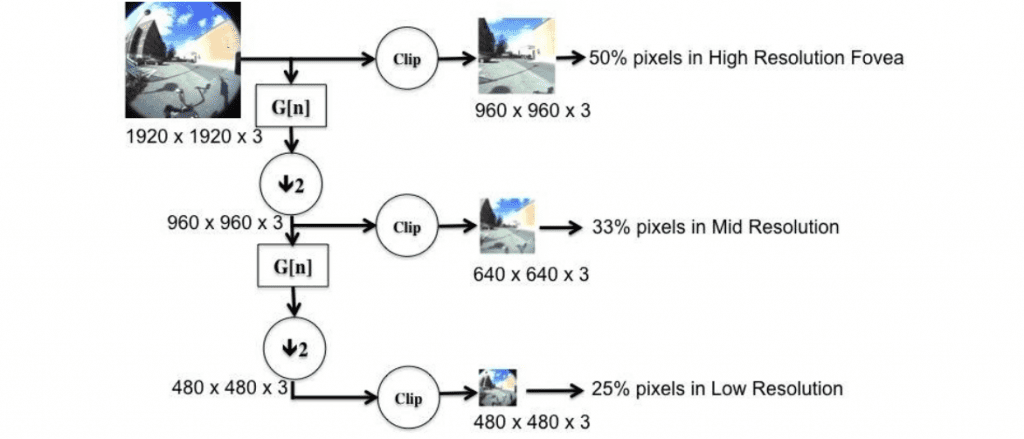
In order to model the steep roll-off in resolution from fovea to periphery, once the image is captured by the camera sensor, we build a three level Gaussian pyramid as shown in Figure 3. To do this, we first extract a 50% high-resolution center region from Level 1 as our fovea. After blurring and downsampling, a second region is cropped out from Level 2, representing the mid-resolution region. Another round of blurring and downsampling leaves us with the entire FOV but at a much lower resolution (Level 3). It should be noted that as the resolution drops off, the FOV is gradually increasing in our framework.
For our experiments, we use a ½” Format C-Mount Fisheye Lens having a focal length of 1.4 mm and a Field of View (FOV) of 185°. The images captured are 1920×1920 in size. The images have some inherent nonlinearity as one moves away from the center, which is similar to the way the human eyes perceive the world around. We run AIM on each of these three regions, which returns corresponding information maps. These information maps represent the salient regions at different resolutions as shown in Figure 4 (c). There are a number of ways in which to fuse these information maps to give a final multi-resolution saliency map. We believe that an adaptive weighting function on each of these maps will be a valuable parameter to tune in a dynamic environment. However, for this work, which focuses on static images, we use weights of w1 = 1/3, w2 = 2/3 and w3 = 1 for the high-resolution fovea, the mid-resolution region and the low-resolution region respectively. We use these weights since pixels in the fovea occur thrice across the pyramid while pixels in the mid-resolution region occur twice. These weights thus prevent the final saliency map from being overly center-biased. Since these maps are of different size, they are appropriately up-sampled and zero-padded before adding them up.

(a) Input Image (b) Image Pyramids with increasing FOV (c) Visual Attention Saliency Maps (d) Multi-resolution Attention Map by fusing (c) with different weights
To validate our model termed as Multi-Resolution AIM (MR-AIM), we ran experiments on a series of patterns as shown in Figure 5. First we considered a series of spatially distributed red dots of same dimensions against a black background (Figures 5 (a) and 5 (b)). As can be seen in the saliency result (Figures 5 (e) and 5 (f)) there is a gradual decrease in saliency as one moves away from the fovea (Red corresponds to regions of higher saliency while Blue corresponds to regions of lower saliency).
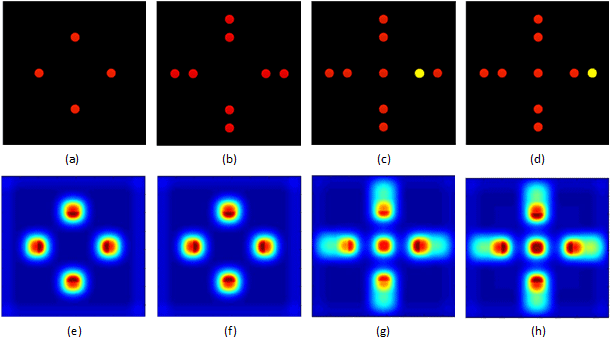
(a)-(d) Input Image, (e)-(h) Saliency Result
Onsets are considered to drive visual attention in a dynamic environment, so in Figure 5(c) we next considered the arrivals of new objects of interest within the fovea (red dot) and towards the periphery (yellow dot). Maximum response is obtained in the region around the yellow dot (Figure 5 (g)). Next, we consider a movement of the yellow dot further away from the fovea (Figure 5 (d)). Again we notice a slight shift in saliency moving attention towards the center (Figure 5 (h)). These experiments give us valuable information on the mechanisms of our model when the object of interest is moving relative to the fovea.





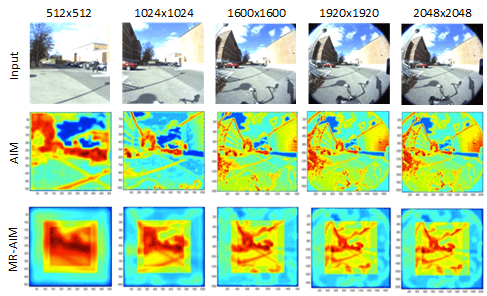
Our next set of experiments was to compare the multi-resolution model with the original AIM model and evaluate the former, both, in terms of quality and performance. It should be noted here that the dataset provided in [4] has images of maximum size 1024×768, while the framework designed here is ideally targeted towards high-resolution images that contain a lot of salient objects. Figure 6 (Row 1) shows an example of such an image with increasing size from left to right. Row 2 depicts results from the original AIM model. Row 3 shows the output of the MR-AIM. For smaller image sizes, AIM does a very good job in spotting the main RoIs. But as the image size starts to increase, it starts to pick edges as most salient. This is due to the limited size (21×21) of the basis kernels used. Increasing the size of the kernels is not a viable option for a real-time system since that would in turn increase the computation time. MR-AIM has no such problem. Since it operates on smaller image sizes at different resolutions, it can detect objects at different scales. There is a bias towards objects in the center, but the weights do a significant job in capturing RoIs towards the periphery as well. It should be noted here that MR-AIM would not pick up objects that become extremely salient in the periphery, but adding other channels of saliency, such as motion, will make the model more robust in a dynamic environment.

Another set of experiments run was on a series of video frames captured in an environment where there was sufficient activity in the periphery to activate attention as shown in Figure 7. We compare our model to other models rather than verifying against actual eye-tracking data since such data is not readily available for high-definition images. The top row shows Itti’s results for frame numbers 17, 22 and 27. The middle row shows AIM’s results for the respective frames while the bottom row shows MR-AIM’s response. For a fair comparison we deactivated the inhibition of return in Itti’s model. Both AIM and MR-AIM capture the onset of the bicyclist in frame 22 successively. These experiments offer us confidence about the qualitative performance of our proposed model. MR-AIM was also benchmarked on the MIT Saliency dataset and detailed results can be found here. Our work was published in [5] and an OpenCV based source code is also available here.
References:
[1] N. D. B. Bruce and J. K. Tsotsos, “Saliency Based on Information Maximization,” Advances in Neural Information Processing Systems, vol. 18, pp. 155–162, 2006.
[2] L. Itti, C. Koch, and E. Niebur, “A Model of Saliency-Based Visual Attention for Rapid Scene Analysis,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 20, no. 11, pp. 1254–1259, 1998.
[3] T. Judd, K. Ehinger, F. Durand and A. Torralba, “Learning to Predict Where Humans Look”, IEEE International Conference on Computer Vision (ICCV), 2009.
[4] T. Judd, F. Durand, and A. Torralba, “A Benchmark of Computational Models of Saliency to Predict Human Fixations,” 2012.
[5] S. Advani, J. Sustersic, K. Irick, and V. Narayanan, “A Multi-Resolution Saliency Framework To Drive Foveation,” IEEE Proceedings of The 38th International Conference on Acoustics, Speech, and Signal Processing, 2013.



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning