
Introduction
Computer vision engineering can be challenging for junior engineers as it requires a deep understanding of both foundational concepts and emerging technologies. In this article, we’ve compiled a list of top interview questions and answers that discuss key areas of computer vision, providing insights into what aspiring computer vision engineers can expect and how they can prepare for their interview.
1. Advanced CNN Architectures: Can you compare and contrast different CNN architectures like AlexNet, VGG, and ResNet? How do their approaches to image classification differ?
AlexNet:
Introduced in 2012, it was one of the first deep neural networks that significantly improved image classification performance.
AlexNet has eight layers, with five convolutional layers followed by three fully connected layers.
It uses ReLU (Rectified Linear Unit) for non-linear operations, which helps in faster training compared to tanh or sigmoid functions.
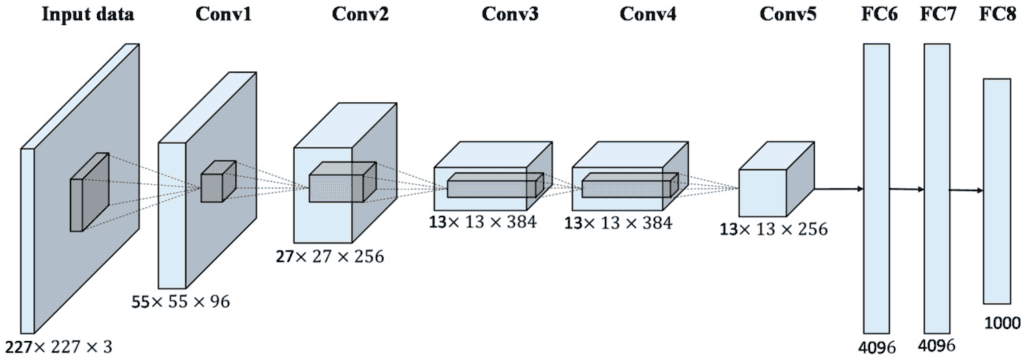
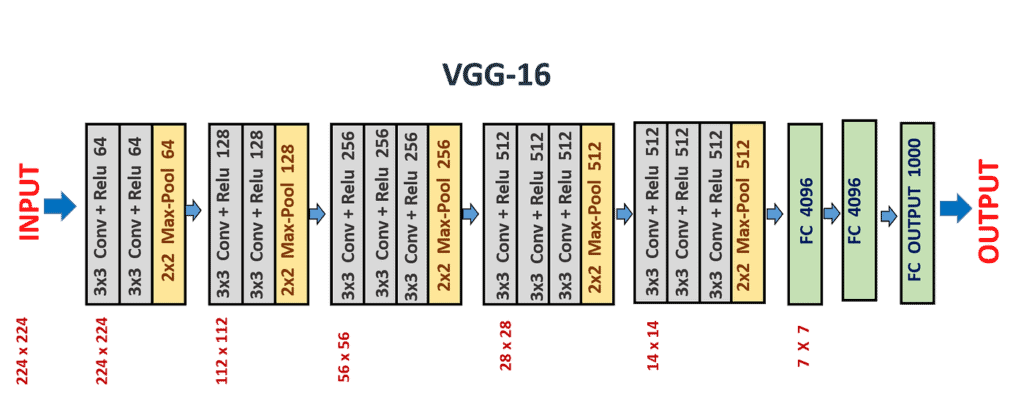
VGG (Visual Geometry Group):
Developed by the Visual Geometry Group at Oxford, VGG was introduced in 2014.
It’s known for its simplicity, using only 3×3 convolutional layers stacked on top of each other in increasing depth.
VGG has variants like VGG16 and VGG19, where the numbers denote the layers. Despite its deeper structure, VGG is relatively straightforward in its uniform architecture.
ResNet (Residual Network):
Introduced by Microsoft in 2015, ResNet brought a significant innovation with the introduction of skip connections or residual connections.
ResNet allows training of much deeper networks (up to 152 layers) by using these connections to carry forward activations from previous layers.
The main difference in approach is that ResNet uses these skip connections to add the output from an earlier layer to a later layer, which helps combat the vanishing gradient problem.
Differences in Image Classification Approaches:
AlexNet was revolutionary for its time, introducing deep learning to the computer vision community, but it has a relatively shallow architecture compared to newer models.
VGG focuses on depth, showing that increasing depth with small convolution filters can significantly improve performance. However, it’s computationally intensive and has many parameters, leading to high memory usage.
ResNet uses a different approach by introducing residual learning. This enables the training of very deep networks without the risk of vanishing gradients, which often occurs in traditional deep networks. This allows ResNet to achieve better accuracy with increased depth without a proportional increase in complexity.
2. Deep Learning Optimization: How do you optimize training processes for deep learning models in computer vision, and what are the trade-offs of different optimization algorithms?
Optimizing training processes for deep learning models in computer vision involves several strategies:
Data Preprocessing: Ensure your data is clean and well-prepared. This includes normalizing images to have similar scales and augmenting the dataset by adding variations like rotations or flips to improve the model’s ability to generalize.
Learning Rate Adjustment: The learning rate controls how much the model’s weights change in response to the estimated error each time the model weights are updated. Using techniques like learning rate decay, where the rate decreases over time, can help the model to converge more effectively to a solution.
Regularization: To prevent overfitting (where the model learns the training data too well and performs poorly on unseen data), methods like L1 and L2 regularization add a penalty for larger weights in the model.
Batch Size: The size of the batches of data fed to the model can impact training speed and stability. Larger batches provide a more accurate estimate of the gradient, but they require more memory and may slow down the training process.
Optimizer Choice: Different optimizers can affect training speed and performance. For example, Stochastic Gradient Descent (SGD) is simple and effective for many problems, while more complex optimizers like Adam adjust the learning rate dynamically and can lead to faster convergence in some cases.
Trade-offs of Different Optimization Algorithms:
SGD is robust and has been around for a long time, but it might take longer to converge, especially on complex models and large datasets.
Adam can converge faster due to its adaptive learning rate features but might lead to overfitting if not carefully regulated and sometimes doesn’t perform as well at the end of training.
Adagrad adapts the learning rate to parameters, giving parameters that are updated less frequently larger updates, but it can prematurely decrease the learning rate.
Choosing the right optimization method and tuning these parameters requires balancing the speed of convergence, the computational cost, and the model’s final performance on unseen data.
3. Computer Vision in Autonomous Vehicles: How is computer vision applied in autonomous driving, and what are the key challenges in this domain?
Object Detection and Classification: Computer vision models identify and classify objects like other vehicles, pedestrians, traffic lights, and road signs. This helps the vehicle understand its surroundings and make decisions based on what it ‘sees.’
Lane Detection: Computer vision helps in detecting lane markings on the road. This is essential for maintaining the vehicle within its lane and for performing safe lane changes.
Traffic Sign Recognition: Autonomous vehicles use computer vision to recognize traffic signs and respond accordingly, like stopping at stop signs or adjusting speed based on speed limits.
Depth Perception: By using techniques like stereo vision, vehicles can estimate the distance to various objects, which is crucial for collision avoidance and path planning.
Key Challenges in this Domain:
Variability in Environmental Conditions: Computer vision systems must work reliably in various lighting conditions (day, night, dusk, dawn) and weather conditions (rain, fog, snow), which can significantly affect visibility.
Dynamic and Unpredictable Elements: Roads are dynamic environments with unpredictable elements, such as pedestrians suddenly crossing the road or other vehicles braking abruptly.
Sensor Fusion: Combining data from various sensors (cameras, LiDAR, radar) to create a coherent understanding of the environment is challenging but necessary for accurate perception and decision-making.
Real-time Processing: The computer vision algorithms must process and analyze data in real-time to make immediate decisions, requiring highly efficient and fast processing capabilities.
Data and Model Robustness: Ensuring that the training data for computer vision algorithms is diverse and comprehensive enough to handle rare or unusual situations and that the models are robust to variations and anomalies, is a significant challenge.
4. 3D Reconstruction: Discuss the process and challenges of 3D reconstruction from 2D images in computer vision.
3D reconstruction from 2D images in computer vision involves creating a three-dimensional model of an object or scene from its two-dimensional photographs. Here’s how the process generally works and the challenges involved.

Process of 3D Reconstruction:
Image Capture: Multiple photographs are taken of the object or scene from different angles.
Feature Matching: Computer vision algorithms identify and match features across the different images. Features are points in the images that can be reliably identified in other images, like corners, edges, or specific texture patterns.
Estimate Motion: The relative motion between the camera positions when each image was taken is estimated using the matched features.
Reconstruct Geometry: Using the camera motion and feature correspondences, the geometry of the scene or object is reconstructed. This can be done using various methods, such as triangulation, where the 3D position of a point is determined by intersecting the lines of sight from two camera positions.
Texture Mapping: The final step involves mapping the images onto the reconstructed 3D model to give it a realistic appearance.
Challenges of 3D Reconstruction
Feature Ambiguity: Similar features in different parts of the scene can lead to incorrect matches, affecting the accuracy of the reconstruction.
Occlusions: Parts of the scene or object might be blocked in some images, leading to incomplete data and potentially causing errors in the 3D model.
Scale and Resolution: The scale and resolution of the images can affect the level of detail and the quality of the 3D reconstruction.
Motion Estimation: Accurately estimating the motion of the camera or the object, especially when the movement is complex, or the images are taken from significantly different viewpoints, can be difficult.
Computational Intensity: 3D reconstruction, especially of large or complex scenes, requires significant computational resources and time, particularly when high levels of detail are necessary.
5. Neural Network Pruning and Compression: Can you explain the concept of neural network pruning and compression and its importance in deploying computer vision models on edge devices?
Neural network pruning and compression are techniques for reducing the size and complexity of a neural network model without significantly compromising its performance.
Neural Network Pruning:
Pruning involves removing unnecessary or redundant parameters from a neural network. This can mean eliminating weights that have little to no impact on the model’s output.
The process typically starts with training a large, over-parameterized model, which is then pruned by removing weights based on certain criteria, such as the smallest absolute values.



The pruned network is then fine-tuned to retain its performance despite the reduction in size.
Neural Network Compression:
Compression goes beyond pruning by applying techniques like quantization, which reduces the precision of the numerical values in the model.
For example, instead of using 32-bit floating-point numbers for weights, a compressed model might use 8-bit integers, significantly reducing the model size and computational requirements.
Other compression techniques can include using knowledge distillation, where a smaller model is trained to replicate the behavior of a larger, more complex model.
Importance in Deploying on Edge Devices:
Edge devices, like smartphones and IoT devices, have limited memory, processing power, and energy resources. Due to these constraints, deploying a full-sized neural network model on such devices can be impractical or impossible.
Pruning and compression reduce the model’s size and computational needs, making it feasible to run sophisticated computer vision algorithms on edge devices.
This enables real-time processing and analysis of visual data directly on the device, reducing the need for constant data transmission to cloud servers, which can save bandwidth and reduce latency.
6. Real-time Object Detection: What strategies would you use to improve the speed and accuracy of real-time object detection systems?
Improving the speed and accuracy of real-time object detection systems involves several strategies:
Model Architecture Selection: Choose efficient model architectures specifically designed for real-time processing, such as YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector), or tiny versions of more complex models like Tiny YOLO. These models are optimized for speed and can operate in real-time with good accuracy.
Model Pruning and Quantization: Reduce the complexity of the model by pruning less important connections and quantizing the model parameters to lower precision. This reduces the computational load and can speed up the detection process without significantly dropping accuracy.
Optimized Hardware Utilization: Use specialized hardware accelerators like GPUs, TPUs, or FPGAs that are designed to handle the parallel computations required for deep learning models efficiently. This can significantly boost the speed of object detection.
Software Optimization: Optimize the code and use efficient algorithms for pre-processing and post-processing steps. Leveraging software libraries that are optimized for performance, such as OpenCV, can also help in reducing latency.
Training with Augmented Data: Improve accuracy by training the model with a diverse set of data that includes various scenarios and conditions. Data augmentation techniques such as scaling, cropping, and rotation can help the model generalize better and perform more accurately in different environments.
Hyperparameter Tuning: Fine-tune model hyperparameters like the learning rate, batch size, and number of epochs to find the best balance between speed and accuracy for the specific application.
Edge Computing: Process data on or near the device where it is collected (edge computing), rather than sending it to a centralized server. This reduces the latency and can speed up the response time of the object detection system.
7. Vision Transformers: Explain the concept of Vision Transformers (ViTs) and how they differ from traditional CNNs in processing images.
Vision Transformers (ViTs) represent a shift in how images are processed, differing significantly from the approach used by traditional Convolutional Neural Networks (CNNs).
Concept of Vision Transformers:
ViTs apply the transformer architecture, originally designed for natural language processing, to image analysis.
In ViTs, an image is divided into patches, which are then flattened and linearly transformed into a sequence of embeddings. The transformer network processes these embeddings, similar to tokens in NLP.
A transformer uses self-attention mechanisms to weigh the importance of different patches in an image, allowing the model to focus on relevant parts of the image for the task at hand.
Differences from Traditional CNNs:
Architecture: While Convolutional neural networks use convolutional layers to hierarchically extract features from images, ViTs use self-attention mechanisms that consider the entire image context, enabling them to capture global dependencies within the image.
Receptive Field: In CNNs, the receptive field is local and grows with successive convolutional layers. In contrast, ViTs have a global receptive field from the beginning, as each transformer layer can attend to all parts of the image.
Feature Extraction: CNNs extract features through local filters and pooling operations, whereas ViTs directly learn to attend to significant image parts without being constrained by the structure of convolutions.
Data Efficiency: CNNs are generally more data-efficient and can work well with smaller datasets. ViTs, on the other hand, require large amounts of data to train from scratch but excel when trained with enough data, often surpassing CNNs in performance on large-scale datasets.
Computational Resources: ViTs are often more computationally intensive than CNNs, especially for larger images, because the self-attention mechanism’s complexity scales with the number of patches (sequence length).
8. Machine Learning Bias in Computer Vision: How can bias in machine learning models impact computer vision tasks, and what steps can be taken to reduce this bias?
Bias in machine learning models can significantly impact computer vision tasks, leading to unfair or inaccurate outcomes. Here’s how bias can affect computer vision and steps to reduce it:
Impact of Bias on Computer Vision Tasks:
Unfairness: Bias can result in unfair treatment of certain groups. For example, facial recognition systems have been found to have higher error rates for people of certain races or genders.
Inaccuracy: Biased training data can lead to inaccurate models that perform poorly in real-world scenarios, especially for underrepresented groups or conditions.
Steps to Reduce Bias:
Diverse and Representative Data: Ensure the training dataset is diverse and representative of the real-world scenarios in which the model will be used. This includes diversity in terms of race, gender, age, lighting conditions, backgrounds, and more.
Regular Auditing and Testing: Regularly audit and test the models for bias and accuracy, using diverse datasets that include various demographics and scenarios.
Bias Mitigation Techniques: Employ bias mitigation techniques during the training process. This can include methods like re-weighting the training data, modifying the model’s objectives to account for fairness, or using algorithms designed to reduce bias.
Transparency and Explainability: Develop models that are transparent and explainable, allowing for the identification and correction of biases. Explainable AI can help stakeholders understand how and why decisions are made.
Ethical and Inclusive Design Practices: Adopt ethical guidelines and inclusive design practices in the development of computer vision systems. Engaging with diverse teams and stakeholders can provide multiple perspectives and help identify potential biases.
Continuous Monitoring and Feedback: After deployment, continuously monitor the system’s performance and collect feedback to identify and correct any emerging biases or inaccuracies.
9. Augmented Reality in Computer Vision: Discuss the role of computer vision in augmented reality applications and the technical challenges involved.
Computer vision plays a crucial role in augmented reality (AR) applications by enabling devices to understand and interact with the real world in real time. Here’s how computer vision contributes to AR and the technical challenges it faces.

Role of Computer Vision in AR:
Environment Mapping: Computer vision algorithms help create a digital map of the surrounding environment. This is essential for accurately placing virtual objects in the real world.
Object Recognition and Tracking: AR systems use computer vision to recognize and track objects or specific points in the real environment, allowing for the seamless integration of virtual and real-world elements.
Depth Perception: Computer vision techniques are used to estimate the distance of objects in the environment, which is crucial for correctly overlaying virtual objects onto the real world.
Technical Challenges in AR:
Real-time Processing: AR requires fast and efficient processing of visual data to ensure a seamless and immersive experience. Achieving this real-time performance is challenging, especially on devices with limited computational resources.
Accuracy and Precision: For a convincing AR experience, the accuracy and precision of object placement, tracking, and interaction must be high. Ensuring this level of precision under varying environmental conditions is challenging.
Lighting and Environmental Conditions: Changes in lighting and different environmental conditions can affect the performance of computer vision algorithms in AR systems. The system must be robust enough to handle these variations without degrading the user experience.
User Interaction and Experience: Designing intuitive and natural user interactions in AR, supported by computer vision, requires sophisticated algorithms that can understand and predict user intent and actions.
Power Consumption: Computer vision algorithms, especially those running on portable AR devices like smartphones and AR glasses, must be optimized for low power consumption to ensure longer battery life.
Conclusion:
The questions and answers we explored provide a glimpse into the complex world of computer vision, highlighting the importance of continuous learning and adaptation.
Whether you’re preparing for an interview or just keen to learn more, these insights will help lay the way for success.


5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning