

Hello,
Let me show you an image, can you describe what you see?

Perfect! You nailed it: a bird sitting peacefully on a railing.
Now, let’s flip it. I’ll describe something, and you imagine how it might appear:
“A puppy sitting on a railway track.”

Nice! Something like this might be popped right into your mind, didn’t it?
This felt seamless while connecting sight and language for us humans.
But for computers, this was a huge challenge. How could a machine truly understand the content of an image, not just as a collection of pixels, but in a way that connects to the richness of human language?
Until CLIP came along.
CLIP, which stands for Contrastive Language-Image Pre-training, is a revolutionary AI model from OpenAI that has fundamentally changed how machines perceive our world. It bridges the gap between images and words, creating a powerful new way for AI to learn and understand. This post will explain what CLIP is, how it works, why its abilities are such a game-changer, and the incredible applications it has unlocked.
What is CLIP? (The Simple Explanation)
Let’s break down the name to understand the core idea.
- Language-Image: At its heart, CLIP learns from pairs of images and the text descriptions that go with them.
- Pre-training: It’s “pre-trained” on an absolutely massive dataset before being applied to any specific task. This gives it a broad, general understanding of the world.
- Contrastive: This describes how it learns. In a huge batch of images and text captions, the model learns to figure out which image belongs to which caption. It’s like a giant, complex matching game where the model is rewarded for correctly pairing an image with its text and penalized for making the wrong connection.
So, the core idea is this: CLIP is a model that learns the relationship between visual data (images) and textual data (language). To achieve this, it was trained on a staggering 400 million image-text pairs scraped from the internet. This immense scale is what gives it such a vast and nuanced understanding of concepts.
How Does It Actually Work?
To achieve its goal, CLIP uses a clever two-part architecture. You can think of it as having a “two-part brain.”
- The Image Encoder: This part of the model is a computer vision expert. It looks at an image and converts it into a list of numbers, known as an “embedding.” This embedding is a mathematical representation of the image’s key visual features. It uses well-known architectures like a Vision Transformer (ViT) or ResNet to do this.
- The Text Encoder: This part is a language expert. It takes a piece of text (like a sentence or a label) and also converts it into an embedding, a list of numbers that represents the semantic meaning of the words. It uses a standard Transformer architecture for this task.
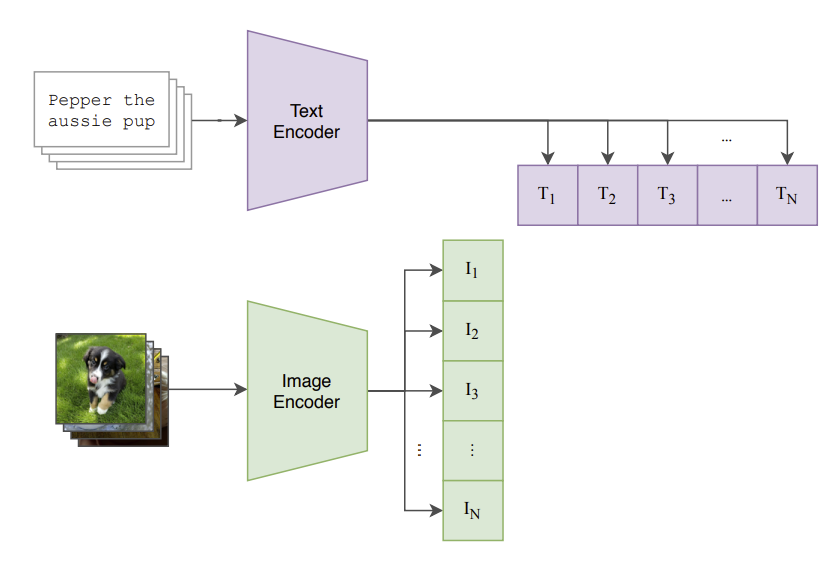
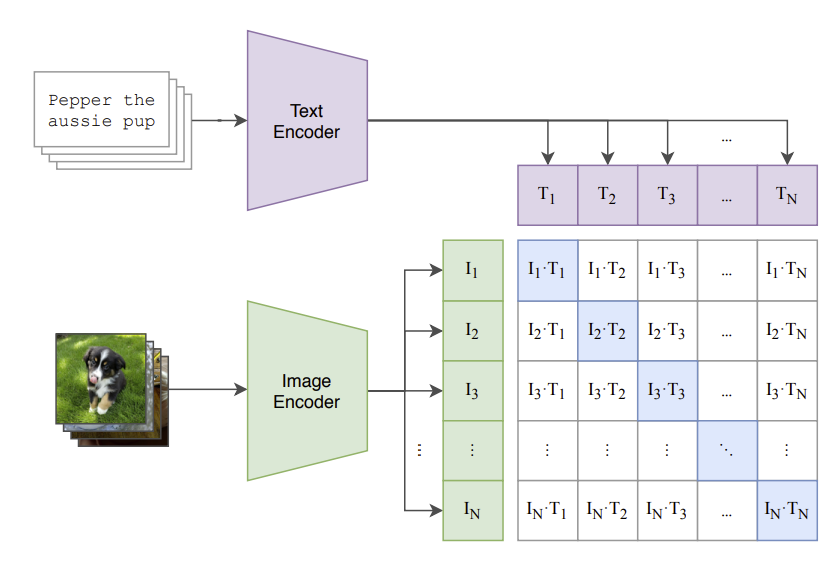
The real magic happens in what’s called the shared embedding space. Both the image encoder and the text encoder are trained to map their outputs into this common space. The goal is to place the embeddings for a matching image and text description very close to each other.





Imagine a giant library where every book (text) and every picture (image) about “dogs playing in a park” are all located on the same shelf. That’s what CLIP learns to do. During its “contrastive” training, it learns to maximize the similarity (often measured by a metric called cosine similarity) between the correct pairs while pushing all the incorrect pairs further apart.
The Superpower: Zero-Shot Learning
The most incredible ability that emerges from this training method is zero-shot learning. This is the ability to perform a task it wasn’t explicitly trained to do.
For example, most older AI models needed to be painstakingly trained on a specific dataset for a specific task. If you wanted a model to classify dog breeds, you had to show it thousands of labeled pictures of poodles, retrievers, and so on.
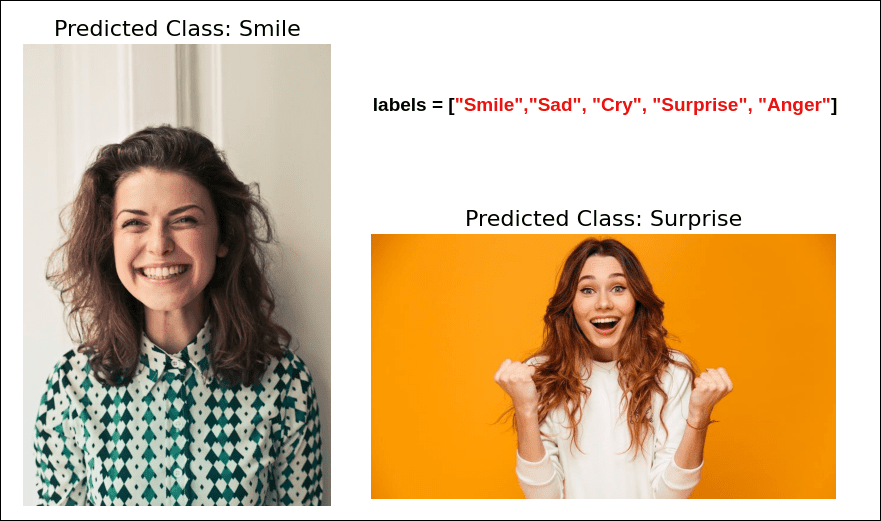

CLIP is different. You can give it an image of a zebra and ask it to choose between the text labels: “a photo of a horse,” “a photo of a tiger,” and “a photo of a zebra.” Even if CLIP has never been specifically trained on a curated “zebra” dataset, it can identify the correct label with high accuracy. It can do this because it learned the concept of a zebra from the millions of images and captions it saw on the internet.
This is a monumental leap. It makes AI far more flexible and eliminates the need to create specialized datasets and retrain models for every new classification task.
Real-World Applications: Where is CLIP Making an Impact?
CLIP’s unique abilities have made it a foundational component in a new wave of AI tools.
- Powering Image Generation: CLIP is the “guiding brain” behind incredible text-to-image models like DALL-E 2 and Stable Diffusion. As these models generate an image from a text prompt (e.g., “an astronaut riding a horse on Mars”), they use CLIP to constantly check how well the image-in-progress matches the text. CLIP’s score guides the generation process, steering it toward a final image that accurately reflects the prompt.
- Smarter Image Search: Instead of just searching for keywords like “cat,” you can now search for concepts like “a black cat sleeping on a red sofa.” Search engines powered by CLIP can understand the semantic context and find visually relevant images, even if the exact words aren’t in the metadata.
- Content Moderation: CLIP can automatically identify and flag inappropriate or harmful images by understanding the concepts within them, rather than relying on pre-defined, rigid categories.
- Creative Tools: Artists and designers are using CLIP-based tools to generate and edit images with simple text commands, opening up new avenues for creativity.
- Robotics: CLIP is helping robots better understand the world and follow human commands like “pick up the red ball from the table.”
Limitations of CLIP
Despite its power, CLIP is not perfect. It’s important to understand its limitations:
- Struggles with Fine-Grained Details: While it knows what a car is, it might not be able to reliably tell the difference between a 2021 Honda Civic and a 2022 model.
- Bad at Counting: It often gets the number of objects in an image wrong. It understands “apples” but not necessarily “a photo of three apples.”
- Inherits Biases: Because it was trained on a massive, unfiltered dataset from the internet, it can pick up and even amplify harmful human biases related to gender, race, and culture.
- Difficulty with Abstract Concepts: It can struggle with highly abstract, nonsensical, or complex prompts that require logical reasoning.
CLIP in Action: A Simple Code Example
Talk is cheap, so let’s see it work! With the Hugging Face transformers library, using CLIP is surprisingly straightforward. The following Python code shows how to perform zero-shot classification on an image from the web.
# You'll need to install the necessary libraries first:
# pip install transformers torch Pillow requests
import requests
from PIL import Image
import torch
from transformers import CLIPProcessor, CLIPModel
# 1. Load the pre-trained CLIP model and its processor
# The processor handles preparing the image and text for the model
model_name = "openai/clip-vit-base-patch32"
model = CLIPModel.from_pretrained(model_name)
processor = CLIPProcessor.from_pretrained(model_name)
# 2. Load an image from a URL
# Let's use a well-known image of a cat from the COCO dataset
url = ""
try:
image = Image.open(requests.get(url, stream=True).raw)
except Exception as e:
print(f"Could not load image from URL: {e}")
# As a fallback, create a simple placeholder image
image = Image.new('RGB', (224, 224), color = 'red')
# 3. Define your candidate text labels
# This is our "zero-shot classifier"
text_labels = ["a photo of a cat", "a photo of a dog", "a photo of a car"]
# 4. Process the image and text
# The processor converts the image and text into a numerical format (embeddings)
# that the CLIP model understands.
inputs = processor(text=text_labels, images=image, return_tensors="pt", padding=True)
# 5. Get the model's predictions
# The model will output "logits," which are raw scores representing the similarity
# between the image and each text label.
with torch.no_grad():
outputs = model(**inputs)
# The logits_per_image gives us the similarity scores
logits_per_image = outputs.logits_per_image
# 6. Convert scores to probabilities and print the results
# We use the softmax function to convert the raw scores into probabilities.
probs = logits_per_image.softmax(dim=1)
# Print the results nicely
print("Image-Text Similarity Probabilities:")
for i, label in enumerate(text_labels):
print(f"- {label}: {probs[0][i].item():.4f}")
# Find the label with the highest probability
highest_prob_index = probs.argmax().item()
print(f"\n--> Predicted Label: '{text_labels[highest_prob_index]}'")
When you run this code, the model will correctly identify that the image is best described by “a photo of a cat” with a very high probability, demonstrating its powerful zero-shot capabilities in just a few lines of code.
CLIP represents a paradigm shift in artificial intelligence. By learning to connect images and text in a deeply meaningful way, it has unlocked capabilities that were once the stuff of science fiction. Its revolutionary zero-shot learning ability has made AI more flexible, powerful, and adaptable than ever before.
While it has its limitations, CLIP’s role as the engine behind the current AI boom is undeniable. It’s a foundational technology that is helping us build more capable and intelligent systems that can, for the first time, begin to understand our rich, multimodal world a little more like we do.


5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning