Intro
In pursuit of lower cost, network bandwidth and power consumption, and yet improved reliability and privacy, AI computing paradigm is shifting from “cloud” towards the “edge” in many different areas, such as security, transportation, manufacturing, auto-driving, smart home and so on. Hundreds of millions of devices need to be become smart.
Currently, most embedded devices use CPUs based on ARM architecture, including Cortex-A and Cortex-M series. Deep Learning algorithms are usually trained on x86/x64-based servers with powerful Nvidia GPUs. But then the inference needs to be performed on low-power ARM chips. The highest-priority goal here is the inference effectiveness, and therefore usability of such edge solutions.
OpenCV DNN Acceleration on ARM
OpenCV Deep Learning Module (OpenCV DNN) contains cross-platform implementation of deep learning inference algorithms, including the ARM support. But this implementation lacks in-depth performance optimization. In order to enhance the DNN inference performance on ARM, OpenCV makes use of Tengine library as the high-performance computing library for ARM since OpenCV 4.3.0 and 3.4.10. The performance improvements are shown in the diagrams below:

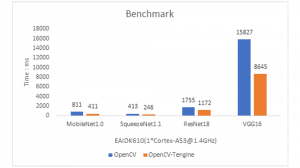
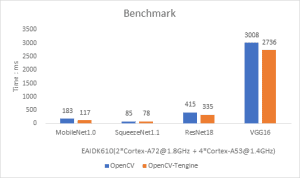
About Tengine
In addition to being a high-performance computing library for ARM, Tengine is also a application development platform for AIoT scenarios. Tengine is launched by OPEN AI LAB to solve the fragmentation problem of AIoT industrial chain and to accelerate AI industrialization.
Tengine is designed specifically for AIoT scenarios, and it has several features important for that, such as portability across different platforms, heterogeneous computing, extensive low-level (down to the metal) optimization, ultra-light weight, convenient deployment toolchain. Tengine supports different operating systems and simplifies and accelerates migration of various AI algorithms to embedded edge devices.
More info in Tengine GitHub Homepage can be found at https://github.com/OAID/Tengine