

Introduction to Video Generation Models
Generative AI has taken the world by storm with the likes of ChatGPT-4, Stable Diffusion 3, Devin AI, and now SORA.
SORA is an image or text-to-video generation tool courtesy of OpenAI. Generative models are the powerhouse behind these awesome video sequences and realistic novel content. These models were trained on video data and are capable of generating videos based on the learnings from the training dataset. It leverages algorithms and neural networks to generate unique, realistic videos.
Let us look at some common applications of generative video models.
Creative Storytelling: Narrative-based videos are easy with generative video models, which offer personalized and interactive storytelling experiences in gaming, VR, and AR.
Content Creation: Creators can now create visually appealing characters and stories that are new and unique.
Video Editing and Enhancement: Video generative models can automate video editing tasks like generating missing frames or enhancing video quality, reducing post-production efforts.
VR and AR: VR and AR have taken immersive experiences to a whole new level. Generative video models can create virtual environments that are so immersive that they’re like traveling to another dimension.
Data Augmentation and Simulation: They can drastically improve the robustness of video analysis systems by creating synthetic video data to augment training datasets for models.
Generative video models hold huge potential in video synthesis, storytelling, video editing, and many more video generative tasks, proving to be the next big thing in Gen AI in 2024.
What is SORA?
OpenAI, the creators of ChatGPT and Dall-E, introduced SORA, a text-to-video AI model, back in February. SORA is a major stride in Generative AI’s ability to create lifelike videos. OpenAI has showcased a few examples, although there hasn’t been much publicity or advertising. You enter a text prompt in text form, and SORA will generate a video that can go up to a minute long.
Prompt: The camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope, dust kicks up from it’s tires, the sunlight shines on the SUV as it speeds along the dirt road, casting a warm glow over the scene. The dirt road curves gently into the distance, with no other cars or vehicles in sight. The trees on either side of the road are redwoods, with patches of greenery scattered throughout. The car is seen from the rear following the curve with ease, making it seem as if it is on a rugged drive through the rugged terrain. The dirt road itself is surrounded by steep hills and mountains, with a clear blue sky above with wispy clouds.
SORA uses NLP and Deep Learning models to generate high-quality, minute-long videos. Although SORA was not the first generative video model, it is the first of its kind to showcase high-quality, photorealistic videos.
History of SORA
As discussed earlier, SORA was not the first generative video model. We have Make-a-Video from Meta, Lumiere from Google, Gen-2 from Runway, and Dall-E from OpenAI.





Pre-SORA era, we had Dall-E short for Diverse All-Purpose Lightweight Layout Engine from OpenAI. Launched in January 2021, it is OpenAI’s multimodal text-to-image Generative AI tool. It is a customized version of GPT-3 that works on 12 billion parameters. Then, Dall-E 2 came along in 2022, boasting a quadrupled image resolution and a streamlined architecture of 3.5 billion parameters for image generation. Unlike its predecessors, Dall-E 2 was a head-turner.
SORA Architecture and How does it work?
SORA uses diffusion-based transformer architecture for video generation. More about this in the next section.
SORA uses visual patches as tokens. Video data is broken down into frames, where every frame is decomposed into pixel groups. SORA captures temporal information of the pixels.
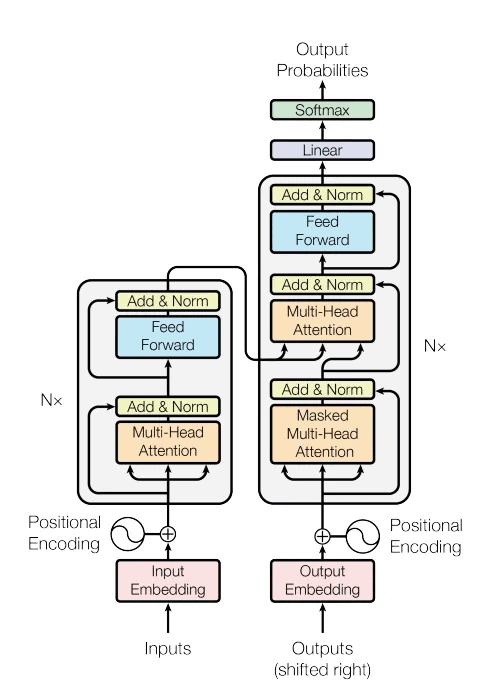
Let us now explore the components of SORA’s architecture.
Video Compression
The intent is to code, encode, and decode video content efficiently. Leveraging frameworks like Variational Autoencoder (VAE) makes this possible. SORA compresses raw video into a latent representation that stores spatial and temporal information.
Space Time Patches
This is the heart of SORA. They are based on ViT. Traditionally, ViTs use a sequence of image patches to train transformer models. SORA can work with videos and images with different resolutions, lengths and even aspect ratios with the help of patch based representation.
Unified Representations
SORA transforms all forms of visual data into unified representation. Here videos are compressed into low dimensional latent spaces and decomposes into spacetime patches. It uses fixed-size patches for simplicity, scalability and stability.
Variable Resolution
Not many details have been offered by OpenAI about this technique in use. Here the model could segment the videos into patches thereby enhancing the encoding process.
How can I use SORA?
SORA is in development and is granting access to various visual artists, designers and filmmakers for feedback and to make model advancements. OpenAI does not have a timeline in mind as to when SORA will be made publicly available but is expected to happen sometime this year. For the time being, you can check out more about SORA from OpenAI.
Conclusion
Much like ChatGPT and Dall-E, SORA will also prove to be groundbreaking in the field of Generative AI. One can only anticipate the impressive capabilities of this model and can shed some light during the public release.
That’s a wrap of this little introduction to SORA. See you guys in the next one!


5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning