

Introduction
2024 is the year of Generative AI with the likes of Claude 3 in text generation, Devin AI with software engineering, and even taking strides in image generation with Stable Diffusion 3. It’s been over a month since Stable Diffusion, so let us explore what Stability AI’s new cutting-edge model has to offer!
What is Stable Diffusion?
Stable Diffusion is the brainchild of Stability AI, an open AI brand based in the United Kingdom. It is a group of open-source models used to generate images. Most commonly used as text-to-image generation, it also serves image-to-image and performs inpainting and outpainting. Stable Diffusion has many versions prior to the latest Stable Diffusion 3. Let us look at them briefly.
- Stable Diffusion 1.5, or SD1.5, is the oldest version, launched in August 2022. Being an old model, it outputs an image size of 512 x 512. Although it is an old model, it requires less memory and is hence faster.
- Then there is Stable Difussion 2.1 or SD2.1, launched in October 2022. It had improvements like negative prompts, a text encoder—OpenCLIP, and large image outputs.
- Stable Diffusion, or SDXL, is another model launched in July 2023. It is very popular and can create realistic images in any aspect ratio.
- SDXL Turbo is a super version of SDXL released in November 2023. It can produce great images in one prompt and serves as a non-commercial model, establishing itself as the most advanced open-source image generator.
- Finally, there was SD Turbo, which was also launched in November 2023 and was also a non-commercial model.
Stable Diffusion 3
Stable Diffusion 3, or SD 3, is the latest image generation model from Stability AI. They highlight improvements like better photo-realistic image generation, adherence to strong prompts, and multimodal input.

SD 3 constitutes a suite of models of small sizes, from 800 million parameters to 8 billion parameters. This offers a wide range of scalability and quality to meet the creative needs of the users. Stability AI has given huge preference to safety right from when the model starts training, testing, and evaluation up until final deployment.
What is new in Stable Diffusion 3?
As seen earlier, SD 3 had many predecessor models. But what new does it bring to the table? Let us explore some of them.
Performance
Stable Diffusion 3 can generate a 1024×1024 image with 50 steps in less than 35 seconds on an Nvidia RTX 4090 GPU with 24GB vRAM. Since the model is huge, it requires more GPU compute for faster image generation.
Sampling
Stability AI has given a lot of thought to implementing effective sampling to make it faster and better quality. They discovered a noise schedule that sampled the middle part of the path and produced higher-quality images. The Stable Diffusion 3 model relies on Rectified Flow Sampling, which is the fastest way to go from a noisy to a clear image—at the moment!
Better Text Generation
One of the huge pluses of Stable Diffusion 3 is that it can generate legible, long texts in images, unlike its predecessors, which cannot generate legible texts or are not perfect. SD3 model offers much better text rendering overall.
Text Encoder
Stable Difussion 3 has 3 encoders, unlike its predecessors, which had fewer. They are as follows:
- CLIP l/14
- OpenCLIP bigG/14 and
- T5-v1.1 XXL
Safer
With the chances of generating inappropriate images, Stability AI is taking the safer route by completely removing the generation of NSFW images on their latest model, Stable Diffusion.





Noise Predictor
Noise Predictor estimates the amount of noise in the latent space and subtracts the from the image. This process is repeated for a specific number of times, reducing noise according to user-specific steps. Older Stable Diffusion models like Stable Diffusion 1 and 2 use the U-Net Noise predictor architecture. On the other hand, Stable Diffusion 3 uses a repeating stack of Diffusion Transformers meaning it uses multiple transformers for the diffusion process when compared to previous SD models.
How does Stable Diffusion 3 perform against other models?
The most important question arises in everyone’s mind: How does Stable Diffusion 3 stack up against other text-to-image generation models like Midjourney or DALL-E 3??
Well, to put it into perspective, Stable Diffusion 3 performs superiorly to all of the above!
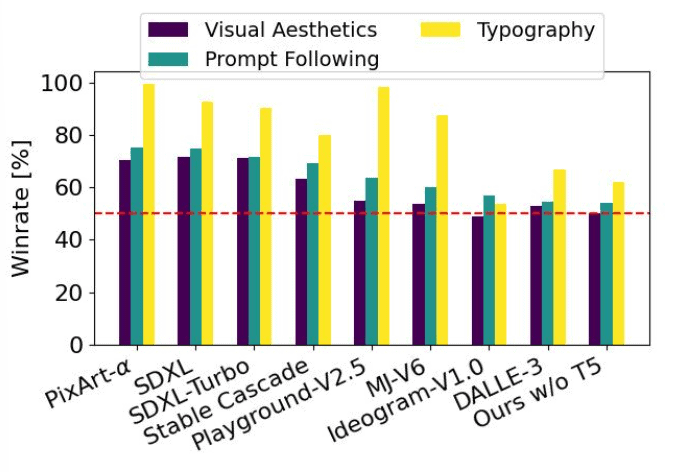
Model Comparison
As seen from the above visualization, Stability AI has performed performance evaluations on SD3 with different models, including predecessors like SDXL, SDXL Turbo, and Stable Cascade, and competitors like Midjourney v6 and DALLE-3, with actual human evaluators. The evaluations were made based on how well the models output the results in the context of the given prompts and how aesthetically pleasing the generated images were. Stable Diffusion 3 marginally outperforms current state-of-the-art text-to-image generation systems in all of the above areas. Stability AI also ran unoptimized inference tests on consumer hardware for the SD3 model, which has 8 billion parameters and fits into the 24GB VRAM of an RTX 4090. Using 50 sampling steps, it took just 34 seconds to generate an image with a resolution of 1024×1024! This is crazy, right?
Limitations of Stable Diffusion 3
Although Stable Diffusion 3 is an impressive architecture and performs much better than its predecessors, it still has a few drawbacks.
- One such drawback is that SD3 feels more aligned with individual creators than enterprises, unlike its competitors like Dall-E, which can work for companies.
- Stable Diffusion requires powerful hardware like an NVIDIA RTX 3060 or an RTX 4020 for optimal performance and results.
- It may not be suitable for all types of images like noisy images or poor contrast images.
- It can be computationally demanding and also time-consuming especially with large visual data.
- This cannot be called an issue but rather a common enemy of all image generative models—misuse. This involves making the models less prone to misuse, like wrongful political imagery or fictitious imagery of celebrities. Although Stable DIiffusion 3 would likely generate only SFW images, making the models less prone to misuse, it is still not completely free from it!
How to access Stable Diffusion 3?
Stability AI is offering Stable Diffusion 3 in the early preview stage. This preview mode provides feedback for analyzing performance, safety, and other metrics. Go check Stable DIffusion 3 for yourselves here! Once you get access, you’ll receive an email invite to the Discord server.
Conclusion
Stable Diffusion has taken image generation up a notch, loaded with new features, and marginally beating its competitors, like MidJourney and DALLE-3, across different assessments.
Stable Diffusion 3 only scratches the surface of the true potential of image generation and the trajectory of Generative AI. That’s a wrap of this fun read. See you guys in the next one!



5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning