
Introduction
Artificial Intelligence is undoubtedly one of the most recent advancements in the technological world. With its growth and applications across a wide array of industries ranging from Healthcare to Virtual Reality in gaming, it has also brought a huge surge in demand for AI professionals. But the field of Artificial Intelligence isn’t a walk in the park. But do not fret.
This read will cover the top 11 AI Skills needed for a successful career in Artificial Intelligence in 2025. So let us get to it!
AI Skills Needed for a Successful Career in Artificial Intelligence
The Global Artificial Intelligence market was valued at $6.3 billion back in 2014. Fast forward a decade, it is expected to hit a staggering $305.9 billion in 2025. This can be attributed to many factors like breakthroughs in Deep Learning and algorithms; combined with the huge computing power, resources, and data storage, AI is not stopping! With over 80% of businesses ranging from SMEs to MNCs adopting Artificial Intelligence into their systems, it is crucial for someone seeking to get into the field to know all the essential artificial intelligence skills needed. Let us kick things off with hard skills!
Hard Skills
Mastering any field requires one to master a set of hard and soft skills, irrespective of the specialization. The field of AI is no different. This section will cover all the hard skills needed for AI mastery, so let’s get to it without wasting any more time!
Mathematics
One of the first hard skills one needs to master is Mathematics. Why is mathematics an AI skill one has to master? What does math have to do with artificial intelligence?
AI systems are primarily built to automate most of the processes and to better understand and aid humans. AI systems constitute models, tools, frameworks, and logic, all of which constitute mathematical topics. Concepts like linear algebra, statistics, and differential calculus all form major topics to kickstart one’s AI career. Let us explore them one by one.
Linear Algebra
Linear algebra is used to solve data problems and computations in machine learning models. It is one of the most important math concepts one needs to master. Most models and datasets are represented as matrices. Linear algebra is used for data preprocessing, transformation, and evaluation. Let us look at some of the major areas of use.
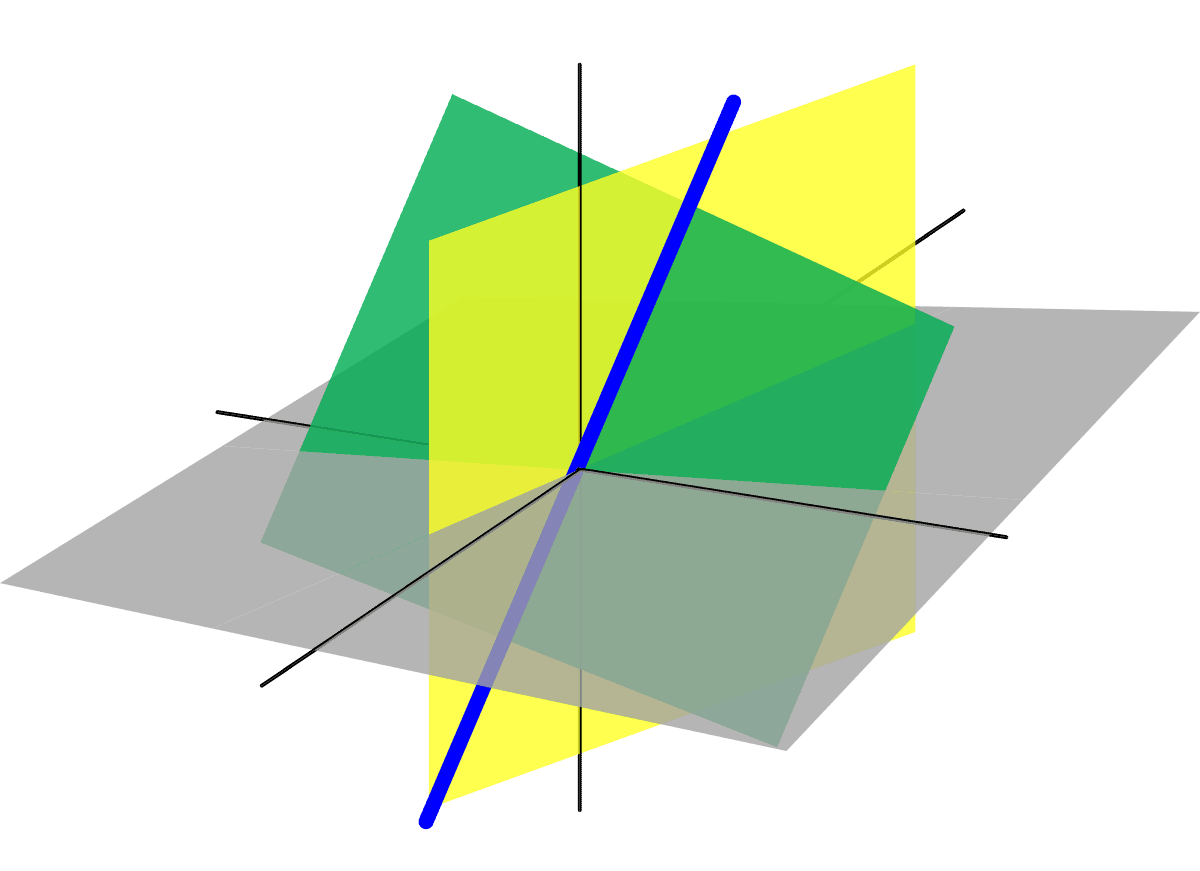
Graphical representation of linear algebra
Data Representation
Data forms a crucial first step in training models. But before this, the data needs to be converted into arrays before it can be fed into the models. Computations are performed on these arrays that return outputs as tensors or matrices. Also, any problems in scaling, rotation, or projection can be shown as matrices.
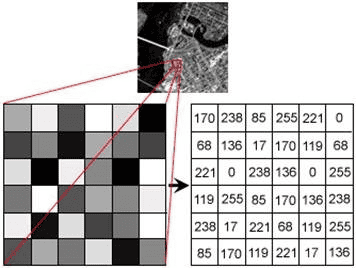
Matrix for certain areas of a Greyscale Image
Vector Embedding
Vector is used to organize data and contains both magnitude and direction. Vector embedding involves leveraging machine learning and artificial intelligence. Here, a specific engineered model is trained to convert different types of images or text into numerical representations as vectors or matrices. Using vector embeddings can drastically improve data analysis and gain insights.
Vector Representation
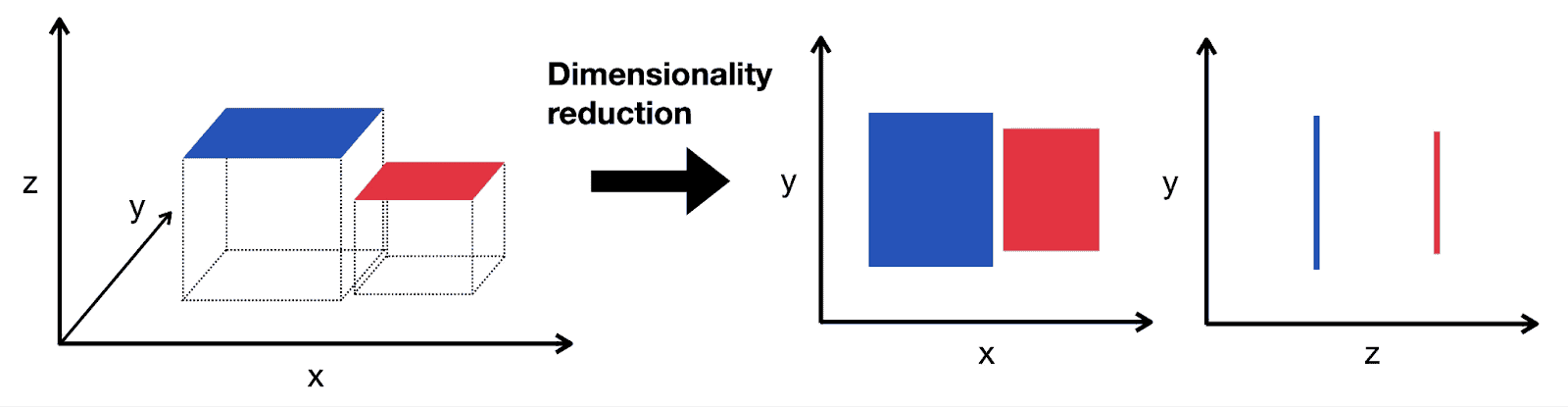
Dimensionality Reduction
This technique is used when we want to reduce the number of features in a dataset while also retaining as much information as possible. With dimensionality reduction, high-dimensional data is transformed into a lower-dimensional space. It reduces the model complexity and improves generalization performance.
Statistics
Statistics is another mathematical concept needed to find unseen patterns from analyzing and presenting raw data. Two common statistical topics one must master are as follows.
Inferential Statistics
Inferential statistics uses samples to make generalizations about larger data. We can make estimates and predict future outcomes. By leveraging sample data, inferential statistics makes inferential manipulations to make predictions.
Descriptive Statistics
In Descriptive statistics, the features are described and data is presented that is purely factual. Predictions are made from known data using metrics like distribution, variance, or central tendency.
Differential Calculus
Differential calculus is the process of finding a derivative from a function. This derivative measures the change in a function rate. Calculus plays a vital role when working with deep learning or machine learning algorithms and models. They aid algorithms in gaining insights from data. Simply put, they deal with the rates at which quantities change.
Differential calculus also finds use for algorithm optimizations and model functions. They measure how a function changes when its input variables change. When applied, algorithms that learn from data improve.
So what is the role of differential calculus in AI?
Well, in AI, we mostly deal with cost functions and loss functions. To find these functions, we need to find the maxima or minimum. To do this, changes need to be made to all the parameters, which is a hassle, i.e., time-consuming and expensive too. This is where techniques like gradient descent come into the picture. They are used to analyze how an output changes when the input is changed.
Mathematics proves to be a foundational step in your AI skills list, aiding in processing data, learning patterns, and gaining insights.
Programming
One of the first AI skills needed to have a successful career in the field is programming. It’s through programming that one can apply AI theories and concepts in applications. For instance, it serves as a building block to build deep learning and machine learning models and train them. Another instance is the help in cleaning, analyzing, and manipulating data.
A few may argue that the improved sophistication of AI would make programming skills less relevant. These systems and algorithms have their limitations. A programmer can drastically improve the efficiency of these systems. The demand for proficient coders is high, with most industries incorporating AI into their operations. It would also keep one relevant in this competitive job market.
There are a ton of coding languages used, the most common ones being C, C++, Java, and Python. Let us take a closer look at them.
Python
Python is one of the most popular programming languages used by developers. It is an interpreted language, meaning it need not be translated into machine language instructions to run programs. Python is considered a general process language that can be used across various fields and industries.
Why has Python gained so much popularity?
- It is compatible with many operating systems, giving it very high flexibility; one need not develop elaborate codes.
- Python drastically reduces the lines of code for execution, reducing the time needed for execution.
- It offers a ton of pre-built libraries like NumPy for scientific computations and SciPy for advanced computations.
C++
C++ is a versatile and powerful programming language that can be used to build high-performance AI systems. It is the second most popular choice among programmers, especially in areas where scalability and performance are critical.
They run models much faster than interpreted languages like Python. C++. Another plus with using C++ is they are able to interface with other languages and libraries.
- Being a compiled language, C++ offers high performance, suitable for building systems requiring high computational power.
- C++ is easier to use for performance optimizations and memory usage.
- Another great aspect is that C++ can run on different platforms, making deploying applications in different environments easy.

With a wide range of libraries and frameworks, C++ is a powerful and flexible language apt for developing deep learning and machine learning during production.
As seen above, programming languages are one of the first foundational steps to a successful career in Artificial Intelligence. Now let us move on to the next AI skill – Frameworks and Libraries.
Frameworks and Libraries
Frameworks and libraries in AI refer to pre-built packages offering all the essential components to build and run models. They usually include algorithms, data processing tools, and pre-trained models. These frameworks serve as a foundation for implementing machine learning and deep learning algorithms. Frameworks eliminate the need for manual coding or coding from scratch, proving very cost-effective for businesses to build AI applications. So why use an AI framework?
- Frameworks come equipped with pre-implemented algorithms, optimization techniques, and utilities for data handling aiding developers in solving specific problems. This facilitates the app development flow.
- As discussed earlier, frameworks are very cost-effective. Development costs are drastically curbed due to the availability of pre-built components. Companies are able to create applications in a more efficient manner and a much shorter span when compared to traditional methods.
Frameworks can be broadly classified into
- Open Source Frameworks
- Commercial Frameworks
Let us delve a bit into them.
Open Source Frameworks
Frameworks that are released under an open-source license are open-source frameworks. Users can use it for any purpose. They are free to use and usually include the source code and permits derived works. Backed by an active community, one can find a ton of resources for troubleshooting and learning.
Commercial Frameworks
Unlike open-source frameworks, commercial frameworks are developed and licensed by specific brands. Users are limited to what they can do with the software and could be levied additional fees. Commercial frameworks usually have dedicated support in case one bumps into any issues. Since these frameworks are owned by a specific company, one can find advanced features and optimizations that are usually user-focused.
That’s enough about the types of frameworks. Let us explore the essential Frameworks and Libraries you can add to your AI skills list.
PyTorch
PyTorch is an open-source library developed by Meta in 2016. It is mainly used in deep learning, computer vision, and natural language processing. It is easy to learn due to the efforts made by the devs to improve its structure, making it very similar to traditional programming. Since most tasks in PyTorch can be automated, productivity can be improved drastically. With a huge community, PyTorch offers much support from devs and researchers alike. GPyTorch, Allen NLP, and BoTorch are a few popular libraries.

TensorFlow
TensorFlow is an open-source framework developed by Google in 2015. It supports many classification and regression algorithms and is used for high-performance numerical computations for machine learning and deep learning. TensorFlow is used by giants like AirBnB, eBay and Coca-Cola. It offers simplifications and abstractions, keeping the code small and more efficient. TensorFlow is widely used for image recognition. There is also TensorFlow Lite, where one can deploy models on mobile and edge devices.

MLX
Much like the previous frameworks we discussed, MLX is also an open-source framework developed by Apple to deploy machine learning models on Apple devices. Unlike other frameworks like PyTorch and TensorFlow, MLX offers unique features. MLX is specifically built for Apple’s M1, M2, and M3 series chips. It leverages Neural engine and SIMD instructions, significantly increasing the training and inference speed compared to other frameworks that run on Apple hardware. The result: smoother and more responsive experience on iPhones, iPads and Macs. MLX is a powerful package for developers with superior performance and flexibility. One drawback is that being a fairly new framework, it may not offer all the features of its seasoned counterparts like TensorFlow and PyTorch.
SciKit-learn
SciKit-learn is a free, open-source Python library for machine learning built on NumPy, SciPy, and Matplotlib. It offers a clean, uniform, and streamlined API accompanied by comprehensive documentation and tutorials, data mining, and machine learning capabilities. Switching to another model or algorithm is easy once a developer understands the basic syntax for one model type. SciKit-learn offers an extensive user guide to quickly access resources ranging from multilabel algorithms to covariance estimation. It is diverse and used for smaller prototypes to more complex deep learning tasks.

Keras
Keras is an open-source, high-level neural networks API that runs over other frameworks. It is a part of the TensorFlow library where we can define and train neural network models in just a few lines of code. Keras offers simple and consistent APIs, reducing the time to run common codes. It also takes less prototyping time, meaning models can be deployed in a shorter span of time. Giants like Uber, Yelp, and Netflix use Keras.

Data Engineering
The 21st Century is the era of Big Data. Data is a crucial aspect that fuels the innovation behind Artificial Intelligence. It offers the information to businesses to streamline their processes and make informed decisions aligned with their business goals. With the explosion of IoT (Internet of Things), social media, and digitization, the volume of data has advanced drastically. But with this vast volume of data, collecting, analyzing, and storing it is quite challenging. This is where data engineering comes into the picture. It is primarily used to construct, install, and maintain systems and pipelines, facilitating organizations to collect, clean, and process data efficiently.
Although we covered Statistics in one of the previous sections, it also plays an important role in data engineering. The basics would aid data engineers in understanding the project requirements better. Statistics help in drawing inferences from data. Data engineers can leverage statistical metrics to measure the use of data in a database. It’s good to have a basic understanding of descriptive statistics, like calculating percentiles from collected data.
Now that we’ve understood what data engineering is, we’ll go a little deeper into the role of data engineering in Artificial Intelligence.
Data Collection
As the name suggests, data collection is collecting data from various sources to extract insightful information. Where can we find data? Data can be collected from various sources like online tracking, surveys, feedback, and social media. Businesses leverage data collection to optimize work quality, make market forecasts, find new customers, and make profitable decisions. There are three ways for data collection.
First-Party Data Collection
In this form of data collection, the data is directly obtained from the customer. This could be by way of websites, social media platforms, or apps. First-party data is accurate and highly reliable, with no one involved in the middle. This form of data collection refers to customer relationship management data, subscriptions, social media data, or customer feedback.
Second-Party Data Collection
Second-party data collection is where data is collected from trusted partners. This could be a business outside of the brand collecting the data. This is quite similar to first-party data since the data is acquired through reliable sources. Brands leverage second-party data to get better insights and scale up their business.
Third-Party Data Collection
Here, the data is collected from an outside source unrelated to the business or the customer. This form of data is collected from various sources and then sold to various brands for marketing and sales purposes. Third-party data collection offers a much wider audience range than the previous two. But this comes at a cost; the data needs to be reliable and would not be collected with adherence to privacy laws.
Data Integration
Data Integration dates back to the 80s. The main intent was to suppress the differences of relational databases using business rules. In those days, data integration depended more on physical infrastructures and tangible repositories, unlike today’s cloud technology. Data Integration involves combining various data types from different sources into one dataset. This can be used to run applications and aid business analytics. Businesses can leverage this dataset to make better decisions, drive sales, and offer better customer experience.
Data integration is found in almost every sector ranging from finance to logistics. Let us explore some of the different types of data integration methods.
Manual Data Integration
This is the most basic technique of data integration. With Manual data integration, we have full control over the integration and management. A data engineer can conduct data cleansing, re-organization, and manually move it to the desirable destination.
Uniform Data Access Integration
In this form of integration, data is displayed consistently for ease of usability while keeping the data source at its original location. It is simple, offers a unified view of data, offers multiple systems or apps to connect to one source, and does not require high storage.
Application-Based Data Integration
Here, software is leveraged to locate, fetch, and format data which is then integrated into the desired destination. This includes pre-built connections to a variety of data sources and being able to connect to additional data sources if necessary. With application-based data integration, the data transfer happens seamlessly and uses fewer resources, thanks to automation. It is also simple to use and does not always require technical expertise.
Common Storage Data Integration
With more voluminous data, companies are resorting to more common storage options. Much like the uniform access integration, the information undergoes data transformation before it is copied to a data warehouse. With the data in one location accessible at any time, we can run business analytical tools when needed. This form of data integration offers higher data integrity and is less strenuous on data host systems.
Middleware data integration
Here, the integration happens between the application layer and the hardware infrastructure. A Middleware data integration solution transfers data from various applications to databases. With Middleware, the network systems communicate better and can transfer enterprise data in a consistent manner.
Machine Learning Approaches and Algorithms
Computer programs that can adapt and evolve based on the data they process are Machine Learning Algorithms. Referred to as training data, they are essentially mathematical data that learn through data fed to them. Machine Learning algorithms are one of the most widely used algorithms today. They are integrated into almost every form of hardware, from smartphones to sensors.
Machine learning algorithms can be categorized in different ways depending on their purpose. We’ll delve into each of them.
Supervised Learning
In Supervised learning, machines learn by example. They gain inferences from previously learned data to get new data using labeled data. The algorithm identifies patterns in the data and makes predictions. The algorithm makes predictions and is corrected by the dev until it attains high accuracy. Supervised learning includes
- Classification – Here, the algorithm draws inferences from observed values and determines which category the new observation belongs to.
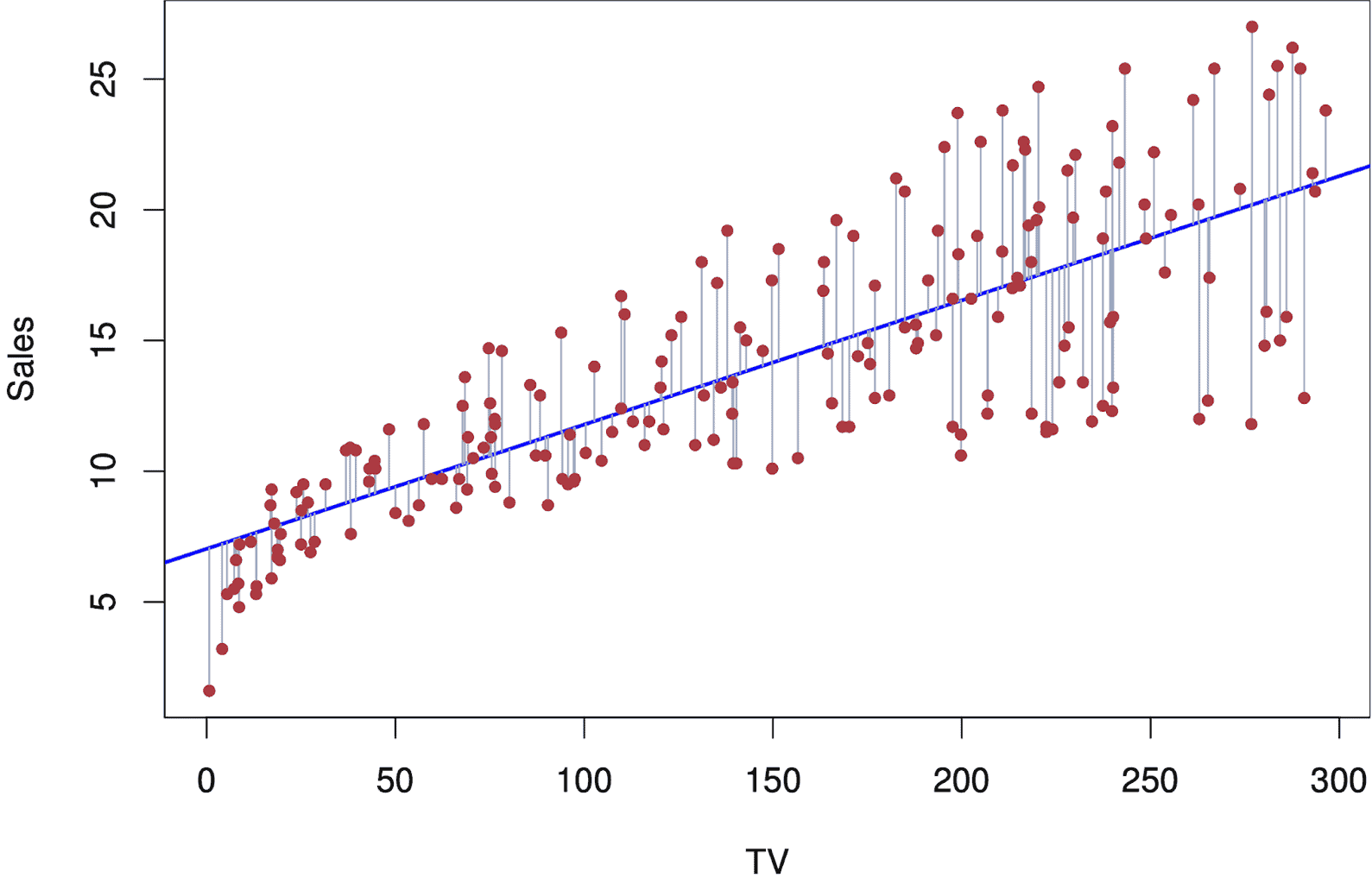
- Regression – In regression, the relationship between the various variables is understood where the emphasis is placed on one dependent variable and a series of other changing variables, making it useful for predictions and forecasting.
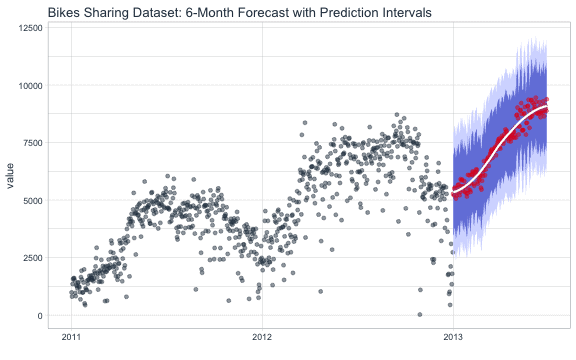
- Forecasting – It is the process of making future predictions based on past and present data.
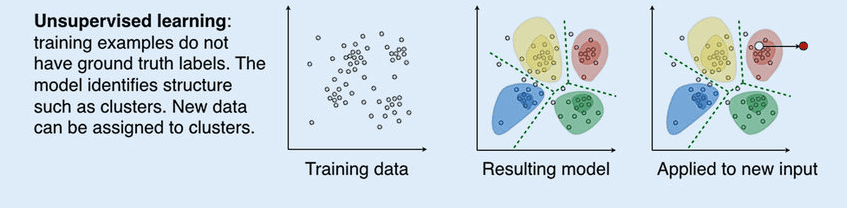
Unsupervised Learning
In unsupervised learning, the algorithms analyze data to get patterns. The machine studies the available data and infers the correlations. The algorithm interprets large data and tries to organize it in a structured manner. Unsupervised learning includes
- Dimension reduction – This form of unsupervised learning reduces the number of variables considered to find the information required.
- Clustering – This involves grouping similar data sets based on some defined criteria.
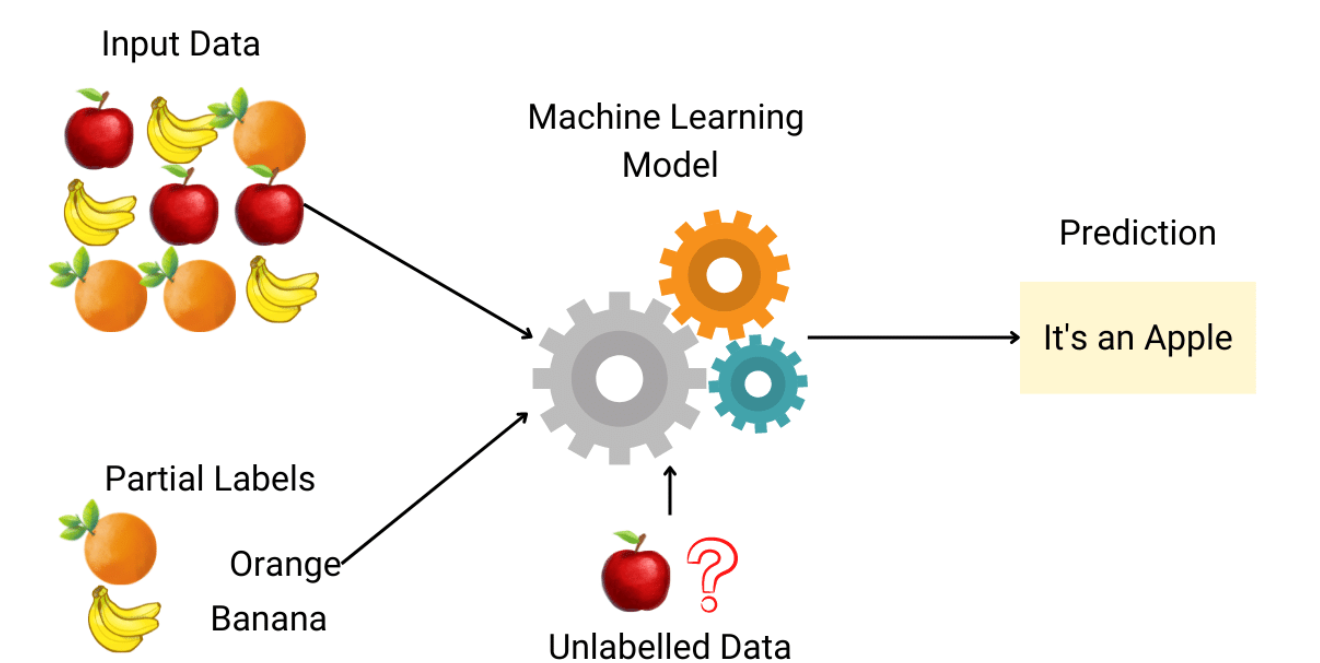
Semi-supervised Learning
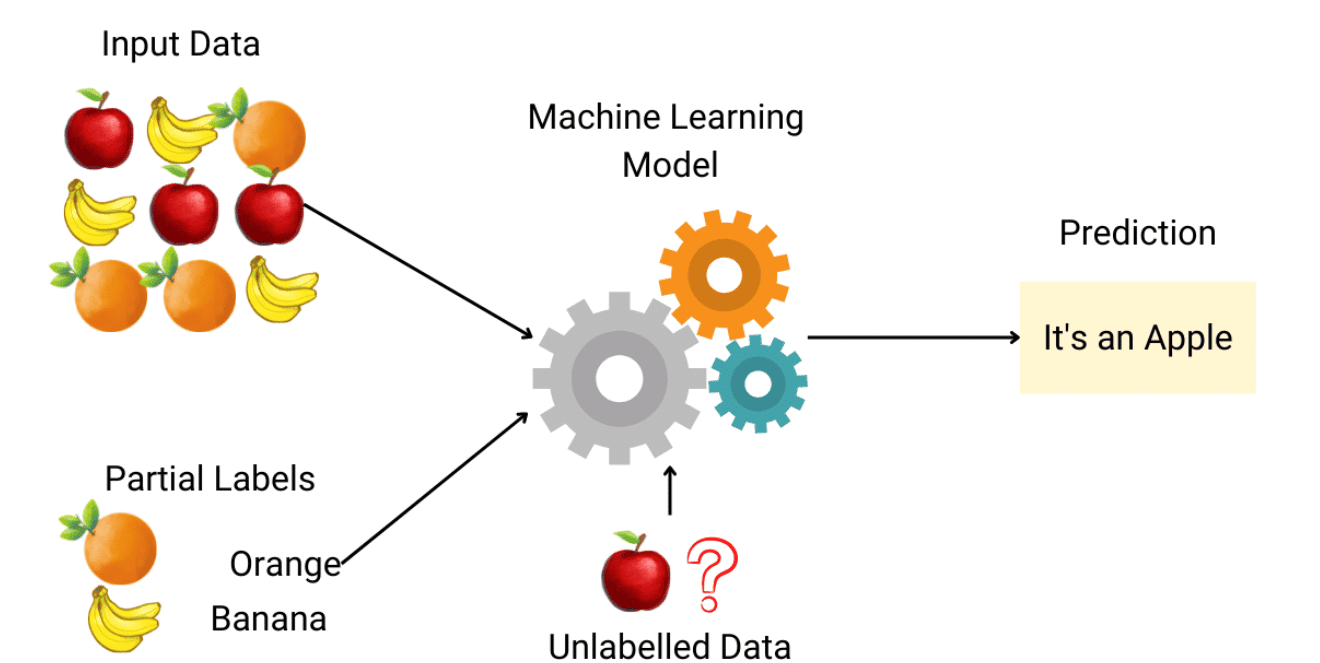
Semi-supervised learning, or SSL, is an ML technique that leverages a small portion of labeled data and loads of unlabeled data to train a predictive model. With this form of learning, expenses are reduced on manual annotation and curbs data prep time. Semi-supervised learning serves as a bridge between supervised and unsupervised learning and solves their problems. SSL can work for a range of problems ranging from classification and regression to association and clustering. Since there is an abundance of unlabeled data and are relatively cheap, SSL can be used for a ton of applications without compromising on accuracy.
Let us explore some of the common machine learning algorithms.





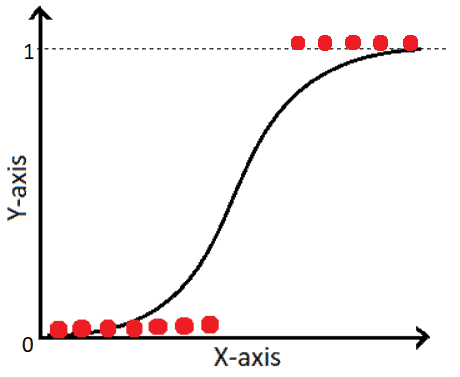
Logistic Regression
Logistic regression is a form of supervised learning used to predict the probability of a yes or no based on prior observations. These predictions are based on the relationship between one or a few existing independent variables. Logistic regression proves to be paramount in data preparation activities by putting data sets into predefined containers during extraction, transformation, and load processes to stage the information.
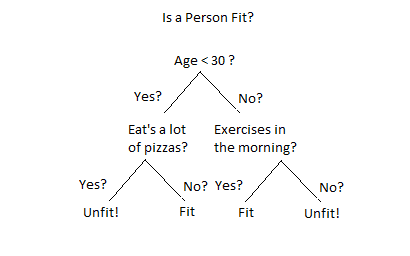
Decision Tree
Decision Tree is a supervised learning algorithm that creates a flow diagram to make decisions based on numeric predictions Unlike other supervised learning algorithms, we can solve regression and classification problems too. By learning simple decision rules, the class or value of the target variable can be predicted. Decision trees are flexible and come in various forms for business decision-making applications. They use data that does not need much cleansing or standardization and do not take much time to train new data.
Naive Bayes
Naive Bayes is a probabilistic ML algorithm used for various classification problems like text classification where we train high dimensional datasets. It is a powerful predictive modeling algorithm based on the Bayes Theorem. Building models and making predictions are much faster with this algorithm, but it requires high expertise to develop them.
Random Forest
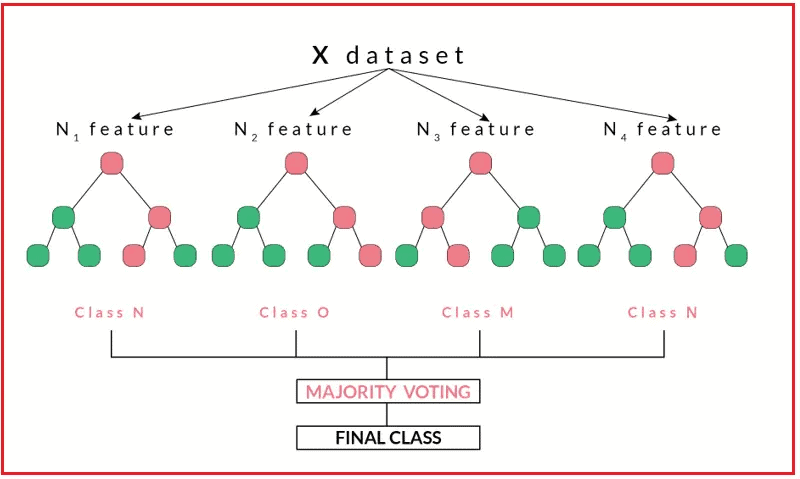
Random forest is a famous ML algorithm used for classification and regression tasks that also uses supervised learning methods. It produces great results even without hyper-parameter tuning. It’s a go-to algorithm amongst machine learning practitioners due to its simplicity and diversity. Random forest is a classifier that contains several decision trees on different subsets of a given dataset and finds the average to optimize the accuracy of that dataset.
K Nearest Neighbour (KNN)
KNN is a simple algorithm that stores all the available cases and classifies the new data. It is a supervised learning classifier used to make predictions leveraging proximity. Although it finds use in classification and regression tasks, typically, it is used as a classification algorithm. It can handle both categorical and numerical data making it flexible for different types of datasets for classification and regression tasks. Due to its simplicity and ease of implementation, it is a common go-to for developers.
Machine learning algorithms are important in harnessing one’s AI skills and growing towards a successful career in artificial intelligence. In this section, we covered the different types of ML algorithms and some common techniques. Let us head over to the next AI skill – Deep learning.
Deep Learning
The recent advances in Artificial Intelligence can be attributed to Deep Learning, ranging from large language models like ChatGPT to self-driving cars like Tesla.
So what exactly is Deep Learning?
Deep Learning is a subfield of Artificial Intelligence that tries to replicate the workings of the human brain in machines by processing data. Deep learning models analyze complex patterns in texts, images, and other forms of data producing accurate insights and predictions. Deep learning algorithms need data to solve problems; in a way, it is a subfield of Machine Learning. But unlike machine learning, deep learning constitutes a multi-layered structure of algorithms called Neural Networks.
Neural networks are computational models that try to replicate the complex functions of the human brain. Neural networks have multiple layers of interconnected nodes that process and learn from data. By analyzing the hierarchical patterns and features in the data, neural networks can learn complex representations of the data.
Types of Neural Networks
This section will discuss the commonly used architectures in deep learning.
Convolutional Neural Networks
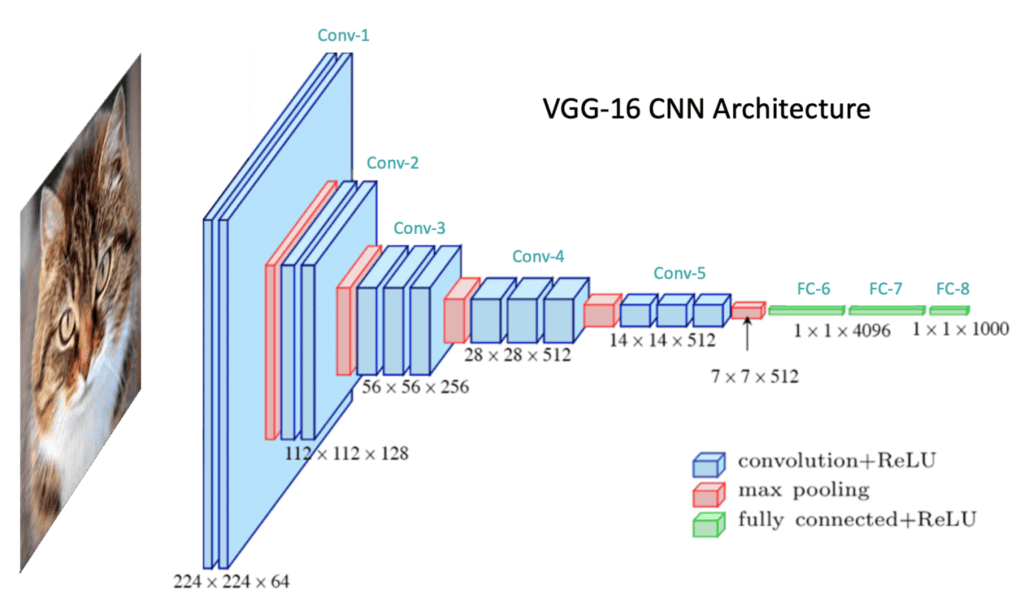
Convolutional Neural Networks, or CNNs, are deep learning algorithms designed for tasks like object detection, image segmentation, and object recognition. They can autonomously extract features at a large scale, removing the need for manual feature engineering and enhancing efficiency. CNNs are versatile and can be applied to domains like Computer Vision and NLPs. CNN models like ResNet50 and VGG-16 can adapt to new tasks with little data.
Feedforward Neural Networks
An FNN, also called a deep network or multi-layer perceptron (MLP), is a basic neural network where the input is processed in one direction. FNNs were among the first and most successful learning algorithms being implemented. An FNN comprises an input layer, an output layer, a hidden layer, and neuron weights. The input neuron receives data that travels through the hidden layers and leaves through the output neuron.
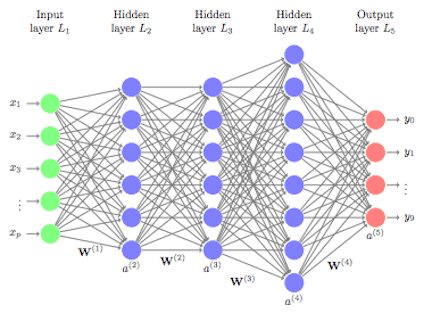
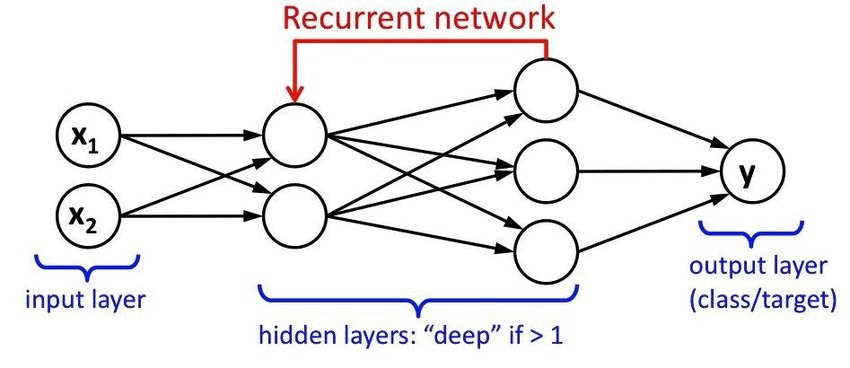
Recurrent Neural Networks
RNNs are state-of-the-art algorithms that process sequential data like time series and natural language. They maintain an internal state that captures information about previous inputs, making them apt for speech recognition and language translations like Siri or Alexa. RNNs are the preferred algorithm for sequential data like speech, text, audio, video, and more.
Deep learning constitutes many subtypes, a few of which we’ll explore.
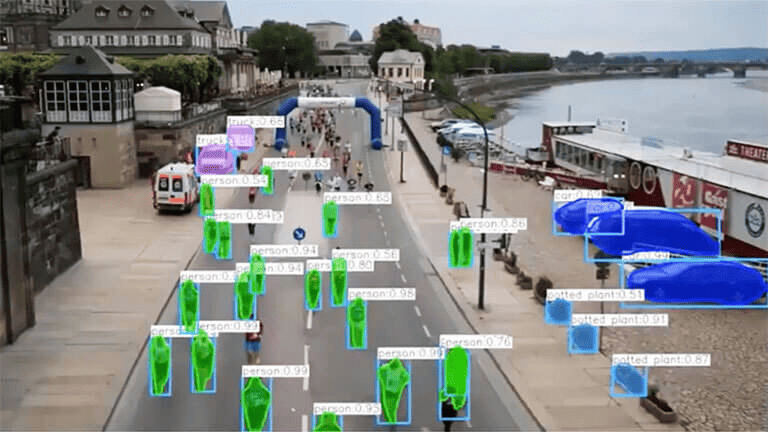
Computer Vision
Computer Vision, or CV, is another field in AI that has seen a boom in recent years. We can owe this to the vast availability of data (roughly 3 billion images being shared daily) generated today. We can date Computer Vision back to the 50s.
What is Computer Vision?
Computer Vision is a subfield of AI that trains machines and computers to interpret their surroundings like we do. In simple terms, it gives the power of sight to machines. In the real world, this could take the form of face unlock on our mobile phones or filters on Instagram.
Are you looking to deep dive into Computer Vision? Check out our comprehensive guide here.
Natural Language Processing (NLP)
Another subfield that accelerates Deep Learning, Natural language processing, or NLP, deals with giving machines the ability to process and understand human language. We’ve all used NLP tech in some form or another, for instance, virtual assistants like Amazon’s Alexa or Samsung’s Bixby. This technology is typically based on machine learning algorithms to analyze examples and make inferences based on statistics, meaning the more the machine receives data, the more accurate the result will be.
How does NLP benefit a business?
NLP systems can analyze and process large volumes of data from different sources, from news reports to social media, and offer valuable insights to assess the brand’s performance. By streamlining processes, this tech can make data analysis more efficient and effective.
NLP tech comes in different shapes and sizes in the form of Chatbots, autocomplete tools, language translations, and many more. Some of the key aspects for one to learn to master NLP include
- Data Cleaning
- Tokenization
- Word Embedding
- Model Development
Possessing strong basics of NLP and Computer Vision can open doors to high-paying roles like Computer Vision Engineer, NLP Engineer, NLP Analyst and many more.
Deployment
Model deployment is the final step that ties all of the above together. It is the process of facilitating accessibility and its operations within a confined environment where they can make predictions and gain insights. Here, the models are integrated into larger systems. These predictions are made available to the public for their use. This could pose a challenge for different reasons like testing and scaling or differences between model development and training. But with the right model frameworks, tools, and processes, they can be overcome.
Traditionally models were deployed on local servers or machines, which limited their accessibility and scalability. Fast forward to today, with cloud computing platforms like Amazon Web Services and Azure, deployment has become a lot more seamless. They have improved how the models are deployed, manage resources, and handle scaling and maintenance complexities.
Let us look at some of the core features of model deployment.
Scalability
Model scalability refers to the ability of a model to handle huge volumes of data without compromising performance or accuracy. It involves
- Scaling up or down on cloud platforms based on the demand
- It ensures optimal performance and makes it more cost-effective
- Offers load balancing and auto-scaling – which are crucial for handling varying workloads and ensuring high availability
- Helps gauge if the system is able to handle increasing workloads and how adaptable it can be
Reliability
This refers to how well the model performs what it was intended to do with minimal errors. Reliability depends on a few factors.
- Redundancy is having backups for critical resources in case of failures or unavailability.
- Monitoring is done to assess the system during deployment and resolve any issues that pop up.
- Testing validates the correctness of the system before and after its deployment.
- Error Handling is how the system recovers from failures without compromising the functionality and quality.
Cloud Deployment
The next step is to select the deployment environment specific to our requirements, like costs, security, and integration capabilities. Cloud computing has come a long way over the past decade. Cloud model deployment options were very limited during its initial years.
What is Cloud deployment?
It is the arrangement of distinct variables like ownership and accessibility of the distributed framework. It serves as a virtual computing environment where we can choose a deployment model based on how much data we want to store and who controls the infrastructure.
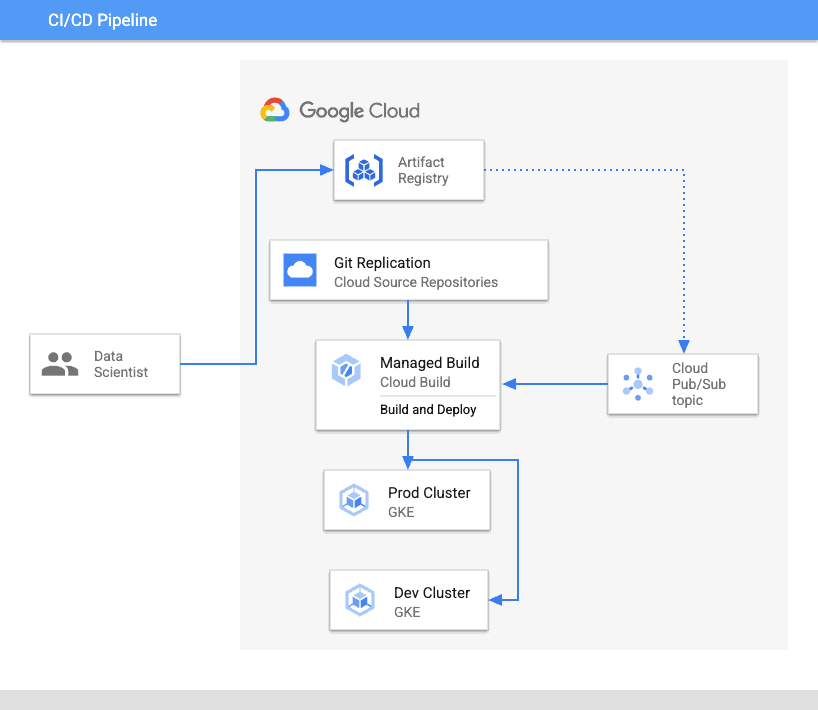
Private Cloud
This is where the company builds, operates, and owns its data centers. MNCs and large brands often adopt private cloud for better customizations and compliance requirements although it would need investment in software and staffing. Private clouds best fit companies looking to have good control over data and resources and also curb costs. It is ideal for storing confidential data which is only accessible by authorized personnel.
Public Cloud
Public cloud deployment involves third-party providers who host the infrastructure and software shared data centers. Unlike the private cloud, one can save on infrastructure and staffing costs. They are easy to use and are more scalable.
Hybrid Cloud
It is a cloud type that combines a private cloud with a public cloud. They facilitate the movement of data and applications move in between two environments. Hybrid platforms offer more
- Flexibility
- Security
- Deployment options
- Compliance
Choosing the right public cloud provider can be a daunting task among the hundreds. So let us make it easier for you as we have picked out the top players dominating the market.
Amazon Web Services
Developed by Amazon, AWS was launched in 2006 and was one of the first pioneers in the cloud industry. With over 200 cloud services across 245 countries, AWS stands at the top of the leaderboard with 32% of the market share. It is used by giants like Coca-Cola, Adobe and Netflix.

Google Cloud Platform
Launched in 2008 and started out as an “App Engine” that became Google Cloud Platform in 2012. Today it boasts 120 cloud services, a good choice for developers. Compute Engine, one of its best features supports any operating system and offers custom and predefined machine types.

Microsoft Azure
Azure was launched in 2010, offering traditional cloud services across 46 regions and taking the second-highest share in the cloud market. One can quickly deploy and manage models, deploy and manage models, and share for cross-workspace collaborations.

Monitoring Model performance
Once the models are deployed, the next step is to monitor the models.
Why monitor the model’s performance?
Models usually degrade over time. From the time of deployment, the model starts to lose its performance slowly. This is done to ensure that they perform as expected and consistently. Here we track the behaviour of the deployed model and analyze and make inferences from them. Next, if the model requires any updates in production, we need a real-time view to make evaluations. This can be made possible through validation results.
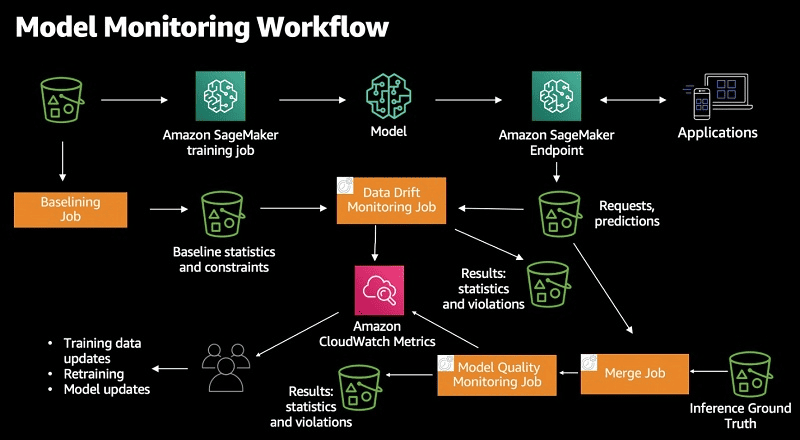
Monitoring can be categorized into:
- Operational level monitoring is where one needs to ensure that the resources used for the system are healthy and will be acted upon if otherwise.
- Functional level monitoring is where we monitor the input layer, the model, and the output predictions.
Resource Optimization
Resource optimizations form a critical aspect of model deployment. This is especially good when the resources are limited.
One way of optimizing resources is by making adjustments to the model itself. Let us explore a few methods.
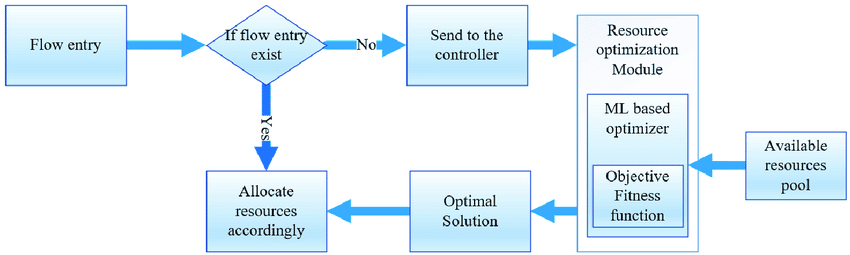
Simplification
One way to optimize a model could be to adopt one with simpler and fewer components or operations. How do we do this? By using the below-mentioned features:
- Models with smaller architectures
- Models that have fewer layers
- Models that have faster activation functions
Pruning
Pruning is the process of removing unwanted parts of a model that do not contribute much to the output. It involves reducing the number of layers or connections in the model, making it smaller and faster. Some common pruning techniques are
- Weight pruning
- Neuron pruning
Quantization
Model quantization is another method to make a model more optimal. This involves reducing the bit-width of the numerical values used in the model. Much like the previous model optimization methods, quantization can lower a model’s memory and storage needs and bump up the inference speed too.
This concludes the technical AI skills needed to tread the Artificial intelligence path. But wait, there’s more; I’m talking about soft skills. What exactly are soft skills, and why do they matter? The next section discusses that in detail.
Soft Skills
Soft skills are the “non-essentials” one needs to possess besides their field expertise. Soft skills are something inside us all, it’s not something we learn through books or coursework. Soft skills are the bridge between your technical prowess and your employer or peer, i.e., how effectively you are able to communicate and collaborate. According to Delloite Insights, 92% of brands say soft skills have similar weightage to hard skills. They demonstrate a person’s ability to make internal communications within a company, lead teams, or make decisions to improve the business’s performance.
Let us explore some of the crucial soft skills one must possess to have an edge over others.
Problem-Solving
Why are you hired for a job role? To use your expertise in your field to solve problems. This is another important soft skill that requires one to identify the problem, analyze it, and implement solutions. It is one of the most sought-after skills with 86% of employers looking for resumes possessing this skill. At the end of the day, companies are always on the lookout for talent that can solve their problems. Anyone who is a good problem solver will always be of value in the job market.
Critical thinking
With many more automation processes in place, it becomes paramount for leaders and experts to interpret and contextualize results and make decisions. Critical thinking helps in evaluating these outcomes offering a factual response. Logical reasoning facilitates one to identify any discrepancies in the system. This involves a mix of rational thinking separating the relevant from the irrelevant and reflective thinking where one considers the context of the information they’ve got and considers its implications. So in all its simplicity, it involves solving complex problems by analyzing the pros and cons of various solutions using logic and reasoning rather than gut instinct.
Intellectual Curiosity
Probing forms a key aspect of one’s career arsenal. It is the eagerness to probe into things, ask questions, and delve deeper. Curiosity prompts one to venture out of one’s comfort zone and explore unchartered territory in their specialized field. Although AI systems can analyze and make inferences from vast amounts of data, they lack the understanding or ability to question. The more one probes, the more one can bring innovation to the table.
Ethical Decision Making
With the vast data available today, AI systems operate large datasets and make inferences from patterns drawn from this data. However, we cannot rely on these systems to make right or fair decisions since they can rely on societal biases. These biases can lead to organizational discrimination due to perpetuating inequities if left unattended.
This is where ethical decision-making comes into play. It sheds light on the ability of one to ensure that the outcome safeguards the freedom of an individual or individuals and aligns with societal norms. This ensures that the deployed system is not used in an invasive or harmful manner.
Conclusion
We’ve finally come to the end of this super comprehensive read. We’ve covered all the essential hard skills like programming and deep learning to soft skills like critical thinking and problem solving. I hope this read has given you insights and the right mindset to kickstart your journey in harnessing your AI skills. Keep your eyes peeled, more fun reads coming your way. See you guys in the next one!




{kind=link}
{kind=link}
5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning