
Spoiler: They’re much better now!

About the author:
Dmytro Mishkin is a postdoc at Czech Technical University in Prague, working in the area of image matching and a computer vision and deep learning consultant.
OpenCV RANSAC is dead. Long live the OpenCV USAC!
Last year a group of researchers including myself from UBC, Google, CTU in Prague and EPFL published a paper “Image Matching across Wide Baselines: From Paper to Practice“, which, among other messages, has shown that OpenCV RANSAC for fundamental matrix estimation is terrible: it was super inaccurate and slow. Since that time my colleague Maksym Ivashechkin spent much of summer 2020 improving OpenCV RANSACs. His work was released as a part of OpenCV 4.5.0 release.
Now it is time to benchmark them. Let’s go!
RANSAC
Let’s first recall what RANSAC is for. The abbreviation stands for RANdom SAmple Consensus, an algorithm proposed in 1981 for robust estimation of the model parameters in a presence of outliers- that is, data points which are noisy and wrong.
The widest adoption of this technique in computer vision is for relative camera pose and perspective transform estimation. Obviously, it is available in OpenCV and covered in its tutorials.
Since the original paper publication, hundreds of researchers proposed a series of improvements, making RANSAC faster, more precise and more robust.
Benchmark
Despite these improvements there was no “downstream-metric” evaluation, showing how RANSAC influences the performance of the camera pose estimation system. This is where “Image Matching across Wide Baselines: From Paper to Practice” and series of the CVPR Image Matching Challenges comes into play. They are using a state-of-the-art structure from motion algorithm to reconstruct a scene from thousands of images and obtain precise camera poses for each. These camera poses are used as ground truth to evaluate different parts of the image matching pipeline, including RANSACs.
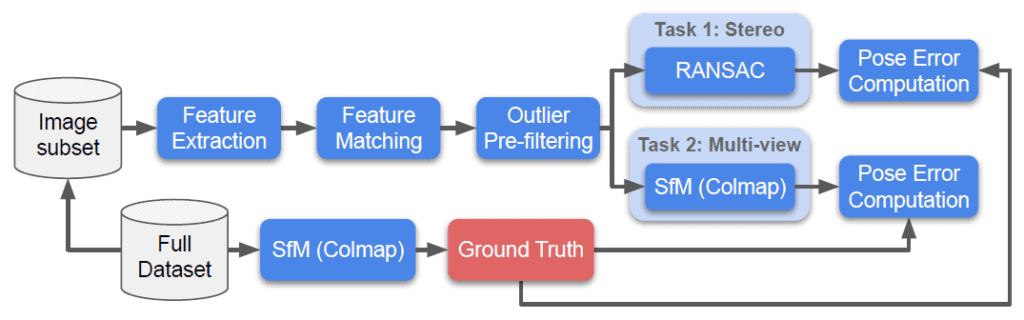
In our tests, we’ve run the benchmark on the validation subset of the Image Matching Challenge 2021 datasets — PragueParks, GoogleUrban and Phottourism. We have detected RootSIFT features, matched them with optimal mutual SNN ratio tests and then fed them into the tested RANSACs. The resulting fundamental matrixes were transformed into relative poses and compared to the ground truth poses. You can check details in the paper “Image Matching across Wide Baselines: From Paper to Practice“.
For all RANSACs we first determined the optimal inlier threshold by the grid search, whereas the number of iterations ( max_iter ) was set to a reasonable 100k. Then, after fixing this optimal threshold, we vary the number of iterations from 10 to 10M. This gives us an accuracy-time curve.
Methods evaluated
Here we have mostly evaluated the RANSAC methods implemented in OpenCV, but also added a couple of baselines. The included Non-OpenCV methods are as follows:
- PyRANSAC – The LO-RANSAC implementation from pydegensac package. It should be roughly equivalent to the basic OpenCV RANSAC. LO stands for “local optimization,” which is used to improve intermediate results.
- DEGENSAC – From pydegensac package, based on the original implementation of the method, proposed in CVPR 2005 paper “Two-View Geometry Estimation Unaffected by a Dominant Plane“. When the relative camera pose in a form of fundamental matrix is estimated from the correspondences which all lie on the same plane, the result is often incorrect. DEGENSAC detects and fixes such cases. This algorithm is the default choice for the Image Matching Challenge 2020 and 2021.
The OpenCV methods, named after the flag, one needs to pass into cv2.findFundamentalMatrix function, are as follows:
- RANSAC — OpenCV (vanilla) RANSAC implementation from the previous versions of the library, without the bells and whistles.
- USAC_DEFAULT – equivalent to the DEGENSAC above in terms of algorithm, but differs in the details of implementation.
- USAC_FAST – same as USAC_DEFAULT above, but has different hardcoded parameters and potentially should work faster, due to using fewer iterations in the local optimization step than USAC_DEFAULT — Also uses RANSAC score to maximize the number of inliers and terminate earlier.
- USAC_ACCURATE — Implements recent Graph-Cut RANSAC. Instead of simple local optimization, an energy minimization graph-cut algorithm is used. It allows to sometimes estimate a correct model from a sample, which contains outliers.
- USAC_MAGSAC — It implements another recent algorithm: MAGSAC++. It is inspired by deep learning solutions and uses iterative re-weighted least squares optimization combined with a soft threshold to make use of roughly correct, but imprecise correspondences.
All OpenCV USAC methods also use SPRT-test for speeding-up the evaluation.
Results
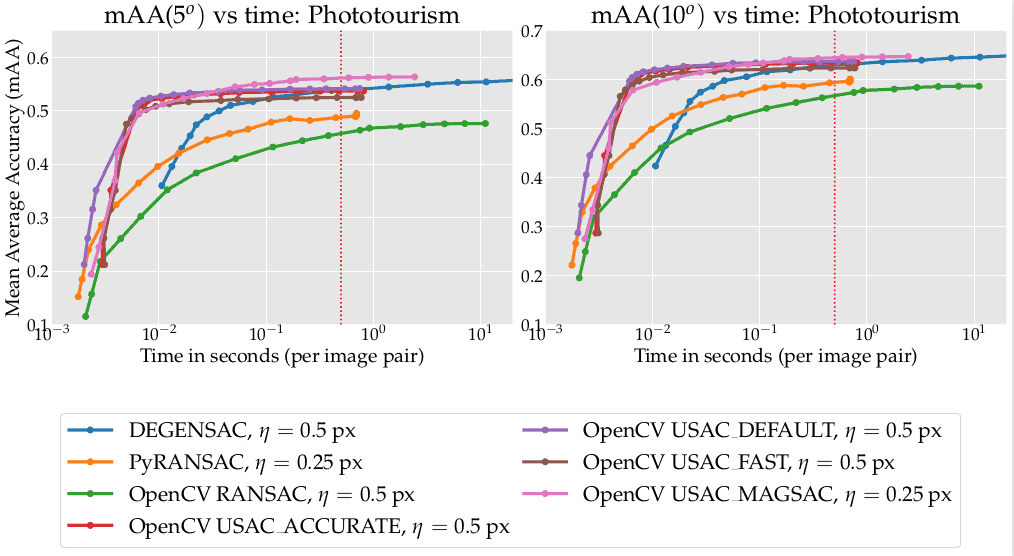
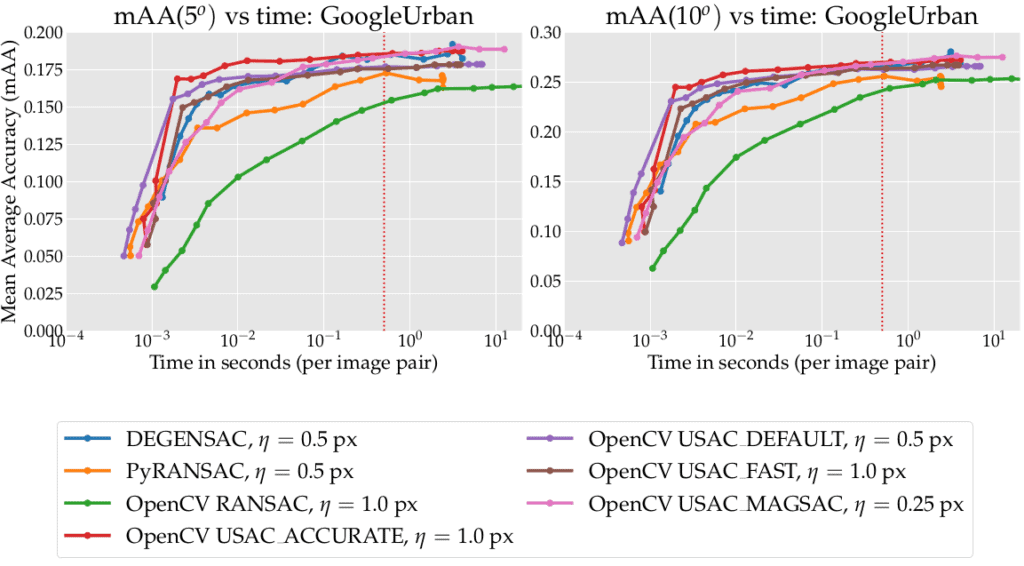
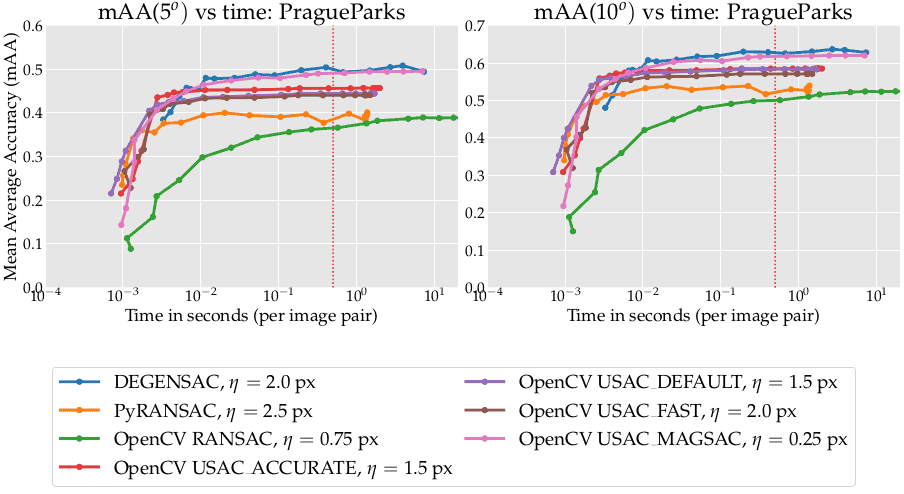
Below are results for all 3 datasets. The farther left and higher the curve, the better. The dashed vertical lines mark the 1/25 sec (“realtime”) and 0.5 sec (challenge limit) time budgets. The legend shows the method name and the optimal inlier threshold for the datasets: Phototourism, GoogleUrban and PragueParks respectively.






1. The first and main conclusion — all of the new flags are much better than the old OpenCV implementation (green curve, worst results), which is still the default option.
2. USing 10k iterations and USAC_ACCURATE (red curve) gives you great results within 0.01 sec
3. All OpenCV advanced USACs are better for the small/medium time budget (< 0.1 sec per image) than pydegensac (blue curve).
4. The best methods for the higher budget are OpenCV USAC_MAGSAC and DEGENSAC from the pydegensac package.
5. There is no point in using the “USAC_FAST” flag- it is always better to use USAC_DEFAULT, USAC_ACCURATE or USAC_MAGSAC.
6. USAC_MAGSAC is the only method whose optimal threshold is the same across all datasets. This is a valuable property for practice, as it requires the least tuning. I would recommend to use it as a default solution
If you are interested in results for individual datasets, read on.
Phototourism
GoogleUrban
PragueParks
Why are tuning and evaluation done on the same set?
It is true that tuning and evaluation of the method on the same dataset does not make any sense. However, let me defend my choice. Here are the arguments:
1. I do not want to compromise the integrity of the test set, which is the basis of the on-going competition Image Matching Challenge 2021 which includes a cash prize. That is why I do not want to leak information from the aforementioned test set and this is my primary optimization objective. I also cannot tune the threshold on the “training subset”, as both GoogleUrban and PragueParks do not have such a parameter.
2. We are interested more in the rough speed .vs. accuracy trade-off than the precise rankings of the methods — the numbers on your dataset will be different anyway. It is quite likely that those methods, which have a small accuracy gap on the validation set, would switch on the test set — as it happened with DEGENSAC and MAGSAC in our original paper. However, it is very unlikely that method, which performs poorly on the validation set would magically outperform everyone on the test set. Again, see PyRANSAC vs DEGENSAC in the original paper.
Conclusion
The new OpenCV RANSACs are fast and have comparable accuracy, and you can safely pick one of them. I recommend USAC_MAGSAC, as it is the least sensitive to the inlier threshold.
Use proper RANSACs and be happy 🙂

{kind=link}
5K+ Learners
Join Free VLM Bootcamp3 Hours of Learning